总结分析python数据化运营关联规则
目录
- 内容介绍
- 一般应用场景
- 关联规则实现
- 关联规则应用举例
内容介绍
以 Python 使用 关联规则 简单举例应用关联规则分析。
关联规则 也被称为购物篮分析,用于分析数据集各项之间的关联关系。
一般应用场景
关联规则分析:最早的案例啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
后来也引申到不同的应用场景,分析变量与变量之间的关系情况分析。总体来说分析的都是类别变量。
关联规则实现
import pandas as pd
from apriori_new import * #导入自行编写的apriori函数
import time #导入时间库用来计算用时
import re
import random
import pandas as pd
# 自定义关联规则算法
def connect_string(x, ms):
x = list(map(lambda i: sorted(i.split(ms)), x))
l = len(x[0])
r = []
# 生成二项集
for i in range(len(x)):
for j in range(i, len(x)):
# if x[i][l-1] != x[j][l-1]:
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][
l - 1]: # 判断数字和字母异同,初次取字母数字不全相同(即不同症状(字母),或同一证型程度不同(数字))
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
# 寻找关联规则的函数
def find_rule(d, support, confidence, ms=u'--'):
result = pd.DataFrame(index=['support', 'confidence']) # 定义输出结果
support_series = 1.0 * d.sum() / len(d) # 支持度序列
column = list(support_series[support_series > support].index) # 初步根据支持度筛选,符合条件支持度,共 276个index证型
k = 0
while len(column) > 1: # 随着项集元素增多 可计算的column(满足条件支持度的index)会被穷尽,随着证型增多,之间的关系会越来越不明显,(同时发生可能性是小概率了)
k = k + 1
print(u'\n正在进行第%s次搜索...' % k)
column = connect_string(column, ms)
print(u'数目:%s...' % len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支持度的计算函数
len(d)
# 创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
# 依次对column每个元素(如[['A1', 'A2'], ['A1', 'A3']]中的['A1', 'A2'])运算,计算data_model_中对应该行的乘积,930个,若['A1', 'A2']二者同时发生为1则此行积为1
d_2 = pd.DataFrame(list(map(sf, column)),index=[ms.join(i) for i in column]).T # list(map(sf,column)) 276X930 index 276
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d) # 计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) # 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: # 遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms) # 由'A1--B1' 转化为 ['A1', 'B1']
for j in range(len(i)): #
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) # 定义置信度序列
for i in column2: # 计算置信度序列 如i为['B1', 'A1']
# i置信度计算:i的支持度除以第一个证型的支持度,表示第一个发生第二个发生的概率
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index: # 置信度筛选
result[i] = 0.0 # B1--A1 0.330409 A1--B1 0.470833,绝大部分是要剔除掉的,初次全剔除
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(by=['confidence', 'support'],ascending=False) # 结果整理,输出,先按confidence升序,再在confidence内部按support升序,默认升序,此处降序
