Python爬虫之m3u8文件里提取小视频的正确姿势
前言
在网上爬取的小视频(.ts格式)打不开怎么搞?使用IDM下载有时候还会出现数据受法律保护,IDM无法下载该内容,如何解决?这篇博客就来聊聊如何正确提取m3u8文件里的.ts视频,并合成完整的.mp4格式视频。


1. HLS协议与m3u8文件
HLS,即 H T T P L i v e S t r e a m i n g HTTP\ Live\ Streaming HTTP Live Streaming的缩写,是由苹果公司提出基于HTTP的流媒体网络传输协议。是苹果公司QuickTime X和iPhone软件系统的一部分。它的工作原理是把整个流分成一个个小的基于HTTP的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。在开始一个流媒体会话时,客户端会下载一个包含元数据的扩展 M3U (m3u8) 播放列表文件,用于寻找可用的媒体流。
M3U8是 U n i c o d e Unicode Unicode 版本的 M3U,用 UTF-8 编码。"M3U"和"M3U8"文件都是苹果公司使用的 H T T P L i v e S t r e a m i n g HTTP\ Live\ Streaming HTTP Live Streaming 格式的基础,这种格式可以在 iPhone 和 Macbook 等设备播放。是一种播放多媒体列表的文件格式,文本内容是一系列媒体片段资源,顺序播放该片段资源,即可完整展示多媒体资源。其格式大致如下:
# 未加密 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:8 #EXT-X-MEDIA-SEQUENCE:0 #EXTINF:4.000000, 1af12fece7a000000.ts #EXTINF:4.320000, 1af12fece7a000001.ts ... #EXTINF:3.800000, 1af12fece7a001155.ts #EXT-X-ENDLIST # 加密 #EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:6 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="https://ts1.yuyuangewh.com:9999/20200808/1XdSSbTb/2000kb/hls/key.key" #EXTINF:3, https://ts1.yuyuangewh.com:9999/20200808/1XdSSbTb/2000kb/hls/EUtRrqJU.ts #EXTINF:4.72, https://ts1.yuyuangewh.com:9999/20200808/1XdSSbTb/2000kb/hls/HF90vrrN.ts ... #EXTINF:0.24, https://ts1.yuyuangewh.com:9999/20200808/1XdSSbTb/2000kb/hls/b7ZLcRqT.ts #EXT-X-ENDLIST
下面介绍几个m3u8文件中常见的标签:
| 标签 | 格式 | 作用 |
|---|---|---|
EXTM3U |
#EXTM3U |
表明该文件是一个m3u8文件,每个m3u8文件必须将该标签放置在第一行 |
EXT-X-VERSION |
EXT-X-VERSION:<number> |
表明该文件是一个m3u8文件,每个m3u8文件必须将该标签放置在第一行 |
EXT-X-TARGETDURATION |
#EXT-X-TARGETDURATION:<s> |
表示每个视频分段最大的时长(单位秒) |
EXT-X-PLAYLIST-TYPE |
#EXT-X-PLAYLIST-TYPE:<type-enum> |
