Java中详细解析Map接口
目录
- Map详解:
- Map基本操作:
- hashMap原理:
- Put方法:
- Get方法:
- Map的遍历:
- TreeMap
- LinkedHashMap:
- 对比下Hashmap、Hashtable和ConcurrentHashmap:
- 总结
Map详解:
先看图,便于宏观了解Map的地位。

Map接口中键和值一一映射. 可以通过键来获取值。
- 给定一个键和一个值,你可以将该值存储在一个Map对象. 之后,你可以通过键来访问对应的值。
- 当访问的值不存在的时候,方法就会抛出一个NoSuchElementException异常.
- 当对象的类型和Map里元素类型不兼容的时候,就会抛出一个 ClassCastException异常。
- 当在不允许使用Null对象的Map中使用Null对象,会抛出一个NullPointerException 异常。
- 当尝试修改一个只读的Map时,会抛出一个UnsupportedOperationException异常。
Map基本操作:
Map 初始化
Map<String, String> map = new HashMap<String, String>();
插入元素
map.put("key1", "value1");
获取元素
map.get("key1")
移除元素
map.remove("key1");
清空map
map.clear();
hashMap原理:
hashMap是由数组和链表这两个结构来存储数据。
数组:存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);寻址容易,插入和删除困难;
链表:存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N);寻址困难,插入和删除容易。
hashMap则结合了两者的优点,既满足了寻址,又满足了操作,为什么呢?关键在于它的存储结构。
它底层是一个数组,数组元素就是一个链表形式,见下图:
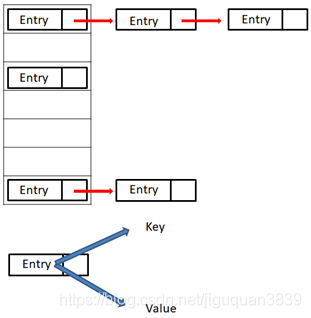
Entry: 存储键值对。
Map类在设计时提供了一个静态修饰接口Entry。Entry将键值对的对应关系封装成了键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对对象中获取相应的键与值。之所以被修饰成静态是为了可以用类名直接调用。

每次初始化HashMap都会构造一个table数组,而table数组的元素为Entry节点,它里面包含了键key,值value,下一个节点next,以及hash值。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
查看hashMap的API发现,它有4个构造函数:

1、构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
2、指定初始容量和默认加载因子 (0.75) 的空 HashMap。
3、指定初始容量和默认加载因子的空HashMap。
4、构造一个映射关系与指定Map相同的新HashMap。
注意:HashMap使用的是懒加载,构造完HashMap对象后,只要不进行put方法插入元素之前,HashMap并不会去初始化或者扩容table。
Put方法:
首先判断是否是空数组(table == EMPTY_TABLE),如果是,开始初始化HashMap的table数据结构,然后执行扩容函数,如果未指定容量,默认是大小为16的表,然后根据加载因子计算临界值。什么是加载因子呢?hashMap的大小是一定的,如果不够存储了肯定要扩容,那么扩容的依据是什么呢,什么时候确定要扩容了呢?这个时候就需要引入加载因子这个概念,我们假使依旧使用默认大小16,加载因子0.75,那么当hashMap的size大于12(16*0.75=12)的时候,那么就会进行扩容。
回来说put方法,如果key是null,调用putForNullKey方法,保存null与key,这是HashMap允许为null的原因。然后计算hash值和用indexFor计算数据存在的位置,然后从i出开始迭代e,找到 key 保存的位置。
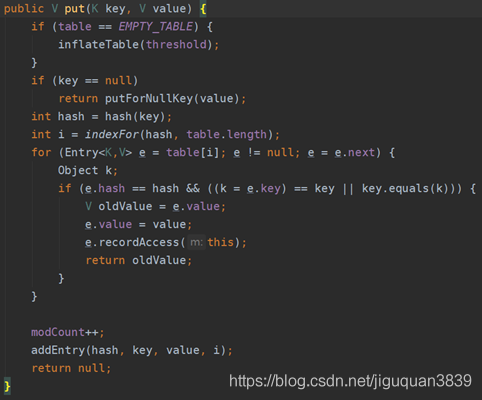
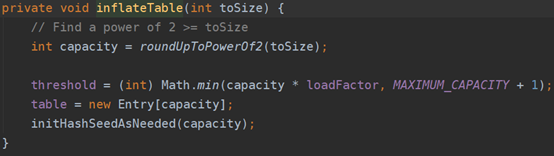
上面说到如果数组扩容,那么每次要怎么扩容呢?

