mysql过滤复制思路详解
目录
- mysql过滤复制
- 主库上实现
- 从库上实现
- 一些问题
mysql过滤复制
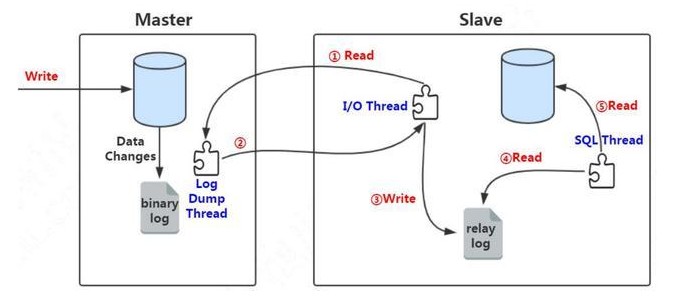
两种思路:
- 主库的binlog上实现(不推荐,尽量保证主库binlog完整)
- 从库的sql线程上实现
所以主从过滤复制尽量不用,要用的也仅仅在从库上使用,因为要尽可能保证binlog的完整性
主库上实现
在Master 端为保证二进制日志的完整, 不使用二进制日志过滤。
主库配置参数:
#配置文件中添加 binlog-do-db=db_name #定义白名单,仅将制定数据库的相关操作记入二进制日志。如果主数据库崩溃,那么仅仅之恢复指定数据库的内容,不建议在主服务器端使用,这样导致日志不完整。 binlog-ignore-db=db_name #定义黑名单, 定义ignore 的库上发生的写操作将不会记录到二进制日志中
从库上实现
可以下载配置文件中
REPLICATE_DO_DB = (db_list) #过滤复制哪些库 REPLICATE_IGNORE_DB = (db_list) #不复制哪些库 REPLICATE_DO_TABLE = (tbl_list) #过滤表 REPLICATE_IGNORE_TABLE = (tbl_list) #忽略过滤表 REPLICATE_WILD_DO_TABLE = (wild_tbl_list) #根据正则匹配过滤表 REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) #根据正则匹配忽略过滤这些表 REPLICATE_REWRITE_DB = (db_pair_list) #将源数据库的db1发生的语句重写到从库的db2 CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB = ((db1, db2));
语法:
官网语法参考:https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html
CHANGE REPLICATION FILTER filter[, filter][, ...]
filter: {
REPLICATE_DO_DB = (db_list)
| REPLICATE_IGNORE_DB = (db_list)
| REPLICATE_DO_TABLE = (tbl_list)
| REPLICATE_IGNORE_TABLE = (tbl_list)
| REPLICATE_WILD_DO_TABLE = (wild_tbl_list)
| REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list)
| REPLICATE_REWRITE_DB = (db_pair_list)
}
#从库实现过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(db); start slave sql_thread; #取消过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(); start slave sql_thread;
一些问题
主库删除某个表,从库没有这个表,导致从库sql线程关闭
或者主从正常,从库不小心删除某个表,主库随后再删除这个表,从库又会去删除这个不存在的表,报错,导致sql线程退出
解决方法:跳过这一步操作
解决方案:从库sql线程跳过误操作的步骤 stop slave sql_thread; #找到Executed_Gtid_Set执行到19 set gtid_next='94fc1fbe-b7a0-11eb-b0a0-000c2969aba1:20'; 将gtid分配给下一个事务 begin;commit; set gtid_next=automatic; 系统自动分配gtid start slave sql_thread;
到此这篇关于mysql过滤复制思路详解的文章就介绍到这了,更多相关mysql过滤复制 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql 复制过滤重复如何解决
1.replicate_do_db 和 replicate_ignore_db 不要同时出现.容易出现混淆.也是毫无意义的. Replicate_Do_DB: db1 Replicate_Ignore_DB: db2 statement模式: 使用use 语句 use db1;insert into tb1 values (1); use db2;insert into tb2 values (2); 以上在slave上均能正确复制,tb1 有数据,tb2没有数据. 不使用use 语句 inse
-
mysql 如何动态修改复制过滤器
MySQL动态修改复制过滤器 说说今天遇到的问题吧,今天在处理一个业务方的需求,比较变态,我大概描述一下: 1.线上的阿里云rds上面有个游戏的日志库,里面的表都是日表的形式,数据量比较大了,每次备份的时候,都会导致线上的rds报警,报警内容是IO资源占用过多. 2.这个rds上有一个本地的ECS只读从库,这个只读从库会实时同步线上的rds数据库中的数据,这个只读从库供业务方查询使用 3.业务方说这些数据都还有用,只读从库上的数据必须有,线上rds上的数据可以删除,保留两个星期即可. 场景就是这
-

mysql过滤复制思路详解
目录 mysql过滤复制 主库上实现 从库上实现 一些问题 mysql过滤复制 两种思路: 主库的binlog上实现(不推荐,尽量保证主库binlog完整) 从库的sql线程上实现 所以主从过滤复制尽量不用,要用的也仅仅在从库上使用,因为要尽可能保证binlog的完整性 主库上实现 在Master 端为保证二进制日志的完整, 不使用二进制日志过滤. 主库配置参数: #配置文件中添加 binlog-do-db=db_name #定义白名单,仅将制定数据库的相关操作记入二进制日志.如果主数据库崩溃,