表明流媒体类型,VOD 表示该视屏流为点播源,因此服务器不能更改该m3u8文件;EVENT表示该视频流为直播源,因此服务器不能更改或删除该文件任意部分内容,但是可以在文件末尾添加新内容 |
EXT-X-MEDIA-SEQUENCE |
#EXT-X-MEDIA-SEQUENCE:<number> |
表示播放列表第一个URL片段文件的序列号,每个媒体片段URL都拥有一个唯一的整型序列号,每个媒体片段序列号按出现顺序依次加 1,如果该标签未指定,则默认序列号从0开始 |
EXT-X-KEY |
#EXT-X-KEY:METHOD=AES-128,URI="http:xxxx",IV="xxxx" |
表明视频流文件的加解密方法,METHOD表示加密方式,URI表示密钥路径,该密钥是一个 16 字节的数据,IV是一个128位的十六进制数值 |
EXTINF |
#EXTINF:<duration>,[<title>] |
表示其后 URL 指定的媒体片段时长(单位为秒),duration可以为十进制的整型或者浮点型,其值必须小于或等于EXT-X-TARGETDURATION指定的值 |
EXT-X-ENDLIST |
#EXT-X-ENDLIST |
表明m3u8文件的结束 |
简书:m3u8 文件格式详解 作者:Whyn
2. 第三方库----m3u8
m3u8是一个专门用于解析m3u8文件的解析器,有关库的详细操作请参阅官方示例
# 安装m3u8 pip install m3u8
# 加载m3u8文件 import m3u8 # 返回一个M3U8对象 playlist = m3u8.load(uri='http://videoserver.com/playlist.m3u8') # url # playlist = m3u8.load(uri='playlist.m3u8') # file print(playlist.segments) # 打印EXT-X-KEY标签和所有的EXTINF标签: print(playlist.target_duration) # 打印EXT-X-TARGETDURATION标签的值 for key in playlist.keys: if key: # 如果视频文件加密,可以查看加密参数 print(key.uri, key.method, key.iv)
3. 合成mp4文件
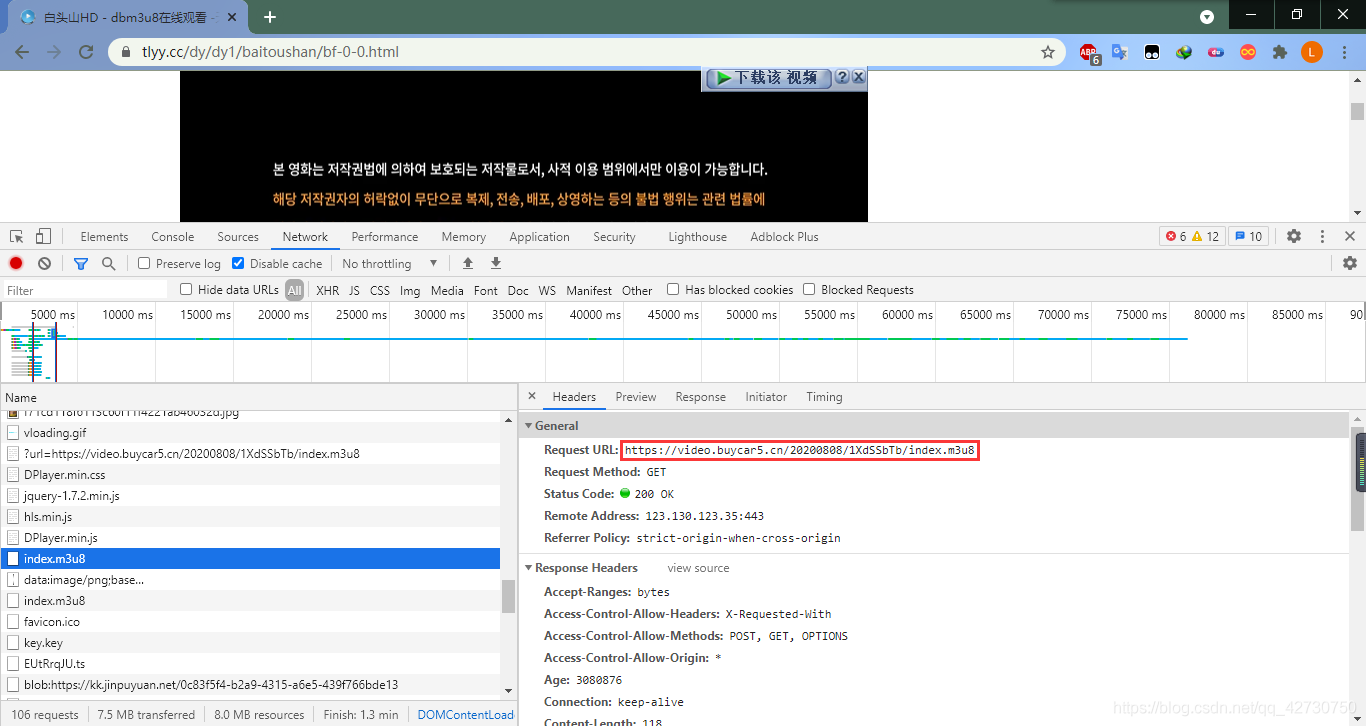
本次就以这个视频为例,流程如下:
1. 找到视频对应的.m3u8文件
2. 解析.m3u8文件,从中提取.ts视频的url
3. 下载.ts格式的视频
4. 解密.ts格式的视频(如果视频流没有加密,则该步不是必须的)
5. 合成.mp4或其他格式的视频
# 第1步,我载了m3u8文件,也可以直接使用m3u8文件对应的url
playlist = m3u8.load(uri='./data/index.m3u8')
# 第2步,提取URL
for seg in playlist.segments:
print(seg.uri)
# 第3步,下载ts视频
with open('xxxxx.ts', 'wb') as f:
ts = get_ts(url)
f.write(ts)
# 第4步,解密
cipher_text = pad(data_to_pad=cipher_text, block_size=AES.block_size)
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
cipher_text = aes.decrypt(cipher_text)
# 第5步,合成
files = glob.glob(os.path.join('./video', '*.ts'))
for file in files:
with open(file, 'rb') as fr, open('./video_de/baitoushan.mp4', 'ab') as fw:
