详解如何用Python登录豆瓣并爬取影评
目录
- 一、需求背景
- 二、功能描述
- 三、技术方案
- 四、登录豆瓣
- 1.分析豆瓣登录接口
- 2.代码实现登录豆瓣
- 3.保存会话状态
- 4.这个Session对象是我们常说的session吗?
- 五、爬取影评
- 1.分析豆瓣影评接口
- 2.爬取一条影评数据
- 3.影评内容提取
- 4.批量爬取
- 六、分析影评
- 1.使用结巴分词
- 七、总结
上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
我们今天就用requests库来登录豆瓣然后爬取影评为例子,用代码讲解下Cookie的会话状态管理(登录)功能。
此教程仅用于学习,不得商业获利!如有侵害任何公司利益,请告知删除!
一、需求背景
之前猪哥带大家爬取了优酷的弹幕并生成词云图片,发现优酷弹幕的质量并不高,有很多介词和一些无效词,比如:哈哈、啊啊、这些、那些。。。而豆瓣口碑一直不错,有些书或者电影的推荐都很不错,所以我们今天来爬取下豆瓣的影评,然后生成词云,看看效果如何吧!
二、功能描述
我们使用requests库登录豆瓣,然后爬取影评,最后生成词云!
为什么我们之前的案例(京东、优酷等)中不需要登录,而今天爬取豆瓣需要登录呢?那是因为豆瓣在没有登录状态情况下只允许你查看前200条影评,之后就需要登录才能查看,这也算是一种反扒手段!

三、技术方案
我们看下简单的技术方案,大致可以分为三部分:
- 分析豆瓣的登录接口并用requests库实现登录并保存cookie
- 分析豆瓣影评接口实现批量抓取数据
- 使用词云做影评数据分析
方案确定之后我们就开始实际操作吧!
四、登录豆瓣
做爬虫前我们都是先从浏览器开始,使用调试窗口查看url。
1.分析豆瓣登录接口
打开登录页面,然后调出调试窗口,输入用户名和密码,点击登录。
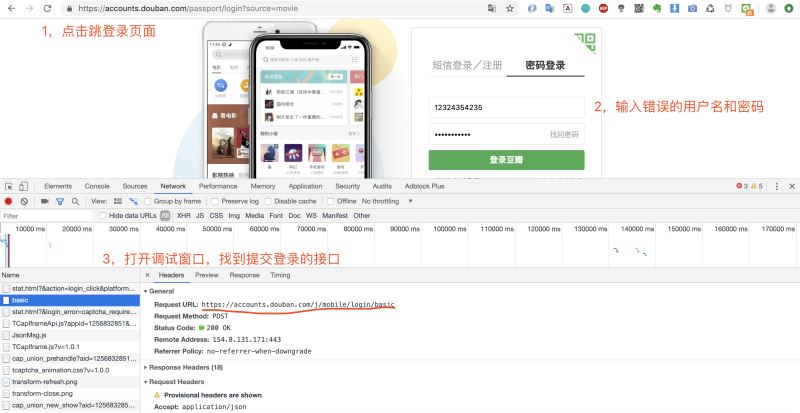
这里猪哥建议输入错误的密码,这样就不会因为页面跳转而捕捉不到请求!上面我们便获取到登录请求的URL:https://accounts.douban.com/j/mobile/login/basic
因为是一个POST请求,所以我们还需要看看请求登录时携带的参数,我们将调试窗口往下拉查看Form Data。