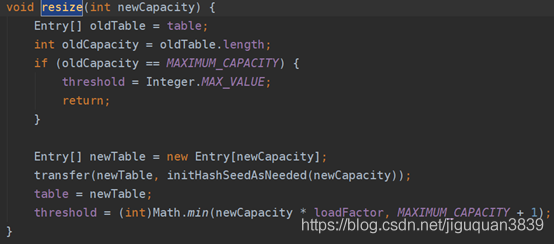
当size大于等于某一个阈值thresholdde时候且该table并不是一个空table,因为size 已经大于等于阈值了,说明Entry数量较多,哈希冲突严重,那么若该Entry对应的桶不是一个空桶,这个Entry的加入必然会把原来的链表拉得更长,因此需要扩容;若对应的桶是一个空桶,那么此时没有必要扩容。如果扩容,table会扩容为原来的两倍,直到达到数组的最大长度1<<30(2的30次方),如果size大于这个值,那么就直接修改为Integer.MAX_VALUE。扩容后的元素hash值对应的新的桶位置,然后在指定的桶位置上,创建一个新的Entry。
这里需要说明的是,hashmap是可以存放key和value均为null的,存放在table[0]的位置,此时使用put方法在添加元素的时候,如果在table[0]中已经存入key为null的元素则给null赋上新的value值并返回后面的值,否则则初始化null的元素,存入put里面存放的值。
public static void main(String[] args) {
HashMap hashMap = new HashMap();
hashMap.put(null, null);
System.out.println(hashMap.get(null));
Integer a = (Integer) hashMap.put(null, 1);
System.out.println(a);
System.out.println(hashMap.get(null));
}
输出为:
null
null
1
Get方法:
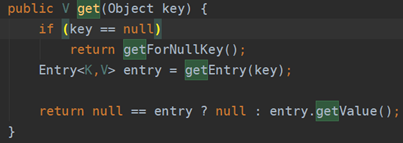
Get比较好理解,判断key是不是null,如果是,返回getForNullKey的函数返回值,如果不是,则在table中去找。
Remove方法:
判断,如果hashMap的size是0,返回null;找到需要移除的元素的前一个节点,然后把前驱节点的next指向删除节点的next节点,此时当前节点没有任何引用指向,它在程序结束之后就会被gc回收。
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
Map的遍历:
map这里可以用增强for和迭代器两种方式遍历:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, String> sets = new HashMap<>();
sets.put("username", "value1");
sets.put("password", "value2");
sets.put("key3", "value3");
sets.put("key4", "value4");
sets.put(null,null);
// 增强for循环 =========== keySet ===================
for (String s : sets.keySet()) {
System.out.println(s + ".." + sets.get(s));
}
//================== entrySet ======================
for (Map.Entry<String, String> m : sets.entrySet()) {
System.out.println(m.getKey() + ".." + m.getValue());
}
// 迭代器 ================ keySet ===================
Iterator it = sets.keySet().iterator();
while (it.hasNext()) {
String key = (String) it.next();
System.out.println(key + ".." + sets.get(key));
}
//================== entrySet ======================
Iterator<Map.Entry<String, String>> iterator = sets.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> m = iterator.next();
System.out.println(m.getKey() + ".." + m.getValue());
}
}
}
TreeMap
这里简要介绍下:TreeMap 是一个有序的key-value集合,继承于AbstractMap,它是通过红黑树实现的。TreeMap 实现了NavigableMap接口,实现了Cloneable接口,实现了java.io.Serializable接口。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它有五个特点如下:
性质1:节点是红色或黑色。
性质2:根节点是黑色。
性质3:每个叶节点(NIL节点,空节点)是黑色的。
性质4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)。
性质5:从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
详细了解请点击。
LinkedHashMap:
