大数据 java hive udf函数的示例代码(手机号码脱敏)
Hive UDFHive UDF 函数1 POM 文件2.UDF 函数3 利用idea打包4 添加hive udf函数4.1 上传jar包到集群4.2 修改集群hdfs文件权限4.3 注册UDF4.4 使用UDF
Hive UDF 函数
1 POM 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>填写自己的组织名称</groupId>
<artifactId>udf</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF8</project.build.sourceEncoding>
<!--Hadoop版本更改成自己的版本-->
<hadoop.version>2.6.0-cdh5.13.3</hadoop.version>
<hive.version>1.1.0-cdh5.13.3</hive.version>
</properties>
<repositories>
<!--加入Hadoop原生态的maven仓库的地址-->
<repository>
<id>Apache Hadoop</id>
<name>Apache Hadoop</name>
<url>https://repo1.maven.org/maven2/</url>
</repository>
<!--加入cdh的maven仓库的地址-->
<repository>
<id>cloudera</id>
<name>cloudera</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--添加hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--添加hive依赖-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<!--这部分可有可无,加上的话则直接生成可运行jar包-->
<!--<archive>-->
<!--<manifest>-->
<!--<mainClass>填写自己的组织名称.PhoneUnlookUdf</mainClass>-->
<!--</manifest>-->
<!--</archive>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.UDF 函数
package 填写自己的组织名称;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
// 上传udf jar到集群 hdfs dfs -put udf-1.0-SNAPSHOT-jar-with-dependencies.jar /data/data_coe/data_asset/prod/db/tmp/udf/
// 修改文件权限 hdfs dfs -chmod -R 777 hdfs://idc-nn/data/data_coe/data_asset/prod/db/tmp/udf/
//注册udf函数 create function tmp.pul as '填写自己的组织名称.PhoneUnlookUdf' using jar 'hdfs://idc-nn/data/data_coe/data_asset/prod/db/tmp/udf/udf-1.0-SNAPSHOT-jar-with-dependencies.jar
public class PhoneUnlookUdf extends UDF {
//重写evaluate方法
public String evaluate(String phone){
if (phone.length() == 11){
String res = phone.substring(0, 3) + "****" + phone.substring(7, phone.length());
System.out.println(res);
return res;
} else {
return phone;
}
}
}
3 利用idea打包
先点clean,在点package
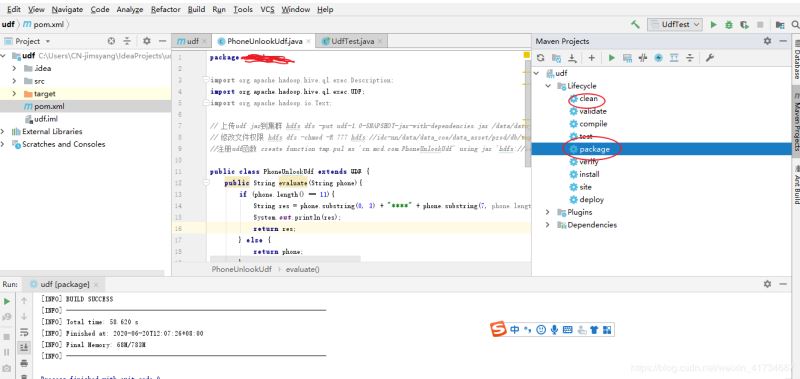
4 添加hive udf函数
集群的某些问题,不能直接通过添加服务器上本地文件到hive增加udf;需要将文件上传到hdfs,然后定义udf函数。
4.1 上传jar包到集群
// 上传udf jar到集群 hdfs dfs -put udf-1.0-SNAPSHOT-jar-with-dependencies.jar /data/data_coe/data_asset/prod/db/tmp/udf/
4.2 修改集群hdfs文件权限
// 修改文件权限 hdfs dfs -chmod -R 777 hdfs://idc-nn/data/data_coe/data_asset/prod/db/tmp/udf/
4.3 注册UDF
//注册udf函数 create function tmp.pul as 'cn.mcd.com.PhoneUnlookUdf' using jar 'hdfs://idc-nn/data/data_coe/data_asset/prod/db/tmp/udf/udf-1.0-SNAPSHOT-jar-with-dependencies.jar
4.4 使用UDF
···
打开集群hive客户端:
select tmp.pul(phone) from tmp.tmp_order limit 3;
···
总结
到此这篇关于大数据 java hive udf函数(手机号码脱敏)的文章就介绍到这了,更多相关大数据hive udf函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

javaweb学习总结——使用JDBC处理MySQL大数据
BLOB (binary large object),二进制大对象,是一个可以存储二进制文件的容器.在计算机中,BLOB常常是数据库中用来存储二进制文件的字段类型,BLOB是一个大文件,典型的BLOB是一张图片或一个声音文件,由于它们的尺寸,必须使用特殊的方式来处理(例如:上传.下载或者存放到一个数据库). 一.基本概念 在实际开发中,有时是需要用程序把大文本或二进制数据直接保存到数据库中进行储存的. 对MySQL而言只有blob,而没有clob,mysql存储大文本采用的是Text,Text和
-
为什么入门大数据选择Python而不是Java?
