关于keras多任务多loss回传的思考
如果有一个多任务多loss的网络,那么在训练时,loss是如何工作的呢?
比如下面:
model = Model(inputs = input, outputs = [y1, y2]) l1 = 0.5 l2 = 0.3 model.compile(loss = [loss1, loss2], loss_weights=[l1, l2], ...)
其实我们最终得到的loss为
final_loss = l1 * loss1 + l2 * loss2
我们最终的优化效果是最小化final_loss。
问题来了,在训练过程中,是否loss2只更新得到y2的网络通路,还是loss2会更新所有的网络层呢?
此问题的关键在梯度回传上,即反向传播算法。
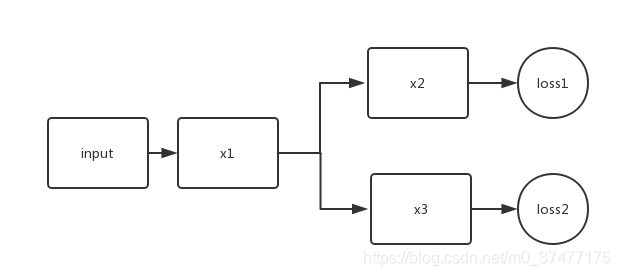

所以loss1只对x1和x2有影响,而loss2只对x1和x3有影响。
补充:keras 多个LOSS总和定义
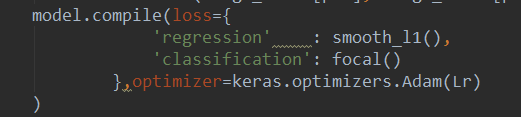
用字典形式,名字是模型中输出那一层的名字,这里的loss可以是自己定义的,也可是自带的
补充:keras实战-多类别分割loss实现
本文样例均为3d数据的onehot标签形式,即y_true(batch_size,x,y,z,class_num)
1、dice loss
def dice_coef_fun(smooth=1):
def dice_coef(y_true, y_pred):
#求得每个sample的每个类的dice
intersection = K.sum(y_true * y_pred, axis=(1,2,3))
union = K.sum(y_true, axis=(1,2,3)) + K.sum(y_pred, axis=(1,2,3))
sample_dices=(2. * intersection + smooth) / (union + smooth) #一维数组 为各个类别的dice
#求得每个类的dice
dices=K.mean(sample_dices,axis=0)
return K.mean(dices) #所有类别dice求平均的dice
return dice_coef
def dice_coef_loss_fun(smooth=0):
def dice_coef_loss(y_true,y_pred):
return 1-1-dice_coef_fun(smooth=smooth)(y_true=y_true,y_pred=y_pred)
return dice_coef_loss
2、generalized dice loss
def generalized_dice_coef_fun(smooth=0):
def generalized_dice(y_true, y_pred):
# Compute weights: "the contribution of each label is corrected by the inverse of its volume"
w = K.sum(y_true, axis=(0, 1, 2, 3))
w = 1 / (w ** 2 + 0.00001)
# w为各个类别的权重,占比越大,权重越小
# Compute gen dice coef:
numerator = y_true * y_pred
numerator = w * K.sum(numerator, axis=(0, 1, 2, 3))
numerator = K.sum(numerator)
denominator = y_true + y_pred
denominator = w * K.sum(denominator, axis=(0, 1, 2, 3))
denominator = K.sum(denominator)
gen_dice_coef = numerator / denominator
return 2 * gen_dice_coef
return generalized_dice
def generalized_dice_loss_fun(smooth=0):
def generalized_dice_loss(y_true,y_pred):
return 1 - generalized_dice_coef_fun(smooth=smooth)(y_true=y_true,y_pred=y_pred)
return generalized_dice_loss
3、tversky coefficient loss
# Ref: salehi17, "Twersky loss function for image segmentation using 3D FCDN"
# -> the score is computed for each class separately and then summed
# alpha=beta=0.5 : dice coefficient
# alpha=beta=1 : tanimoto coefficient (also known as jaccard)
# alpha+beta=1 : produces set of F*-scores
# implemented by E. Moebel, 06/04/18
def tversky_coef_fun(alpha,beta):
def tversky_coef(y_true, y_pred):
p0 = y_pred # proba that voxels are class i
p1 = 1 - y_pred # proba that voxels are not class i
g0 = y_true
g1 = 1 - y_true
