解决Pytorch中的神坑:关于model.eval的问题
有时候使用Pytorch训练完模型,在测试数据上面得到的结果令人大跌眼镜。
这个时候需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在
那么在测试之前需要加入一行代码:
#model是实例化的模型对象 model = model.eval()
表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰。
因为BN和Dropout在训练和测试时是不同的:
对于BN,训练时通常采用mini-batch,所以每一批中的mean和std大致是相同的;而测试阶段往往是单个图像的输入,不存在mini-batch的概念。所以将model改为eval模式后,BN的参数固定,并采用之前训练好的全局的mean和std;
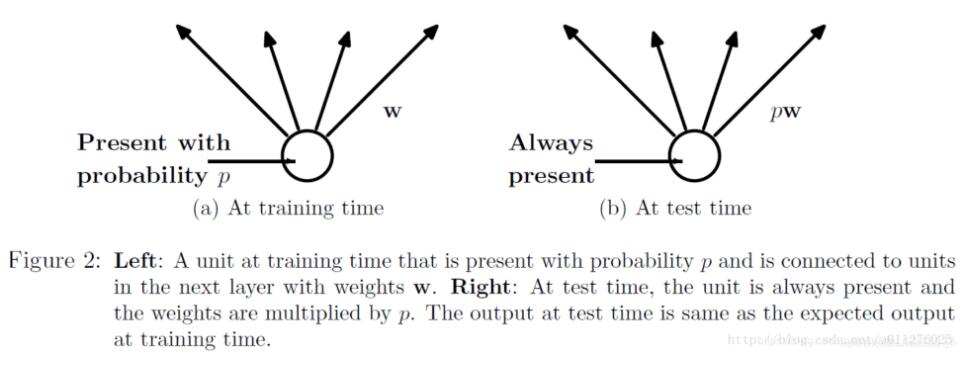
对于Dropout,训练阶段,隐含层神经元先乘概率P,再进行激活;而测试阶段,神经元先激活,每个隐含层神经元的输出再乘概率P。
如下图所示:
补充:pytorch中model.eval之后是否还需要model.train的问题
答案是:需要的
正确的写法是

for循环之后再开启train,
循环之后的评估model.eval之后就会再次回到model.train
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch:model.train和model.eval用法及区别详解
使用PyTorch进行训练和测试时一定注意要把实例化的model指定train/eval,eval()时,框架会自动把BN和DropOut固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大!!!!!! Class Inpaint_Network() ...... Model = Inpaint_Nerwoek() #train: Model.train(mode=True) ..... #test: Model.ev
-
聊聊PyTorch中eval和no_grad的关系
首先这两者有着本质上区别 model.eval()是用来告知model内的各个layer采取eval模式工作.这个操作主要是应对诸如dropout和batchnorm这些在训练模式下需要采取不同操作的特殊layer.训练和测试的时候都可以开启. torch.no_grad()则是告知自动求导引擎不要进行求导操作.这个操作的意义在于加速计算.节约内存.但是由于没有gradient,也就没有办法进行backward.所以只能在测试的时候开启. 所以在evaluate的时候,需要同时使用两者. mod
-
pytorch掉坑记录:model.eval的作用说明
训练完train_datasets之后,model要来测试样本了.在model(test_datasets)之前,需要加上model.eval(). 否则的话,有输入数据,即使不训练,它也会改变权值. 这是model中含有batch normalization层所带来的的性质. 在做one classification的时候,训练集和测试集的样本分布是不一样的,尤其需要注意这一点. 补充知识:pytorch测试的时候为何要加上model.eval() Do need to use model.e
-

解决Pytorch中的神坑:关于model.eval的问题
有时候使用Pytorch训练完模型,在测试数据上面得到的结果令人大跌眼镜. 这个时候需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在 那么在测试之前需要加入一行代码: #model是实例化的模型对象 model = model.eval() 表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰. 因为BN和Dropout在训练和测试时是不同的: 对于BN,训练时通常采用mini-batch,所以每一批中的mean
-
Pytorch中的modle.train,model.eval,with torch.no_grad解读
目录 modle.train,model.eval,with torch.no_grad解读 model.eval()与torch.no_grad()的作用 model.eval() torch.no_grad() 异同 总结 modle.train,model.eval,with torch.no_grad解读 1. 最近在学习pytorch过程中遇到了几个问题 不理解为什么在训练和测试函数中model.eval(),和model.train()的区别,经查阅后做如下整理 一般情况下,我们训练
-
解决Pytorch中Batch Normalization layer踩过的坑
1. 注意momentum的定义 Pytorch中的BN层的动量平滑和常见的动量法计算方式是相反的,默认的momentum=0.1 BN层里的表达式为: 其中γ和β是可以学习的参数.在Pytorch中,BN层的类的参数有: CLASS torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 每个参数具体含义参见文档,需要注意的是,affine定义了BN层的
-
Pytorch 中net.train 和 net.eval的使用说明
在训练模型时会在前面加上: model.train() 在测试模型时在前面使用: model.eval() 同时发现,如果不写这两个程序也可以运行,这是因为这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout. 训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念. 由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差. 所有B
-
解决pytorch中的kl divergence计算问题
偶然从pytorch讨论论坛中看到的一个问题,KL divergence different results from tf,kl divergence 在TensorFlow中和pytorch中计算结果不同,平时没有注意到,记录下 一篇关于KL散度.JS散度以及交叉熵对比的文章 kl divergence 介绍 KL散度( Kullback–Leibler divergence),又称相对熵,是描述两个概率分布 P 和 Q 差异的一种方法.计算公式: 可以发现,P 和 Q 中元素的个数不用相等
-
在pytorch中如何查看模型model参数parameters
目录 pytorch查看模型model参数parameters pytorch查看模型参数总结 1:DNN_printer 2:parameters 3:get_model_complexity_info() 4:torchstat pytorch查看模型model参数parameters 示例1:pytorch自带的faster r-cnn模型 import torch import torchvision model = torchvision.models.detection.faster
-
聊聊pytorch测试的时候为何要加上model.eval()
Do need to use model.eval() when I test? Sure, Dropout works as a regularization for preventing overfitting during training. It randomly zeros the elements of inputs in Dropout layer on forward call. It should be disabled during testing since you may
-
pytorch中的model.eval()和BN层的使用
看代码吧~ class ConvNet(nn.module): def __init__(self, num_class=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2))
-
Pytorch中关于model.eval()的作用及分析
目录 model.eval()的作用及分析 结论 Pytorch踩坑之model.eval()问题 比较常见的有两方面的原因 1) data 2)model.state_dict() model.eval() vs torch.no_grad() 总结 model.eval()的作用及分析 model.eval() 作用等同于 self.train(False) 简而言之,就是评估模式.而非训练模式. 在评估模式下,batchNorm层,dropout层等用于优化训练而添加的网络层会被关
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代