HashMap是无序的,只要不涉及线程安全问题,Map基本都可以使用HashMap。如果我们期待一个有序的Map,这个时候,LinkedHashMap就派上用场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序,该迭代顺序可以是插入顺序或者是访问顺序。那么是如何维护的呢,首先参考HashMap的存储结构,将其中的Entry元素增加一个pre指针和一个next指针,这样,根据插入元素的顺序将各个元素依次连接起来,这样LinkedHashMap就保证了元素的顺序。
继承自HashMap,实现了Map接口,LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时(即按访问顺序排序),先将当前节点从链表中移除,然后再将当前节点插入到链表尾部。
实现LRU缓存:
LinkedHashMap和HashMap+LinkedList的操作都是类似的,LRU缓存是我最近看到一个很巧妙的东西,所以推荐大家看一下这篇文章。
对比下Hashmap、Hashtable和ConcurrentHashmap:
第一、Hashmap是线程不安全的,Hashtable和ConcurrentHashMap是线程安全的,在Hashtable中使用了关键字synchronized修饰,加上了同步锁;ConcurrentHashMap在JDK1.7中采用了锁分离的技术,每一个Segment都独立上锁,保证了并发的安全性;每一个Segment元素存储的是HashEntry数组+ 链表,Segment的大小是一开始就确定的,后期不能再进行扩容,但是单个Segment里面的数组是可以扩容的。
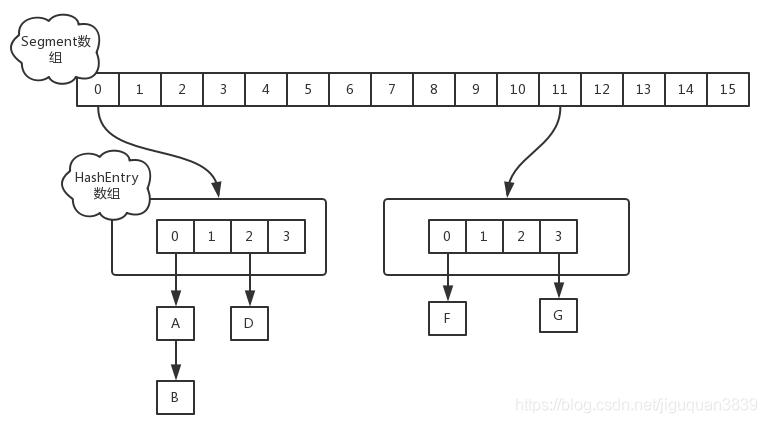
但是在JDK1.8上则摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,如下图所示,并发控制使用Synchronized和CAS来操作,每一个Node节点都是用volatile修饰的,整个看起来就像是优化过且线程安全的HashMap。

第二、Hashmap是可以存放key和value均为null的,存放在table[0]的位置,此时使用put方法在添加元素的时候,如果在table[0]中已经存入key为null的元素则给null赋上新的value值并返回后面的值,否则则初始化null的元素,存入put里面存放的值。Hashtable和ConcurrentHashMap是不可以存放null的key或者value的,原因和并发状态下的操作有关,当在并发状态下执行无法分辨是key没找到的null还是有key值为null,这在多线程里面是模糊不清的,所以不允许put、get为null的元素,如果强行操作就会报空指针异常。
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Java源码解析之超级接口Map
前言 我们在前面说到的无论是链表还是数组,都有自己的优缺点,数组查询速度很快而插入很慢,链表在插入时表现优秀但查询无力.哈希表则整合了数组与链表的优点,能在插入和查找等方面都有不错的速度.我们之后要分析的HashMap就是基于哈希表实现的,不过在JDK1.8中还引入了红黑树,其性能进一步提升了. 今天我们来说一说超级接口Map. 一.接口Map Map是基于Key-Value的数据格式,并且key值不能重复,每个key对应的value值唯一.Map的key也可以为null,但不可重复. 在看Ma
-
Java Map接口及其实现类原理解析
Map接口 Map提供了一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value: Map中的键值对以Entry类型的对象实例形式存在: 建(key值)不可重复,value值可以重复,一个value值可以和很多key值形成对应关系,每个建最多只能映射到一个值. Map支持泛型,形式如:Map<K,V> Map中使用put(K key,V value)方法添加 Map接口中定义的常用方法 具体使用在实现类中讨论 int size();//获取Ma
-
Java中Map集合(接口)的基本方法程序演示
本文实例为大家分享了Java中Map集合的基本方法程序演示的具体代码,供大家参考,具体内容如下 package pack02; import java.util.*; public class MapDemo { public static void main(String[] args) { //定义一个Map接口类型的引用,指向HashMap类型的对象 Map<String,String> ma = new HashMap<String, String>(); ma.put(&
-
浅析Java8 中 Map 接口的新方法
我们提一个需求:给定一个 List<String> ,统计每个元素出现的所有位置. 比如,给定 list: ["a", "b", "b", "c", "c", "c", "d", "d", "d", "f", "f", "g"] ,那么应该返回: a : [
-

Java使用Semaphore对单接口进行限流
目录 一.实战说明 1.1 效果说明 1.2 核心知识点 二. 环境搭建 三.限流演示 3.1 并发请求工具 3.2 效果示例图 一.实战说明 1.1 效果说明 本篇主要讲如何使用Semaphore对单接口进行限流,例如有如下场景 a. A系统的有a接口主要给B系统调用,现在希望对B系统进行限流,例如处理峰值在100,超过100的请求快速失败 b. 接口作为总闸入口,希望限制所有外来访问,例如某个房间只能同时100个玩家在线,只有前面的处理完后面的才能继续请求 c. 其他类型场景,也就是资源固定
-
Java中详细解析Map接口