return result
关联规则应用举例
sku_list = [
'0000001','0000002','0000003','0000004','0000005',
'0000006','0000007','0000008','0000009','0000010',
'0000011','0000012','0000013','0000014','0000015',
'0000016','0000017','0000018','0000019','0000020',
'A0000001','A0000002','A0000003','A0000004','A0000005',
'A0000006','A0000007','A0000008','A0000009','A0000010',
'A0000011','A0000012','A0000013','A0000014','A0000015',
'A0000016','A0000017','A0000018','A0000019','A0000020',
]
# 随机抽取数据生成列表
mat = [ random.sample(sku_list, random.randint(2,5)) for i in range(100)]
data = pd.DataFrame(mat,columns=["A","B","C","D","E"])
data = pd.get_dummies(data) # 转换类别变量矩阵
data = data.fillna(0)

- 支持度:表示项集{X,Y}在总项集里出现的概率。
- 置信度:表示在先决条件X发生的情况下,由关联规则”X→Y“推出Y的概率。表示在发生X的项集中,同时会发生Y的可能性,即X和Y同时发生的个数占仅仅X发生个数的比例。
support = 0.01 #最小支持度 confidence = 0.05 #最小置信度 ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符 start = time.clock() #计时开始 print(u'\n开始搜索关联规则...') print(find_rule(data, support, confidence, ms)) end = time.clock() #计时结束 print(u'\n搜索完成,用时:%0.2f秒' %(end-start))
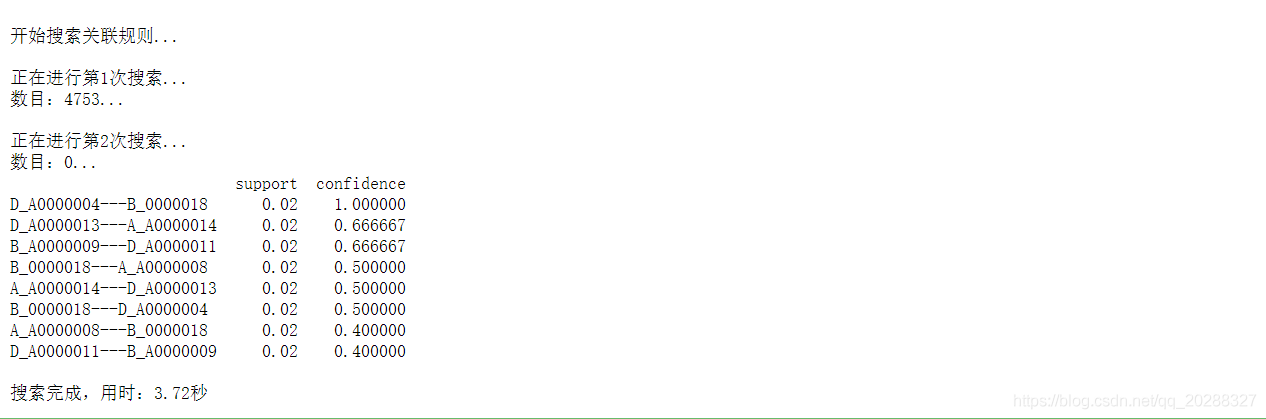
以上就是总结分析python数据化运营关联规则的详细内容,更多关于python数据化运营关联规则的资料请关注我们其它相关文章!
相关推荐
-
python 实现关联规则算法Apriori的示例
首先导入包含apriori算法的mlxtend库, pip install mlxtend 调用apriori进行关联规则分析,具体代码如下,其中数据集选取本博客 "机器学习算法--关联规则" 中的例子,可进行参考,设置最小支持度(min_support)为0.4,最小置信度(min_threshold)为0.1, 最小提升度(lift)为1.0,对数据集进行关联规则分析, from mlxtend.preprocessing import TransactionEncoder fro
-

python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
详解Python 关联规则分析
1. 关联规则 大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品. 不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules. 关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系. 1
-
python数据化运营的重要意义
python数据化运营 数据化运营的核心是运营,所有数据工作都是围绕运营工作链条展开的,逐步强化数据对于运营工作的驱动作用.数据化运营的价值体现在对运营的辅助.提升和优化上,甚至某些运营工作已经逐步数字化.自动化.智能化. 具体来说,数据化运营的意义如下: 1)提高运营决策效率.在信息瞬息万变的时代,抓住转瞬即逝的机会对企业而言至关重要.决策效率越高意味着可以在更短的时间内做出决策,从而跟上甚至领先竞争对手.数据化运营可使辅助决策更便捷,使数据智能引发主动决策思考,从而提前预判决策时机,并提高决
-
总结分析python数据化运营关联规则
目录 内容介绍 一般应用场景 关联规则实现 关联规则应用举例 内容介绍 以 Python 使用 关联规则 简单举例应用关联规则分析. 关联规则 也被称为购物篮分析,用于分析数据集各项之间的关联关系. 一般应用场景 关联规则分析:最早的案例啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品.