content = fr.read()
fw.write(content )
4. 完整代码
# -*- coding: utf-8 -*-
# @Time : 2021/5/10 20:11
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : video.py
# @Software: PyCharm
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
from concurrent.futures import ThreadPoolExecutor
import requests
import m3u8
import glob
import os
import time
import logging
logging.getLogger("urllib3").setLevel(logging.WARNING)
def AESDecrypt(cipher_text, key, iv):
cipher_text = pad(data_to_pad=cipher_text, block_size=AES.block_size)
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
cipher_text = aes.decrypt(cipher_text)
# clear_text = unpad(padded_data=cipher_text, block_size=AES.block_size)
return cipher_text
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def get_ts(url):
try:
response = requests.get(url, verify=False)
response.raise_for_status()
response.encoding = 'utf-8'
return response.content
except Exception as err:
print(err)
return b''
def save_ts(url, index):
filename = os.path.join('./video', str(index).zfill(5) + '.ts')
with open(filename, 'wb') as f:
ts = get_ts(url)
f.write(ts)
print(filename + ' is ok!')
if __name__ == '__main__':
playlist = m3u8.load(uri='./data/index.m3u8')
# 线程池,引入index可以防止合成时视频发生乱序
with ThreadPoolExecutor(max_workers=10) as pool:
for index, seg in enumerate(playlist.segments):
pool.submit(save_ts, seg.uri, index)
key = get_ts(playlist.keys[-1].uri)
files = glob.glob(os.path.join('./video', '*.ts'))
for file in files:
with open(file, 'rb') as fr, open('./video_de/baitoushan.mp4', 'ab') as fw:
content = fr.read()
encontent = AESDecrypt(content, key=key, iv=key)
fw.write(encontent)
print(file + ' is ok!')
