Python实现批量下载音效素材详解
目录
- 序言
- 环境/模块/目标
- 1、目标
- 2、开发环境
- 3、模块
- 流程讲解
- 全部代码
序言
作为当代新青年,应该多少会点短视频制作吧?

哈哈,那当代自媒体创作者好了~
制作视频的时候,多少需要一些搞怪的声音?或者奇怪的声音?音乐等等~
一个个下载多慢,我们今天就用python实现批量下载~
环境/模块/目标
1、目标

2、开发环境
兄弟们,刚学Python的话,不要安装一些其它的软件,就装这两个就可以了~
Python 环境 Pycharm 编辑器
3、模块
本次使用的模块主要是这两个
requests # 数据请求模块 re # 正则表达式模块
流程讲解
这次我详细写流程,小白都能看懂的那种,看完大家记得三连,给我一点创作的动力吧 ,嘿嘿~

首先我们打开网址后右键选择检查

选择network ,刷新页面往下滑,会出现一个 page-4 和 page-5 的页面。

这两个页面很多数据是直接在这里有的,我们随便找一个点击播放,然后点击media ,在headers里面会有一个音频文件,就是我标注的下载地址。

可以直接播放也可以直接下载

那想获得这个这个地址怎么搞呢?
我们直接复制这串数字,比如32716 ,然后点击左上角的这个搜索框,搜索一下。
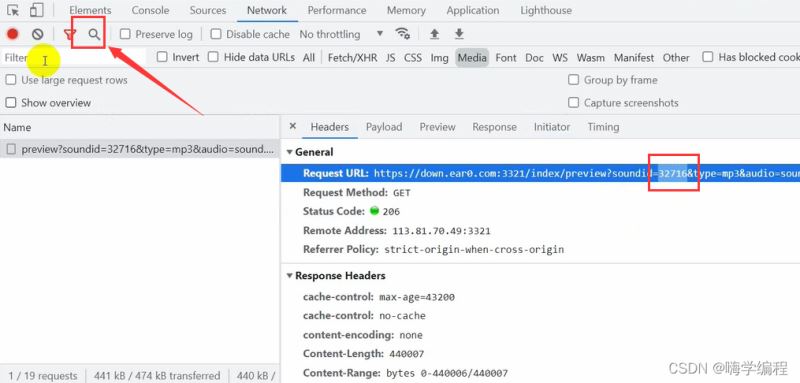
搜索之后我们可以看到page-5这里就有音频的声音链接地址。
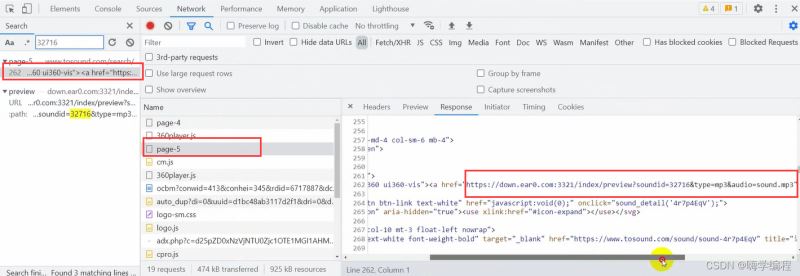
音频标题也在这里可以找到

然后我们点击headers,直接对于这个url地址发送请求。

首先导入requests模块
import requests
url就是刚刚的链接
url = 'https://手动替换一下/search/word-/page-5'
然后我们加一个headers进行伪装
这里直接复制 headers 下面的 user-agent 里面的内容就好了