# 求得每个sample的每个类的dice
num = K.sum(p0 * g0, axis=( 1, 2, 3))
den = num + alpha * K.sum(p0 * g1,axis= ( 1, 2, 3)) + beta * K.sum(p1 * g0, axis=( 1, 2, 3))
T = num / den #[batch_size,class_num]
# 求得每个类的dice
dices=K.mean(T,axis=0) #[class_num]
return K.mean(dices)
return tversky_coef
def tversky_coef_loss_fun(alpha,beta):
def tversky_coef_loss(y_true,y_pred):
return 1-tversky_coef_fun(alpha=alpha,beta=beta)(y_true=y_true,y_pred=y_pred)
return tversky_coef_loss
4、IoU loss
def IoU_fun(eps=1e-6):
def IoU(y_true, y_pred):
# if np.max(y_true) == 0.0:
# return IoU(1-y_true, 1-y_pred) ## empty image; calc IoU of zeros
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3]) - intersection
#
ious=K.mean((intersection + eps) / (union + eps),axis=0)
return K.mean(ious)
return IoU
def IoU_loss_fun(eps=1e-6):
def IoU_loss(y_true,y_pred):
return 1-IoU_fun(eps=eps)(y_true=y_true,y_pred=y_pred)
return IoU_loss
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
keras做CNN的训练误差loss的下降操作
采用二值判断如果确认是噪声,用该点上面一个灰度进行替换. 噪声点处理:对原点周围的八个点进行扫描,比较.当该点像素值与周围8个点的值小于N时,此点为噪点 . 处理后的文件大小只有原文件小的三分之一,前后的图片内容肉眼几乎无法察觉. 但是这样处理后图片放入CNN中在其他条件不变的情况下,模型loss无法下降,二分类图片,loss一直在8-9之间.准确率维持在0.5,同时,测试集的训练误差持续下降,但是准确率也在0.5徘徊.大概真是需要误差,让优化方法从局部最优跳出来. 使用的activation
-
Keras loss函数剖析
我就废话不多说了,大家还是直接看代码吧~ ''' Created on 2018-4-16 ''' def compile( self, optimizer, #优化器 loss, #损失函数,可以为已经定义好的loss函数名称,也可以为自己写的loss函数 metrics=None, # sample_weight_mode=None, #如果你需要按时间步为样本赋权(2D权矩阵),将该值设为"temporal".默认为"None",代表按样本赋权(1D权),和f
-
解决keras GAN训练是loss不发生变化,accuracy一直为0.5的问题
1.Binary Cross Entropy 常用于二分类问题,当然也可以用于多分类问题,通常需要在网络的最后一层添加sigmoid进行配合使用,其期望输出值(target)需要进行one hot编码,另外BCELoss还可以用于多分类问题Multi-label classification. 定义: For brevity, let x = output, z = target. The binary cross entropy loss is loss(x, z) = - sum_i (x[
-
使用keras框架cnn+ctc_loss识别不定长字符图片操作
我就废话不多说了,大家还是直接看代码吧~ # -*- coding: utf-8 -*- #keras==2.0.5 #tensorflow==1.1.0 import os,sys,string import sys import logging import multiprocessing import time import json import cv2 import numpy as np from sklearn.model_selection import train_test_s
-
浅谈keras中loss与val_loss的关系
loss函数如何接受输入值 keras封装的比较厉害,官网给的例子写的云里雾里, 在stackoverflow找到了答案 You can wrap the loss function as a inner function and pass your input tensor to it (as commonly done when passing additional arguments to the loss function). def custom_loss_wrapper(input_
-
keras中epoch,batch,loss,val_loss用法说明
1.epoch Keras官方文档中给出的解释是:"简单说,epochs指的就是训练过程接中数据将被"轮"多少次" (1)释义: 训练过程中当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个epoch,网络会在每个epoch结束时报告关于模型学习进度的调试信息. (2)为什么要训练多个epoch,即数据要被"轮"多次 在神经网络中传递完整的数据集一次是不够的,对于有限的数据集(是在批梯度下降情况下),使用一个迭代过程,更新权重一
