python读取当前目录下的CSV文件数据
在处理数据的时候,经常会碰到CSV类型的文件,下面将介绍如何读取当前目录下的CSV文件,步骤如下
1、获取当前目录所有的CSV文件名称:
#创建一个空列表,存储当前目录下的CSV文件全称
file_name = []
#获取当前目录下的CSV文件名
def name():
#将当前目录下的所有文件名称读取进来
a = os.listdir()
for j in a:
#判断是否为CSV文件,如果是则存储到列表中
if os.path.splitext(j)[1] == '.csv':
file_name.append(j)
2、将CSV文件读取进来:
#将CSV文件内容导入到csv_storage列表中
def csv_new(storage,name):
#创建一个空列表,用于存储CSV文件数据
csv_storage = []
with codecs.open(storage, 'r', encoding='utf-8') as fp:
fp_key = csv.reader(fp)
for csv_key in fp_key:
csv_reader = csv.DictReader(fp, fieldnames=csv_key)
for row in csv_reader:
csv_dict = dict(row)
csv_storage.append(csv_dict)
3、连续读取多个CSV文件:
设置一个for循环,将第一部分读取到的文件名称逐个传递给读取文件的函数,全部代码如下所示:
import codecs
import csv
import os
#创建一个空列表,存储当前目录下的CSV文件全称
file_name = []
#获取当前目录下的CSV文件名
def name():
#将当前目录下的所有文件名称读取进来
a = os.listdir()
for j in a:
#判断是否为CSV文件,如果是则存储到列表中
if os.path.splitext(j)[1] == '.csv':
file_name.append(j)
#将CSV文件内容导入到csv_storage列表中
def csv_new(storage):
#创建一个空列表,用于存储CSV文件数据
csv_storage = []
with codecs.open(storage, 'r', encoding='utf-8') as fp:
fp_key = csv.reader(fp)
for csv_key in fp_key:
csv_reader = csv.DictReader(fp, fieldnames=csv_key)
for row in csv_reader:
csv_dict = dict(row)
csv_storage.append(csv_dict)
for i in csv_storage:
print(i)
#主要运行函数
if __name__ == '__main__':
#运行获取当前目录下所有的CSV文件
name()
#将多个CSV文件逐个读取
for name in file_name:
csv_new(name)
print(file_name)
4、最终的结果输出:
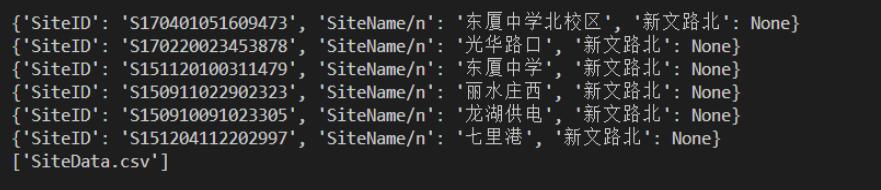
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python实现读取TXT文件数据并存进内置数据库SQLite3的方法
本文实例讲述了Python实现读取TXT文件数据并存进内置数据库SQLite3的方法.分享给大家供大家参考,具体如下: 当TXT文件太大,计算机内存不够时,我们可以选择按行读取TXT文件,并将其存储进Python内置轻量级splite数据库,这样可以加快数据的读取速度,当我们需要重复读取数据时,这样的速度加快所带来的时间节省是非常可观的,比如,当我们在训练数据时,要迭代10万次,即要从文件中读取10万次,即使每次只加快0.1秒,那么也能节省几个小时的时间了. #创建数据库并把txt文件的数据存进
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec
-

python读取各种文件数据方法解析
python读取.txt(.log)文件 ..xml 文件 .excel文件数据,并将数据类型转换为需要的类型,添加到list中详解 1.读取文本文件数据(.txt结尾的文件)或日志文件(.log结尾的文件) 以下是文件中的内容,文件名为data.txt(与data.log内容相同),且处理方式相同,调用时改个名称就可以了: 以下是python实现代码: # -*- coding:gb2312 -*- import json def read_txt_high(filename): with o
-
Python读取txt文件数据的方法(用于接口自动化参数化数据)
小试牛刀: 1.需要python如何读取文件 2.需要python操作list 3.需要使用split()对字符串进行分割 代码运行截图 : 代码(copy) #encoding=utf-8 #1.range中填写的数据 跟txt中行数保持一致 默认按照空格分隔 f_space = open(r"C:\Users\Administrator\Desktop\Space.txt","r") line_space = f_space.readlines() for i
-
基于Python和PyYAML读取yaml配置文件数据