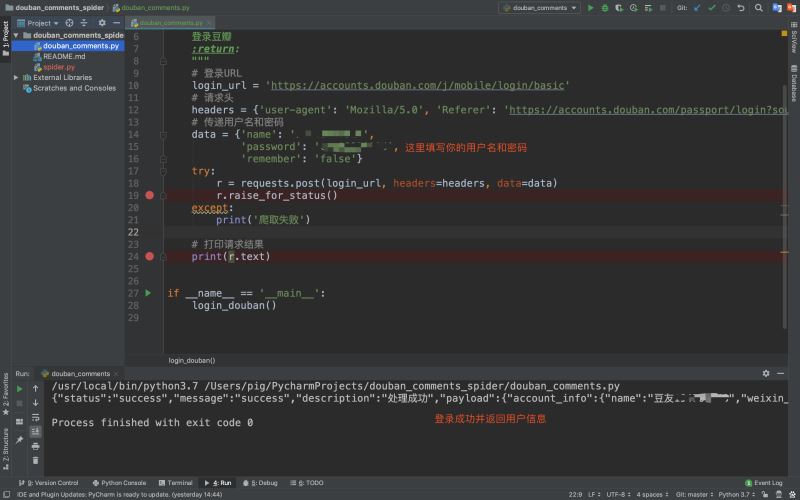
2.代码实现登录豆瓣
得到登录请求URL和参数后,我们就可以来用requests库来写一个登录功能!
3.保存会话状态
上期我们在爬取优酷弹幕的时候我们是复制浏览器中的Cookie到请求头中这来来保存会话状态,但是我们如何让代码自动保存Cookie呢?
也许你见过或者使用过urllib库,它用来保存Cookie的方式如下:
cookie = http.cookiejar.CookieJar() handler = urllib.request.HttpCookieProcessor(cookie) opener = urllib.request.build_opener(handler) opener(url)
但是前面我们介绍requests库的时候就说过:
requests库是一个基于urllib/3的第三方网络库,它的特点是功能强大,API优雅。由上图我们可以看到,对于http客户端python官方文档也推荐我们使用requests库,实际工作中requests库也是使用的比较多的库。
所以今天我们来看看requests库是如何优雅的帮我们自动保存Cookie的?我们来对代码做一点微调,使之能自动保存Cookie维持会话状态!

上述代码中,我们做了两处改动:
- 在最上面增加一行
s = requests.Session(),生成Session对象用来保存Cookie - 发起请求不再是原来的requests对象,而是变成了Session对象
我们可以看到发起请求的对象变成了session对象,它和原来的requests对象发起请求方式一样,只不过它每次请求会自动带上Cookie,所以后面我们都用Session对象来发起请求!
4.这个Session对象是我们常说的session吗?
讲到这里也许有同学会问:requests.Session对象是不是我们常说的session呢?
答案当然不是,我们常说的session是保存在服务端的,而requests.Session对象只是一个用于保存Cookie的对象而已,我们可以看看它的源码介绍
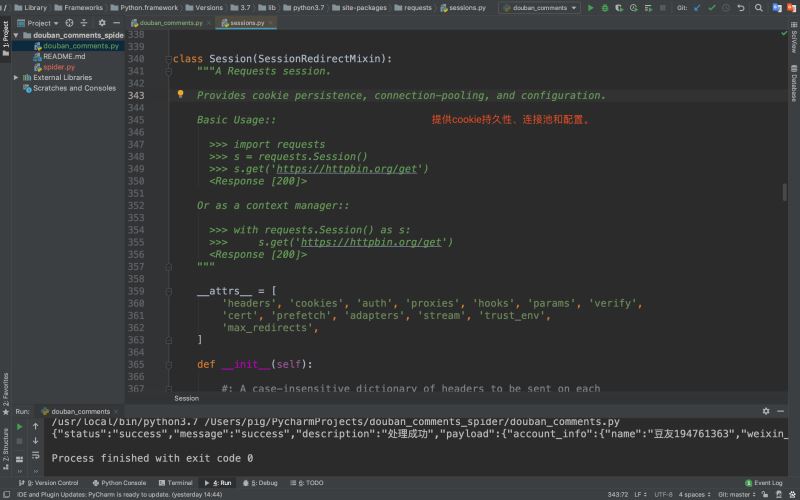
所以大家千万不要将requests.Session对象与session技术搞混了!
五、爬取影评
我们实现了登录和保存会话状态之后,就可以开始干正事啦!
1.分析豆瓣影评接口
首先在豆瓣中找到自己想要分析的电影,这里猪哥选择一部美国电影**《荒野生存》**,因为这部电影是猪哥心中之最,没有之一!
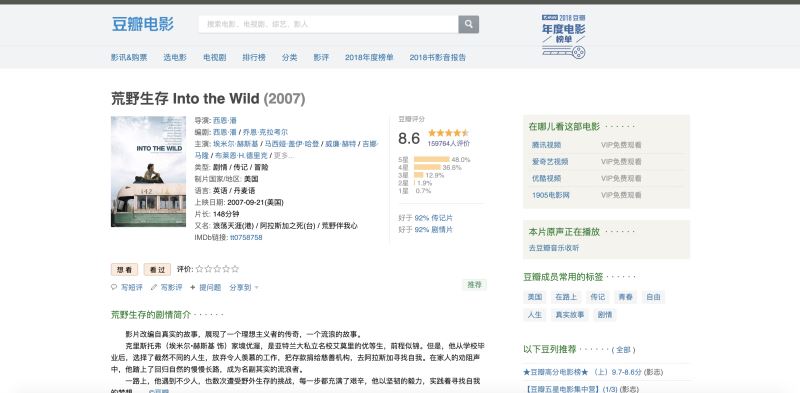
然后下拉找到影评,调出调试窗口,找到加载影评的URL