-
linux使用mysqldump+expect+crontab实现mysql周期冷备份思路详解
一.遇到的问题 我们使用过mysqldump都知道,使用该命令后,需要我们手动输入 mysql的密码,那么我们就不能够直接在crontab中使用mysqldump实现周期备份.其实我们可以使用expect脚本自动输入密码,从而实现真正的周期备份.如果你不知道什么是expect,建议先请看这篇文章:https://blog.csdn.net/lendsomething/article/details/109066545 二.思路 创建一个utils文件,里面存放shell脚本,包括mysqldum
-
利用pt-heartbeat监控MySQL的复制延迟详解
pt-heartbeat 数据库做主从复制时,复制状态.数据延迟是否正常是非常关键的指标,那么如何对其进行监控呢? pt-heartbeat 是 PERCONA 开发的一个工具集中的一个,专门用来监控MySQL和PostgreSQL的复制延迟. 比较成熟,例如Uber等大型公司都在使用. 下面来话不多说,来一起看看详细的介绍: 监控原理 在 master 中建一个 heartbeat 表,其中有一个 时间戳 字段,pt-heartbeat 会周期性的修改时间戳的值. slave 会复制 hear
-
PHP和MYSQL实现分页导航思路详解
预期效果 思路 通过SQL语句 SELECT * FROM table LIMIT start end 来从MySql数据库 步骤 传入页码p: 根据页码获取数据php->mysql 显示数据+分页条 源码 github 链接 注意点 table,input,button等控件的样式不会继承body,需要重新定义如下 input,label, select,option,textarea,button,fieldset,legend,table{ font-size:18px; FONT-FAM
-
MySQL 复制表详解及实例代码
MySQL 复制表详解 如果我们需要完全的复制MySQL的数据表,包括表的结构,索引,默认值等. 如果仅仅使用CREATE TABLE ... SELECT 命令,是无法实现的. 本章节将为大家介绍如何完整的复制MySQL数据表,步骤如下: 使用 SHOW CREATE TABLE 命令获取创建数据表(CREATE TABLE) 语句,该语句包含了原数据表的结构,索引等. 复制以下命令显示的SQL语句,修改数据表名,并执行SQL语句,通过以上命令 将完全的复制数据表结构. 如果你想复制表的内容,
-
安装mysql8.0.11及修改root密码、连接navicat for mysql的思路详解
1.1. 下载: 官网下载zip包,我下载的是64位的: 下载地址:https://dev.mysql.com/downloads/mysql/ 下载zip的包: 下载后解压:(解压在哪个盘都可以的) 我放在了这里 E:\web\mysql-8.0.11-winx64 ,顺便缩短了文件名,所以为 E:\web\mysql-8.0.11. 1.3. 生成data文件: 以管理员身份运行cmd 程序--输入cmd 找到cmd.exe 右键以管理员身份运行 进入E:\web\mysql-8.0.11\
-
Python使用sql语句对mysql数据库多条件模糊查询的思路详解
def find_worldByName(c_name,continent): print(c_name) print(continent) sql = " SELECT * FROM world WHERE 1=1 " if(c_name!=None): sql=sql+"AND ( c_name LIKE '%"+c_name+"%' )" if(continent!=None): sql=sql+" AND ( continent
-
mysql触发器实时检测一条语句进行备份删除思路详解
问题描述:用户有一个这样一个需求,在一张表里会不时出现 "违规" 字样的字段,需要在出现这个字段的时候,把整行的数据删掉.这是个采集任务,如果发现有"违规"字样的数据,会整点或者什么时间进行统一上报,也无法对源头进行控制让这种数据不生成. 现在需要实现以下需求: 1.实时检测这条数据的产生,发现后删除 2.在删除之前作备份这条数据 解决思路: 需要明确解决思路, 1.首先是如何实时探测删除?询问开发,这条数据的生成方式为insert,就可以做一个当表做插入的时候,然
-
centos 7 部署Thinksns的思路详解
因为Thinksns是PHP项目,我们这里部署需要搭建Apache+mysql+php环境. 1.mysql的安装,这里使用yum安装可以解决很多依赖包的问题.由于centos 7 没有自带mysql的yum源,所以不能直接安装,需要创建yum安装详细教程如下: http://www.cnblogs.com/SoEasyO-O/p/7068156.html 添加好yum源之后运行如下命令: yum install mysql-community-server 根据系统提示下载并安装mysql.
-
Spring整合MyBatis(Maven+MySQL)图文教程详解
一. 使用Maven创建一个Web项目 为了完成Spring4.x与MyBatis3.X的整合更加顺利,先回顾在Maven环境下创建Web项目并使用MyBatis3.X,第一.二点内容多数是回顾过去的内容 . 1.2.点击"File"->"New"->"Other"->输入"Maven",新建一个"Maven Project",如下图所示: 1.2.请勾选"Create a si