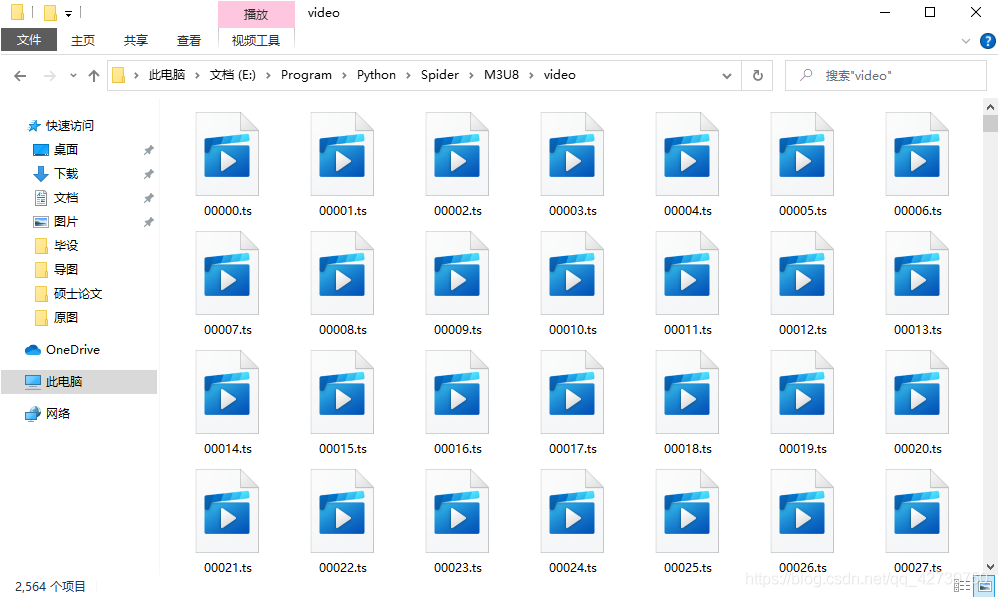
下载.ts文件效果如下:
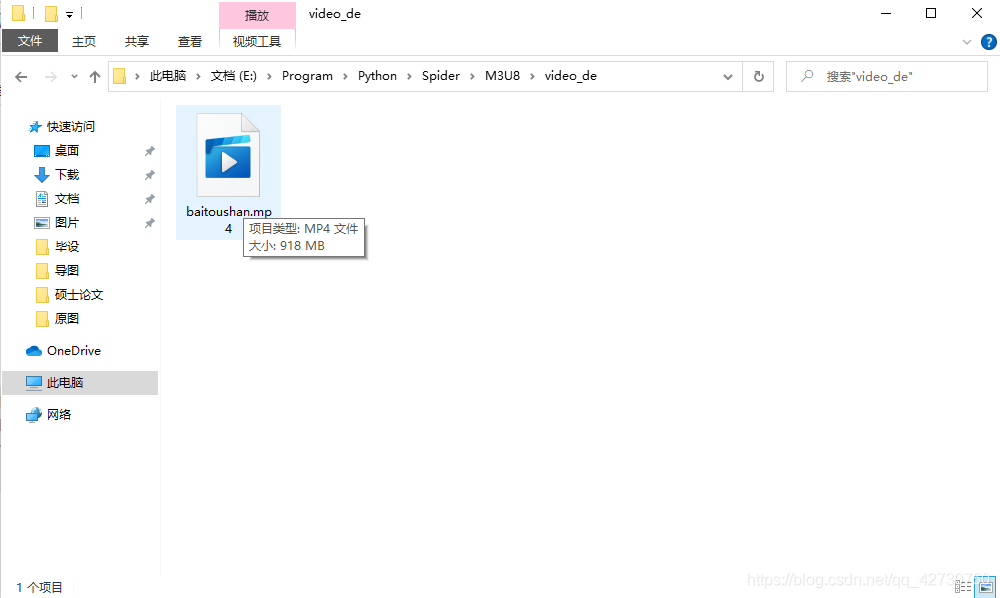
合成.mp4文件效果如下:

5. 结束语
Musicer开源代码仓库
Musicer音乐爬虫已经开源了哦,持续更新中,欢迎来踩来Star哦!ヾ(≧∇≦*)ヾ
以上就是Python爬虫之m3u8文件里提取小视频的正确姿势的详细内容,更多关于Python提取m3u8文件小视频的资料请关注我们其它相关文章!