2.爬取一条影评数据
但是爬取下来的是一个HTML网页数据,我们需要将影评数据提取出来

3.影评内容提取
上图中我们可以看到爬取返回的是html,而影评数据便是嵌套在html标签中,如何提取影评内容呢?
这里我们使用正则表达式来匹配想要的标签内容,当然也有更高级的提取方法,比如使用某些库(比如bs4、xpath等)去解析html提取内容,而且使用库效率也比较高,但这是我们后面的内容,我们今天就用正则来匹配!
我们先来分析下返回html 的网页结构
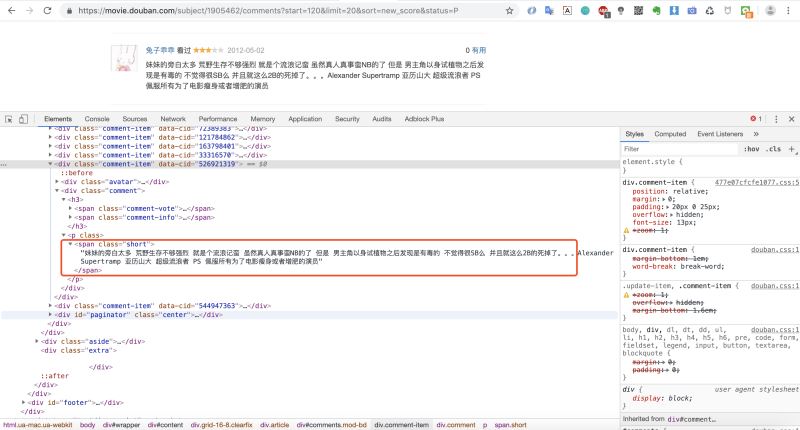
我们发现影评内容都是在<span class="short"></span>这个标签里,那我们 就可以写正则来匹配这个标签里的内容啦!
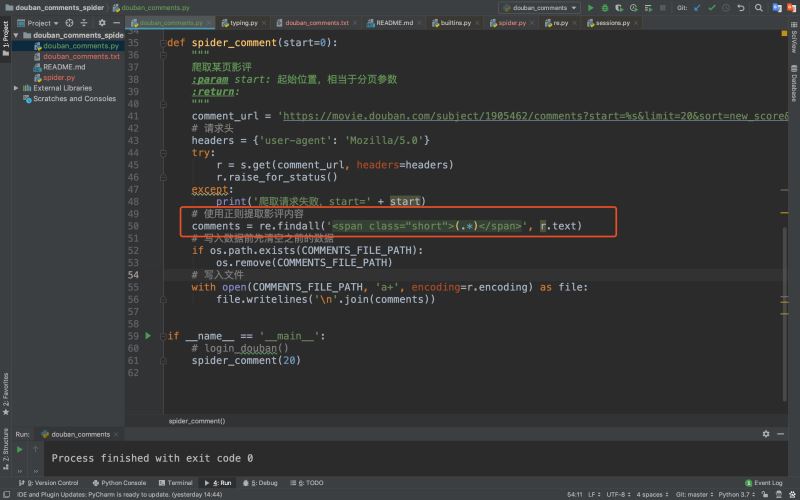
检查下提取的内容

4.批量爬取
我们爬取、提取、保存完一条数据之后,我们来批量爬取一下。根据前面几次爬取的经验,我们知道批量爬取的关键在于找到分页参数,我们可以很快发现URL中有一个start参数便是控制分页的参数。

这里只爬取了25页就爬完,我们可以去浏览器中验证一下,是不是真的只有25页,猪哥验证过确实只有25页!
六、分析影评
数据抓取下来之后,我们就来使用词云分析一下这部电影吧!
基于使用词云分析的案例前面已经讲过两个了,所以猪哥只会简单的讲解一下!
1.使用结巴分词
因为我们下载的影评是一段一段的文字,而我们做的词云是统计单词出现的次数,所以需要先分词!