目录 Map详解: Map基本操作: hashMap原理: Put方法: Get方法: Map的遍历: TreeMap LinkedHashMap: 对比下Hashmap.Hashtable和ConcurrentHashmap: 总结 Map详解: 先看图,便于宏观了解Map的地位. Map接口中键和值一一映射. 可以通过键来获取值. 给定一个键和一个值,你可以将该值存储在一个Map对象. 之后,你可以通过键来访问对应的值. 当访问的值不存在的时候,方法就会抛出一个NoSuchElementEx
-
详解Java中list,set,map的遍历与增强for循环
详解Java中list,set,map的遍历与增强for循环 Java集合类可分为三大块,分别是从Collection接口延伸出的List.Set和以键值对形式作存储的Map类型集合. 关于增强for循环,需要注意的是,使用增强for循环无法访问数组下标值,对于集合的遍历其内部采用的也是Iterator的相关方法.如果只做简单遍历读取,增强for循环确实减轻不少的代码量. 集合概念: 1.作用:用于存放对象 2.相当于一个容器,里面包含着一组对象,其中的每个对象作为集合的一个元素出现 3.jav
-
详解Java中Comparable和Comparator接口的区别
详解Java中Comparable和Comparator接口的区别 本文要来详细分析一下Java中Comparable和Comparator接口的区别,两者都有比较的功能,那么究竟有什么区别呢,感兴趣的Java开发者继续看下去吧. Comparable 简介 Comparable 是排序接口. 若一个类实现了Comparable接口,就意味着"该类支持排序". 即然实现Comparable接口的类支持排序,假设现在存在"实现Comparable接口的类的对象的List列表(
-
java中的内部类内部接口用法说明
简介 一般来说,我们创建类和接口的时候都是一个类一个文件,一个接口一个文件,但有时候为了方便或者某些特殊的原因,java并不介意在一个文件中写多个类和多个接口,这就有了我们今天要讲的内部类和内部接口. 内部类 先讲内部类,内部类就是在类中定义的类.类中的类可以看做是类的一个属性,一个属性可以是static也可以是非static的.而内部类也可以定义在类的方法中,再加上匿名类,总共有5种内部类. 静态内部类 我们在class内部定义一个static的class,如下所示: @Slf4j publi
-
Java源码解析之接口Collection
一.图示 二.方法定义 我们先想一想,公司如果要我们自己去封装一些操作数组或者链表的工具类,我么需要封装哪些功能呢?不妨就是统计其 大小,增删改查.清空或者是查看否含有某条数据等等.而collection接口就是把这些通常操作提取出来,使其更全面.更通用,那现在我们就来看看其源码都有哪些方法. //返回集合的长度,如果长度大于Integer.MAX_VALUE,返回Integer.MAX_VALUE int size(); //如果集合元素总数为0,返回true boolean isEmpty(
-
Java源码解析之接口List
前言 List接口是Collection接口的三大接口之一,其中的数据可以通过位置检索,用户可以在指定位置插入数据.List的数据可以为空,可以重复.我们来看看api文档是怎么说的: 一.List特有的方法 我们这里就只关注和Collection不同的方法,主要有以下这些: //在指定位置,将指定的集合插入到当前的集合中 boolean addAll(int index, Collection<? extends E> c); //这是一个默认实现的方法,会通过Iterator的方式对每个元素
-
Java中常用解析工具jackson及fastjson的使用
一.maven安装jackson依赖 <!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version
-
Java超详细透彻讲解接口
目录 一.引入 二.理解 三.使用 四.应用-代理模式(Proxy) 1. 应用场景 2. 分类 3. 代码演示 五.接口和抽象类之间的对比 六.经典题目(排错) 一.引入 一方面,有时必须从几个类中派生出一个子类,继承它们所有的属性和方法.但是,Java不支持多重继承.有了接口,就可以得到多重继承的效果. 另一方面,有时必须从几个类中抽取出一些共同的行为特征,而它们之间又没有is-a的关系,仅仅是具有相同的行为特征而已.例如:鼠标.键盘.打印机.扫描仪.摄像头.充电器.MP3机.手机.数码相机
-
Java中List转Map List实现的几种姿势
今天介绍一个实用的小知识点,如何将List转为Map<Object, List<Object>> 1. 基本写法 最开始介绍的当然是最常见.最直观的写法,当然也是任何限制的写法 // 比如将下面的列表,按照字符串长度进行分组 List<String> list = new ArrayList<>(); list.add("hello"); list.add("word"); list.add("come&qu
-
一文掌握Java中List和Set接口的基本使用
目录 集合的概念 List接口 泛型 Set接口 List和set的区别 基本概念的区别 使用场景 集合的概念 是一个工具类,作用为存储多个数据,通常用于替代数组 集合的特点 只能存放Object对象 只能存放引用类型 不能存放接口,只能存放接口实现类对象 来自java.util包 List接口 List的存储特点 有序.有下标.元素可以重复 常用实现类 1.ArrayList 最常用 JDK1.2 底层数组实现 查询快.增删慢 线程不安全,效率高 2.一般不用 JDK1.2 底层链表实现 增删