一.首先我们需要安装 PyYAML 第三方库 直接使用 pip install PyYAML 就可以(这里我之前是装过的,所以提示我PyYAML已经在这个目录下了,是5.1.2版本的) 二.先看一下我的yaml配置文件中数据的格式 特点: 1.大小写敏感 2.使用缩进表示层级关系 3.缩进的时候使用的是空格,不是tab键(因为在写python脚本的时候可能会习惯用tab键进行缩进,这里的缩进只能使用空格.只要同层级的对齐,空一格或者空两格都是没有关系的) 4.#号表示注释 (这不就是python
-
python实现用类读取文件数据并计算矩形面积
1.创建一个类Rectangle,已知a.b求面积,求三角形的面积 2.结合题目一,从题目一文件中读取数据,并采用类的方法,将计算的结果写在另一个文档中. (1)利用类进行计算一个矩形的面积,已经a.b边长. class Rectangle: '''这是关于矩形面积的计算公式,只用给出矩形的长和宽, 调用实例函数,就可以返回所需要的面积''' number=0 def __init__(self,a,b): # a.b类似C中的形参 或者叫作构造方法 self.a1=a # 将形参中的值传入到类
-
python读取当前目录下的CSV文件数据
在处理数据的时候,经常会碰到CSV类型的文件,下面将介绍如何读取当前目录下的CSV文件,步骤如下 1.获取当前目录所有的CSV文件名称: #创建一个空列表,存储当前目录下的CSV文件全称 file_name = [] #获取当前目录下的CSV文件名 def name(): #将当前目录下的所有文件名称读取进来 a = os.listdir() for j in a: #判断是否为CSV文件,如果是则存储到列表中 if os.path.splitext(j)[1] == '.csv': file_
-
详解Python读取和写入操作CSV文件的方法
目录 什么是 CSV 文件? 内置 CSV 库解析 CSV 文件 读取 CSV 文件csv 将 CSV 文件读入字典csv 可选的 Python CSV reader参数 使用 csv 写入文件 从字典中写入 CSV 文件csv 使用 pandas 库解析 CSV 文件 pandas 读取 CSV 文件 pandas 写入 CSV 文件 最流行的数据交换格式之一是 CSV 格式.是需要通过键盘和控制台以外的方式将信息输入和输出的程序,通过文本文件交换信息是在程序之间共享信息的常用方法. 这里带和
-
python输出当前目录下index.html文件路径的方法
本文实例讲述了python输出当前目录下index.html文件路径的方法.分享给大家供大家参考.具体实现方法如下: import os import sys path = os.path.join(os.path.dirname(sys.argv[0]),'index.html') print path 希望本文所述对大家的Python程序设计有所帮助.
-
python读取目录下最新的文件夹方法
如下所示: def new_report(test_report): lists = os.listdir(test_report) # 列出目录的下所有文件和文件夹保存到lists lists.sort(key=lambda fn: os.path.getmtime(test_report + "/" + fn)) # 按时间排序 file_new = os.path.join(test_report, lists[-1]) # 获取最新的文件保存到file_new print(fi
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
python 读取目录下csv文件并绘制曲线v111的方法
实例如下: # -*- coding: utf-8 -*- """ Spyder Editor This temporary script file is located here: C:\Users\user\.spyder2\.temp.py """ """ Show how to modify the coordinate formatter to report the image "z"
-
python读取目录下所有的jpg文件,并显示第一张图片的示例
如下所示: # -*- coding: UTF-8 -*- import numpy as np import os from scipy.misc import imread, imresize import matplotlib.pyplot as plt from glob import glob # 读取目录下所有的jpg图片 def load_image(image_path, image_size): file_name=glob(image_path+"/*jpg") s
-
Python把对应格式的csv文件转换成字典类型存储脚本的方法
该脚本是为了结合之前的编写的脚本,来实现数据的比对模块,实现数据的自动化!由于数据格式是定死的,该代码只做参考,有什么问题可以私信我! CSV的数据格式截图如下: readDataToDic.py源代码如下: #coding=utf8 import csv ''' 该模块的主要功能,是根据已有的csv文件, 通过readDataToDicl函数,把csv中对应的部分, 写入字典中,每个字典当当作一条json数据 ''' class GenExceptData(object): def __ini
-
python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也可以先把文件拉到本地再读取也可以): 1.安装anaconda环境. 2.安装hdfs3. conda install hdfs3 3.安装fastparquet. conda install fastparquet 4.安装python-snappy. conda install python-s