记得加上引号
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
然后发送请求,打印一下看看结果
response = requests.get(url=url, headers=headers) print(response.text)
打印出来的内容太多了,我们直接在上面搜索MP3,精准定位,它的标题就在mp3文件下面那个链接那里。
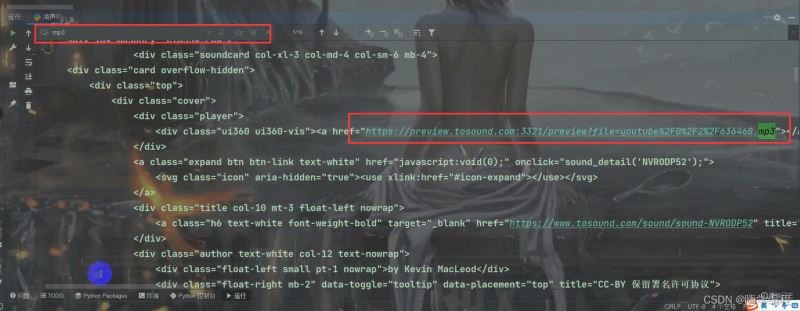
然后我们把它复制过来,用正则去匹配中间这段内容,中间的url用(.*?)代替。
首先导入re模块
import re
刚刚那段内容复制过来,.*?用括号括起来。
从 response.text 里面去匹配,匹配到的内容用play_url_list这个变量接收。
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
然后打印一下看看有没有匹配到内容
print(play_url_list)
可以看到直接匹配到了mp3文件,它包含在一个列表里面。

那我们还需要它的标题名字,同样的复制过来。

还是一样的操作,url和名字都替换为 .*?
从 response.text 里面去匹配,匹配到的内容用name_list这个变量接收。
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
打印一下
print(name_list)
可以看到名字这些数据,都已经获取到了。

遍历一下,把获取到的数据打包到一起,然后一个个提取出来,获取它的一个二进制数据内容,用mp3_content 这个变量接收一下
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
然后直接保存,with open 给它一个文件夹的名字,加上名字,加上 .mp3的后缀,保存方式 mode = wb , 用 f.write 这个变量接收一下 mp3_content
with open('音效\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
这里咱们没有写自动创建文件夹, 所以需要手动创建一下文件夹,然后把你命名的名字写入进来。
然后我们打印一下,看看结果。
print(name)

相关的数据内容就保存在你创建的文件夹了

注:所有的url大家自己手动替换一下,我这里把它们删了,不然会误杀
全部代码
import requests
import re
url = 'https://这里大家自己替换一下/search/word-/page-5'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
print(play_url_list)
print(name_list)
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
with open('音效\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
print(name)
到此这篇关于Python实现批量下载音效素材详解的文章就介绍到这了,更多相关Python下载音效素材内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何基于Python批量下载音乐
这篇文章主要介绍了如何基于Python批量下载音乐,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 音乐是生活的调剂品,目前很多的音乐只能播放不能下载.生为技术员的我们,怎么甘心呢? 知识点: requests 正则表达式 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 第三方库: requests parsel 网页分析 目标站点:http://music.taihe.com/search?ke
-
基于Python实现下载网易音乐代码实例
代码如下 # 爬取网易音乐 import requests from bs4 import BeautifulSoup import urllib.request headers = {"origin": "https://music.163.com", "referer": "https://music.163.com/", "user-agent": "Mozilla/5.0 (Windows
-