相关推荐
-

Python解析m3u8拼接下载mp4视频文件的示例代码
一.关于m3u8: m3u8是苹果公司推出一种视频播放标准,是m3u的一种,不过编码方式是utf-8,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求. 示例: #EXTM3U #EXT-X-TARGETDURATION:10 #EXTINF:9, http://data.video.iqiyi.com/videos/vts/20210301/69/b8/73ad4ef0
-
Python通过m3u8文件下载合并ts视频的操作
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结. 1. m3u8文件 m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式.目前,很多新闻视频网站都是采用这种模式去加载视频. M3U8文件是指UTF-8编码格式的M3U文件.M3U文件是记录了一个索引纯文本
-
python 实现多线程下载m3u8格式视频并使用fmmpeg合并
电影之类的长视频好像都用m3u8格式了,这就导致了多线程下载视频的意义不是很大,都是短视频,线不线程就没什么意义了嘛. 我们知道,m3u8的链接会下载一个文档,相当长,半小时的视频,应该有接近千行ts链接. 这些ts链接下载成ts文件,就是碎片化的视频,加以合并,就成了需要的视频. 那,即便网速很快,下几千行视频,效率也就低了,更何况还要合并.我就琢磨了一下午,怎么样才能多线程下载m3u8格式的视频呢? 先上代码,再说重难点: import datetime import os import r
-
python实现m3u8格式转换为mp4视频格式
开发动机:最近用手机QQ浏览器下载了一些视频,视频越来越多,占用了手机内存,于是想把下载的视频传到电脑上保存,可后来发现这些视频都是m3u8格式的,且这个格式的视频都切成了碎片,存在电脑里不方便查看,于是想把它转换为其他可以直接打开播放的完整视频,到网上找了一些工具,都不怎么好用,后来发现一个手机端的"缓冲合并工具",倒是可以用,但是合并的视频顺序是乱的,碎片的视频顺序还需要用户手动调整,感觉太耽误时间了,于是自己打算写一个转换工具. 直接上代码:(程序的文件名为:convert_m3
-
python基于tkinter制作m3u8视频下载工具
这是我为了学习tkinter用python 写的一个下载m3u8视频的小程序,程序使用了多线程下载,下载后自动合并成一个视频文件,方便播放. 目前的众多视频都是m3u8的播放类型,只要知道视频的m3u8地址,就可以完美下载整个视频. m3u8地址获取 打开浏览器,点开你要获取地址的视频 重要的来了,右键>>审查元素或者按F12也可以 根据开发或测试的实际环境选择相应的设备,选择iphone6 plus 选择好了以后,刷新页面,点击漏斗,选择media,一定刷新之后再点击,没出来的话切换几下选项
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
python 下载m3u8视频的示例代码
import requests import os import datetime import threading class xiazai(): def __init__(self,url): self.url = url work_dir = os.getcwd() # print(work_dir) # 用来保存ts文件 file_dir = os.path.join(work_dir, 'file_tmp') if not os.path.exists(file_dir): os.mk
-
python3.6根据m3u8下载mp4视频
需要下载某网站的视频,chrome浏览器按F12打开开发者模式,发现视频链接是以"blob:http"开头的链接,打开这个链接后找不到网页,网上查了下,找到了下载方法,在这里做个记录,如果有错误,欢迎指出. 程序在Windows 10下运行,不过Linux应该也没问题. 使用到的有re模块,requests模块和Crypto模块,其中requests模块和Crypto模块如果没安装可以使用pip命令安装.(Crypto模块安装感觉比较坑,我是从anaconda里拷贝了一份) 下面开始正
-
python将下载到本地m3u8视频合成MP4的代码详解
代码如下所示: import os import requests import datetime from Crypto.Cipher import AES def decode_key_file(key_file_name): with open(key_file_name,"r") as f: data=f.read() return data def decode_m_file(m_file_name): with open(m_file_name,"r")
-
Python爬虫之m3u8文件里提取小视频的正确姿势