-
回归预测分析python数据化运营线性回归总结
目录 内容介绍 一般应用场景 线性回归的常用方法 线性回归实现 线性回归评估指标 线性回归效果可视化 数据预测 内容介绍 以 Python 使用 线性回归 简单举例应用介绍回归分析. 线性回归是利用线性的方法,模拟因变量与一个或多个自变量之间的关系: 对于模型而言,自变量是输入值,因变量是模型基于自变量的输出值,适用于x和y满足线性关系的数据类型的应用场景. 用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值也随之发生变化. 回归模型正是表示从输入变量到输出变量之
-
分析总结Python数据化运营KMeans聚类
内容介绍 以 Python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析. 聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上). 它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学. 一般应用场景 目标用户的群体分类: 根据运营或商业目的挑选出来的变量,对目标群体进行聚类,将目标群体分成几个有明显
-
Python 数据化运营之KMeans聚类分析总结
目录 Python 数据化运营 1.内容介绍 2.一般应用场景 3.聚类的常见方法 4.Keans聚类实现 5.聚类的评估指标 6.聚类效果可视化 7.数据预测 Python 数据化运营 1.内容介绍 以 Python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析. 聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上).它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机
-
分析Python读取文件时的路径问题
Python在读取文件内容时的路径问题,值得深究一下.我想讨论的重点还是在绝对路径上面.在这之前我们先看一下 1:相对路径 这张图演示了在相对路径下寻找查找指定文件. open('相对路径演示'\'相对路径示例'.txt)打开的是相对当前运行的程序所在目录. 而我当前运行的程序相对位置在桌面. 所以直接print(lines) 可以看到这个结果 2:绝对路径. 绝对路径的查找方法就不演示了,相信每个人都会找到.但是我想讨论的是几个关于路径中的编码问题,相信这对初学者们有很大的帮助. 2.1:你
-
详细分析Python垃圾回收机制
引入 为什么要有垃圾回收机制 Python中的垃圾回收机制简称(GC),我们在程序的运行中会产生大量的变量用于保存数据,而有时候有些变量已经没有用了就需要被清理释放掉该变量所占据的内存空间.在一些较为低级的语言中(比如:C语言,汇编语言)对于内存空间的释放是需要编程人员来手动进行的,这种与底层硬件直接打交道的操作是十分的危险与繁琐的,而基于C语言开发而来的Python为了解决掉这种顾虑则自带了一种垃圾回收机制,从而让开发人员不必过分担心内存的使用情况而可以全身心的投入到开发中去. >>>
-
详细分析Python可变对象和不可变对象
在 Python 中一切都可以看作为对象.每个对象都有各自的 id, type 和 value. id: 当一个对象被创建后,它的 id 就不会在改变,这里的 id 其实就是对象在内存中的地址,可以使用 id() 去查看对象在内存中地址. type: 和 id 一样当对象呗创建之后,它的 type 也不能再被改变,type 决定了该对象所能够支持的操作 value: 对象的值 一个对象可变与否就在于 value 值是否支持改变. 不可变对象 常见的不可变对象(immutable objects)
-
详细分析Python collections工具库
今天为大家介绍Python当中一个很好用也是很基础的工具库,叫做collections. collection在英文当中有容器的意思,所以顾名思义,这是一个容器的集合.这个库当中的容器很多,有一些不是很常用,本篇文章选择了其中最常用的几个,一起介绍给大家. defaultdict defaultdict可以说是这个库当中使用最简单的一个,并且它的定义也很简单,我们从名称基本上就能看得出来.它解决的是我们使用dict当中最常见的问题,就是key为空的情况. 在正常情况下,我们在dict中获取元素的
-
使用pycallgraph分析python代码函数调用流程以及框架解析
技术背景 在上一篇博客中,我们介绍了使用量子计算模拟器ProjectQ去生成一个随机数,也介绍了随机数的应用场景等.但是有些时候我们希望可以打开这里面实现的原理,去看看在产生随机数的过程中经历了哪些运算,调用了哪些模块.只有梳理清楚这些相关的内容,我们才能够更好的使用这个产生随机数的功能.这里我们就引入一个工具pycallgraph,可以根据执行的代码,给出这些代码背后所封装和调用的所有函数.类的关系图,让我们一起来了解下这个工具的安装和使用方法. Manjaro Linux平台安装graphv