教你用Python下载抖音无水印视频
一.获取抖音视频连接 得到如下信息: "5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/ 复制此链接,打开Dou音搜索,直接观看视频!" 通过正则取到信息中的地址: share_url='5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
python爬取音频下载的示例代码
抓取"xmly"鬼故事音频 import json # 在这个url,音频链接为JSON动态生成,所以用到了json模块 import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36" } # 请求网页
-
Python爬虫之批量下载喜马拉雅音频
一.解析网站 1.1 获取音频地址 在喜马拉雅网站上,随便点开一个音频,打开"开发者工具",再点击播放按钮,可以看到出现了多个请求: 经过排查,发现可疑url: 查看它的响应信息,发现音频地址就在里面: 接下来,解析这个返回音频地址的url: https://www.ximalaya.com/revision/play/v1/audio?id=348451879&ptype=1 发现url中的id参数就决定了返回的音频地址,而id参数是音频的id号. 1.2 解析专栏网页 我们
-
基于Python爬取素材网站音频文件
基本环境配置 python 3.6 pycharm requests parsel 相关模块pip安装即可 目标网页 请求网页 import requests url = 'https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Ch
-
Python实现批量下载音效素材详解
目录 序言 环境/模块/目标 1.目标 2.开发环境 3.模块 流程讲解 全部代码 序言 作为当代新青年,应该多少会点短视频制作吧? 哈哈,那当代自媒体创作者好了~ 制作视频的时候,多少需要一些搞怪的声音?或者奇怪的声音?音乐等等~ 一个个下载多慢,我们今天就用python实现批量下载~ 环境/模块/目标 1.目标 2.开发环境 兄弟们,刚学Python的话,不要安装一些其它的软件,就装这两个就可以了~ Python 环境 Pycharm 编辑器 3.模块 本次使用的模块主要是这两个 reque
-
Python如何急速下载第三方库详解
前言 pip 是一个现代的,通用的 Python 包管理工具 ,是一个安装第三方 库必备的工具,提供了对Python 包的查找.下载.安装.卸载的功能.但是在国内使用有很多因素的限制,一个3.4M的库安装都需要几分钟的时间,而且有时还安装失败.那有没有一个可以极速安装第三方库的方法呢!答案是有的,这是小编经常用来安装第三方库的一种方法,拒绝 pip install 库名 方法如下: 首先,用Windows+R打开运行,输入cmd 按'确定' 然后在cmd界面输入 pip install -i h
-
JS实现单个或多个文件批量下载的方法详解
目录 前言 单个文件Download 方案一:location.href or window.open 方案二:通过a标签的download属性 方案三:API请求 多个文件批量Download 方案一:按单个文件download方式,循环依次下载 方案二:前端打包成zip download 方案三:后端压缩成zip,然后以文件流url形式,前端调用download 总结 前言 在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST.url不是
-
对python中的six.moves模块的下载函数urlretrieve详解
实验环境:windows 7,anaconda 3(python 3.5),tensorflow(gpu/cpu) 函数介绍:所用函数为six.moves下的urllib中的函数,调用如下urllib.request.urlretrieve(url,[filepath,[recall_func,[data]]]).简单介绍一下,url是必填的指的是下载地址,filepath指的是保存的本地地址,recall_func指的是回调函数,下载过程中会调用可以用来显示下载进度. 实验代码:以下载cifa
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
python搜索指定类型文件以及批量移动文件程序详解
目录 搜索文件并移动的python程序 1.示例文件及路径准备 2.代码示例 3.命令行写法 总结 搜索文件并移动的python程序 使用python写一个程序,其功能满足:可以搜索指定目录下的某类型的文件,并可以移动到指定的目录. 1.示例文件及路径准备 作为示例,在D盘中放一个名为pic1的文件夹,在该文件夹中放入两个png图片,并在pic1内再创建一个文件夹,里边也随便放两张png图片.如图所示. 在D盘的ABC文件夹中,创建一个名为pic2的文件夹.
-
Python Flask实现图片上传与下载的示例详解
目录 1.效果预览 2.新增逻辑概览 3.tuchuang.py 逻辑介绍 3.1 图片上传 3.2 图片合法检查 3.3 图片下载 4.__init__.py 逻辑介绍 5.upload.html 介绍 5.1 upload Jinja 模板介绍 5.2 upload css 介绍(虚线框) 5.3 upload js 介绍(拖拽) 1.效果预览 我们基于 Flask 官方指导工程,增加一个图片拖拽上传功能,效果如下: 2.新增逻辑概览 我们在官方指导工程上进行增加代码,改动如下: 由于 fl
-
Python实现邮件自动下载的示例详解
开始码代码之前,我们先来了解一下三种邮件服务协议: 1.SMTP协议 SMTP(Simple Mail Transfer Protocol),即简单邮件传输协议.相当于中转站,将邮件发送到客户端. 2.POP3协议 POP3(Post Office Protocol 3),即邮局协议的第3个版本,是电子邮件的第一个离线协议标准.该协议把邮件下载到本地计算机,不与服务器同步,缺点是更易丢失邮件或多次下载相同的邮件. 3.IMAP协议 IMAP(Internet Mail Access Protoc
-
Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
Python实现视频转换为字符画详解
上次写了个华强买瓜字符视频的帖子,下面有人问如何保存,所以这次就写一个能将字符画视频保存下来的帖子,然而时不待我,华强纪元已经结束,现在是穿山甲的时代了. 首先读取视频,并转为字符.视频是从B站下载的,地址<激战江南>穿山甲名场面. 由于B站直接下载的视频为flv格式,而imageio并不支持,尽管可以用opencv来读取,但相比之下,用ffmepg转个码也不复杂,这样可以最大限度地利用华强买瓜的代码. 另外,视频素材过长不适合代码演示,所以从第2:10进行截取15s. 在命令行中输入 >