2.使用词云分析

最终成果:

从这些词中我们可以知道这是关于一部关于追寻自我与现实生活的电影,猪哥裂墙推荐!!!
七、总结
今天我们以爬取豆瓣为例子,学到了不少的东西,来总结一下:
- 学习如何使用requests库发起POST请求
- 学习了如何使用requests库登录网站
- 学习了如何使用requests库的Session对象保持会话状态
- 学习了如何使用正则表达式提取网页标签中的内容
鉴于篇幅有限,爬虫过程中遇到的很多细节和技巧并没有完全写出来,所以希望大家能自己动手实践
源码地址:https://github.com/pig6/douban_comments_spider
到此这篇关于详解如何用Python登录豆瓣并爬取影评的文章就介绍到这了,更多相关Python爬取影评内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 模拟登陆github的示例
# -*- coding: utf-8 -*- # @Author: CriseLYJ # @Date: 2020-08-14 12:13:11 import re import requests class GithubLogin(object): def __init__(self, email, password): # 初始化信息 self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2)
-
详解如何用Python模拟登录淘宝
目录 一.淘宝登录流程 二.模拟登录实现 1.判断是否需要验证码 2.验证用户名密码 3.申请st码 4.使用st码登录 5.获取淘宝昵称 三.总结 1.代码结构 2.存在问题 看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.selenium等库来模拟登录,但是目前我们还没有讲到这些库,只讲了requests库,那我们今天就来使用requests库模拟登录淘宝! 讲模拟登录淘宝之前,我们来回顾一下之前用requests库模拟登录豆瓣和新浪微博的过程:这一类模拟
-
python模拟登陆,用session维持回话的实例
python模拟登陆的几种方法 客户端向服务器发送请求,cookie则是表明我们身份的标志.而"访问登录后才能看到的页面"这一行为,恰恰需要客户端向服务器证明:"我是刚才登录过的那个客户端".于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态) 1.先在浏览器中登录,然后打开开发者选项,找到一个请求方法为POST的请求,复制Requests Headers中的cookie在爬取需要登录的页面时加上此cookies即可 import requests
-
详解python项目实战:模拟登陆CSDN
前言 今天为大家介绍一个利用Python模拟登陆CSDN的案例,虽然看起来很鸡肋,有时候确会有大用处,在这里就当做是一个案例练习吧,提高自己的代码水平,也了解Python如何做到模拟登陆的, 下面来看代码 导入库 获取头部信息 解析网页 返回登录过后的session 检测是否登陆正常 运行结果 以上所述是小编给大家介绍的python项目实战:模拟登陆CSDN详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
python模拟登陆网站的示例
使用已有cookie登陆 使用浏览器登陆,获取浏览器中的cookie信息,来进行登陆. 我们以博客园为例,先登录博客园账号.我们访问随笔列表,在控制台我们可以看到我们登陆后浏览器的cookie 剔除一些数据统计及分析的cookie,剩下的就是登陆可能需要的.CNBlogsCookie和.Cnblogs.AspNetCore.Cookies # _ga google分析 cookie # UM_distinctid 友盟cookie # CNZZxxx CNZZcookie # __utma,__
-
selenium携带cookies模拟登陆CSDN的实现
首先是获取cookies保存到本地 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/12/20 11:00 # @Author : huni # @File : cookies获取.py # @Software: PyCharm from selenium import webdriver from time import sleep import json if __name__ == '__main__': drive
-
python requests模拟登陆github的实现方法
1. Cookie 介绍 HTTP 协议是无状态的.因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信.Cookie 就是「其他手段」之一. Cookie 一个典型的应用场景,就是用于记录用户在网站上的登录状态. 用户登录成功后,服务器下发一个(通常是加密了的)Cookie 文件. 客户端(通常是网页浏览器)将收到的 Cookie 文件保存起来. 下次客户端与服务器连接时,将 Cookie 文件发送给服务器,由服务器校验其含义,恢复登录状态(从而避免再次登录). 2.requ
-
详解如何用Python登录豆瓣并爬取影评