-
keras 自定义loss层+接受输入实例
loss函数如何接受输入值 keras封装的比较厉害,官网给的例子写的云里雾里, 在stackoverflow找到了答案 You can wrap the loss function as a inner function and pass your input tensor to it (as commonly done when passing additional arguments to the loss function). def custom_loss_wrapper(input_
-

关于keras多任务多loss回传的思考
如果有一个多任务多loss的网络,那么在训练时,loss是如何工作的呢? 比如下面: model = Model(inputs = input, outputs = [y1, y2]) l1 = 0.5 l2 = 0.3 model.compile(loss = [loss1, loss2], loss_weights=[l1, l2], ...) 其实我们最终得到的loss为 final_loss = l1 * loss1 + l2 * loss2 我们最终的优化效果是最小化final_los
-
keras 多任务多loss实例
记录一下: # Three loss functions category_predict1 = Dense(100, activation='softmax', name='ctg_out_1')( Dropout(0.5)(feature1) ) category_predict2 = Dense(100, activation='softmax', name='ctg_out_2')( Dropout(0.5)(feature2) ) dis = Lambda(eucl_dist, nam
-
keras中的loss、optimizer、metrics用法
用keras搭好模型架构之后的下一步,就是执行编译操作.在编译时,经常需要指定三个参数 loss optimizer metrics 这三个参数有两类选择: 使用字符串 使用标识符,如keras.losses,keras.optimizers,metrics包下面的函数 例如: sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', opt
-
对Keras自带Loss Function的深入研究
本文研究Keras自带的几个常用的Loss Function. 1. categorical_crossentropy VS. sparse_categorical_crossentropy 注意到二者的主要差别在于输入是否为integer tensor.在文档中,我们还可以找到关于二者如何选择的描述: 解释一下这里的Integer target 与 Categorical target,实际上Integer target经过独热编码就变成了Categorical target,举例说明: (类
-
keras 自定义loss损失函数,sample在loss上的加权和metric详解
首先辨析一下概念: 1. loss是整体网络进行优化的目标, 是需要参与到优化运算,更新权值W的过程的 2. metric只是作为评价网络表现的一种"指标", 比如accuracy,是为了直观地了解算法的效果,充当view的作用,并不参与到优化过程 在keras中实现自定义loss, 可以有两种方式,一种自定义 loss function, 例如: # 方式一 def vae_loss(x, x_decoded_mean): xent_loss = objectives.binary_
-
TensorFlow keras卷积神经网络 添加L2正则化方式
我就废话不多说了,大家还是直接看代码吧! model = keras.models.Sequential([ #卷积层1 keras.layers.Conv2D(32,kernel_size=5,strides=1,padding="same",data_format="channels_last",activation=tf.nn.relu,kernel_regularizer=keras.regularizers.l2(0.01)), #池化层1 keras.l
-
keras处理欠拟合和过拟合的实例讲解
baseline import tensorflow.keras.layers as layers baseline_model = keras.Sequential( [ layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)), layers.Dense(16, activation='relu'), layers.Dense(1, activation='sigmoid') ] ) baseline_model.compil
-
基于keras中的回调函数用法说明
keras训练 fit( self, x, y, batch_size=32, nb_epoch=10, verbose=1, callbacks=[], validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None ) 1. x:输入数据.如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应