前言 在网上爬取的小视频(.ts格式)打不开怎么搞?使用IDM下载有时候还会出现数据受法律保护,IDM无法下载该内容,如何解决?这篇博客就来聊聊如何正确提取m3u8文件里的.ts视频,并合成完整的.mp4格式视频. 1. HLS协议与m3u8文件 HLS,即 H T T P L i v e S t r e a m i n g HTTP\ Live\ Streaming HTTP Live Streaming的缩写,是由苹果公司提出基于HTTP的流媒体网络传输协议.是苹果公司Qui
-
python爬虫抓取时常见的小问题总结
目录 01 无法正常显示中文? 解决方法 02 加密问题 03 获取不到网页的全部代码? 04 点击下一页时网页网页不变 05 文本节点问题 06 如何快速找到提取数据? 07 获取标签中的数据 08 去除指定内容 09 转化为字符串类型 10 滥用遍历文档树 11 数据库保存问题 12 爬虫采集遇到的墙问题 逃避IP识别 变换请求内容 降低访问频率 慢速攻击判别 13 验证码问题 正向破解 逆向破解 前言: 现在写爬虫,入门已经不是一件门槛很高的事情了,网上教程一大把,但很多爬虫新手在爬取数据
-
python实现从pdf文件中提取文本,并自动翻译的方法
针对Python 3.5.2 测试 首先安装两个包: $ pip install googletrans $ pip install pdfminer3k googletrans会提供一个命令translate,这个命令会调用google translate api执行自动翻译: pdfminer3k会提供一个工具脚本pdf2txt.py: $ pdf2txt.py xxx.pdf 从stackoverflow搜索到可以去除页眉和页脚的命令(强烈推荐): 使用Ubuntu提供的pdftotext
-
对python读取zip压缩文件里面的csv数据实例详解
利用zipfile模块和pandas获取数据,代码比较简单,做个记录吧: # -*- coding: utf-8 -*- """ Created on Tue Aug 21 22:35:59 2018 @author: FanXiaoLei """ from zipfile import ZipFile import pandas as pd myzip=ZipFile('2.zip') f=myzip.open('2.csv') df=pd.r
-
python爬虫自动创建文件夹的功能
该爬虫应用了创建文件夹的功能: #file setting folder_path = "D:/spider_things/2016.4.6/" + file_name +"/" if not os.path.exists(folder_path): os.makedirs(folder_path) 上面代码块的意思是: "os.path.exists(folder_path)"用来判断folder_path这个路径是否存在,如果不存在,就执行&
-
python实现向ppt文件里插入新幻灯片页面的方法
本文实例讲述了python实现向ppt文件里插入新幻灯片页面的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: UTF-8 -*- import win32com.client import win32com.client.dynamic import os #我的示例(Template)文档名为 BugCurve.pptx def PowerPoint(): ppt = os.path.join(os.getcwd(), "BugCurve.pptx") A
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-
Python爬虫实战之批量下载快手平台视频数据
知识点 requests json re pprint 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 案例实现步骤: 一. 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 1.确定需求 (要爬取的内容是什么?) 爬取某个关键词对应的视频 保存mp4 2.通过开发者工具进行抓包分析 分析数据从哪里来的(找出真正的数据来源)? 静态加载页面 笔趣阁为例 动态加载页面 开发者工具抓数据包 [付费VIP完整版]只要看了就能学会的教程,
-
Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
详解webpack提取第三方库的正确姿势
我们在用webpack打包是时候,常常想单独提取第三方库,把它作为稳定版本的文件,利用浏览缓存减少请求次数.常用的提取第三方库的方法有两种 CommonsChunkPlugin DLLPlugin 区别:第一种每次打包,都要把第三方库也运行打包一次,第二种方法每次打包只打包项目文件,我们只要引用第一次打包好的第三方压缩文件就行了 CommonsChunkPlugin方法简介 我们拿vue举例 const vue = require('vue') { entry: { // bundle是我们要打