目录 一.需求背景 二.功能描述 三.技术方案 四.登录豆瓣 1.分析豆瓣登录接口 2.代码实现登录豆瓣 3.保存会话状态 4.这个Session对象是我们常说的session吗? 五.爬取影评 1.分析豆瓣影评接口 2.爬取一条影评数据 3.影评内容提取 4.批量爬取 六.分析影评 1.使用结巴分词 七.总结 上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面: 会话状态管理(如用户登录状态.购物车.游戏分数或其它需要记录的信息) 个性化
-
详解如何用Python实现感知器算法
目录 一.题目 二.数学求解过程 三.感知器算法原理及步骤 四.python代码实现及结果 一.题目 二.数学求解过程 该轮迭代分类结果全部正确,判别函数为g(x)=-2x1+1 三.感知器算法原理及步骤 四.python代码实现及结果 (1)由数学求解过程可知: (2)程序运行结果 (3)绘图结果 ''' 20210610 Julyer 感知器 ''' import numpy as np import matplotlib.pyplot as plt def get_zgxl(xn, a):
-
详解如何用Python写个听小说的爬虫
目录 书名和章节列表 音频地址 下载 完整代码 总结 在路上发现好多人都喜欢用耳机听小说,同事居然可以一整天的带着一只耳机听小说.小编表示非常的震惊.今天就用 Python 下载听小说 tingchina.com的音频. 书名和章节列表 随机点开一本书,这个页面可以使用 BeautifulSoup 获取书名和所有单个章节音频的列表.复制浏览器的地址,如:https://www.tingchina.com/yousheng/disp_31086.htm. from bs4 import Beaut
-
详解如何用python实现一个简单下载器的服务端和客户端
话不多说,先看代码: 客户端: import socket def main(): #creat: download_client=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #link: serv_ip=input("please input server IP") serv_port=int(input(("please input server port"))) serv_addr=(serv_ip,ser
-
详解如何利用Python绘制迷宫小游戏
目录 构思 绘制迷宫 走出迷宫 完整代码 更大的挑战 关于坐标系设置 周末在家,儿子闹着要玩游戏,让玩吧,不利于健康,不让玩吧,扛不住他折腾,于是想,不如一起搞个小游戏玩玩! 之前给他编过猜数字 和 掷骰子 游戏,现在已经没有吸引力了,就对他说:“我们来玩个迷宫游戏吧.” 果不其然,有了兴趣,于是和他一起设计实现起来,现在一起看看我们是怎么做的吧,说不定也能成为一个陪娃神器~ 先一睹为快: 构思 迷宫游戏,相对比较简单,设置好地图,然后用递归算法来寻找出口,并将过程显示出来,增强趣味性. 不如想
-
python登录豆瓣并发帖的方法
本文实例讲述了python登录豆瓣并发帖的方法.分享给大家供大家参考.具体如下: 这里涉及urllib.urllib2及cookielib常用方法的使用 登录豆瓣,由于有验证码,采取的办法是将验证码图片下载到同目录下,查看图片后输入验证码即可登录.发帖 帖子内容写死在代码中了 # -- coding:gbk -- import sys, time, os, re import urllib, urllib2, cookielib loginurl = 'https://www.douban.co
-
详解Golang 与python中的字符串反转
详解Golang 与python中的字符串反转 在go中,需要用rune来处理,因为涉及到中文或者一些字符ASCII编码大于255的. func main() { fmt.Println(reverse("Golang python")) } func reverse(src string) string { dst := []rune(src) len := len(dst) var result []rune result = make([]rune, 0) for i := le
-
详解微信小程序 登录获取unionid
详解微信小程序 登录获取unionid 首先公司开发了小程序, 公众号网页和app等, 之前都是用的openid来区分用户, 但openid只能标识用户在当前小程序或公众号里唯一, 我们希望用户可以在公司各个产品(比如公众号, 小程序, app里的微信登录)之间, 可以保持用户的唯一性, 还好微信给出了unionid. 下面分两步介绍一下 微信小程序 获取unionid的过程. 1. 首先 在微信公众平台注册小程序 , 然后在小程序上模拟登录流程. 注 : 这里只是简单登录流程, 实际中需要维护
-
详解C++调用Python脚本中的函数的实例代码
1.环境配置 安装完python后,把python的include和lib拷贝到自己的工程目录下 然后在工程中包括进去 2.例子 先写一个python的测试脚本,如下 这个脚本里面定义了两个函数Hello()和_add().我的脚本的文件名叫mytest.py C++代码: #include "stdafx.h" #include <stdlib.h> #include <iostream> #include "include\Python.h&quo