马云说:"未来最大的资源就是数据,不参与大数据十年后一定会后悔."毕竟出自wuli马大大之口,今年二月份我开始了学习大数据的道路,直到现在对大数据的学习脉络和方法也渐渐清晰.今天我们就来谈谈学习大数据入门语言的选择.当然并不只是我个人之见,此外我搜集了各路大神的见解综合起来跟大家做个讨论. java和python的区别到底在哪里? 官方解释:Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易
-
java 文件大数据Excel下载实例代码
java 文件大数据Excel下载实例代码 excel可以用xml表示.故可以以此来实现边写边下载文件 package com.tydic.qop.controller; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.I
-
Java实现Dbhelper支持大数据增删改
在做项目的时候,技术选型很重要,在底层的方法直接影响了我们对大数据访问以及修改的速度,在Java中有很多优秀的ORM框架,比如说:JPA,Hibernate 等等,正如我们所说的,框架有框架的好处,当然也存在一些可以改进的地方,这个时候,就需要我们针对于不同的业务不同的需求,不同的访问量,对底层的架构重新封装,来支持大数据增删改. 代码: import java.io.*; import java.sql.*; import java.util.*; import java.util.loggi
-
大数据 java hive udf函数的示例代码(手机号码脱敏)
Hive UDFHive UDF 函数1 POM 文件2.UDF 函数3 利用idea打包4 添加hive udf函数4.1 上传jar包到集群4.2 修改集群hdfs文件权限4.3 注册UDF4.4 使用UDF Hive UDF 函数 1 POM 文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0"
-
Java 设置Excel条件格式示例代码(高亮条件值、应用单元格值/公式/数据条等类型)
概述 在Excel中,应用条件格式功能可以在很大程度上改进表格的设计和可读性,用户可以指定单个或者多个单元格区域应用一种或者多种条件格式.本篇文章,将通过Java程序示例介绍条件格式的设置方法,设置条件格式时,因不同设置需要,本文分别从以下示例要点来介绍: 示例1: 1. 应用条件格式用于高亮重复.唯一数值 2. 应用条件格式用于高亮峰值(最高值.最低值) 3. 应用条件格式用于高亮低于或高于平均值的数值 示例2: 1. 应用单元格值类型的条件格式 2. 应用公式类型的条件格式 3. 应用数据条
-
在Java中操作Zookeeper的示例代码详解
依赖 <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.6.0</version> </dependency> 连接到zkServer //连接字符串,zkServer的ip.port,如果是集群逗号分隔 String connectStr = "192.
-
Java实现查找算法的示例代码(二分查找、插值查找、斐波那契查找)
目录 1.查找概述 2.顺序查找 3.二分查找 3.1 二分查找概述 3.2 二分查找实现 4.插值查找 4.1 插值查找概述 4.2 插值查找实现 5.斐波那契查找 5.1 斐波那契查找概述 5.2 斐波那契查找实现 5.3 总结 1.查找概述 查找表: 所有需要被查的数据所在的集合,我们给它一个统称叫查找表.查找表(Search Table)是由同一类型的数据元素(或记录)构成的集合. 查找(Searching): 根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录).
-
在Java中使用Jwt的示例代码
JWT 特点 JWT 默认是不加密,但也是可以加密的.生成原始 Token 以后,可以用密钥再加密一次. JWT 不加密的情况下,不能将秘密数据写入 JWT. JWT 不仅可以用于认证,也可以用于交换信息.有效使用 JWT,可以降低服务器查询数据库的次数. JWT 的最大缺点是,由于服务器不保存 session 状态,因此无法在使用过程中废止某个 token,或者更改 token 的权限.也就是说,一旦 JWT 签发了,在到期之前就会始终有效,除非服务器部署额外的逻辑. JWT 本身包含了认证信
-
Java 生成随机字符的示例代码
示例代码: import java.util.Random; import java.util.UUID; public class Dept { /** * 生成随机字符串 uuid */ public static String getUUID() { return UUID.randomUUID().toString(); } /** * 生成随机字符串 uuid 将"-"替换为"" */ public static String getUUNUM() { r
-
Java 获取网站图片的示例代码
目录 前提 一.新建Maven项目,导入Jsoup环境依赖 二.代码编写 心得: 前提 最近我的的朋友浏览一些网站,看到好看的图片,问我有没有办法不用手动一张一张保存图片! 我说用Jsoup丫! 测试网站 打开开发者模式(F12),找到对应图片的链接,在互联网中,每一张图片就是一个链接! 一.新建Maven项目,导入Jsoup环境依赖 <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> &l
-
Java实现中国象棋的示例代码
目录 前言 主要设计 功能截图 代码实现 总结 前言 中国象棋是起源于中国的一种棋,属于二人对抗性游戏的一种,在中国有着悠久的历史.由于用具简单,趣味性强,成为流行极为广泛的棋艺活动. 中国象棋使用方形格状棋盘,圆形棋子共有32个,红黑二色各有16个棋子,摆放和活动在交叉点上.双方交替行棋,先把对方的将(帅)“将死”的一方获胜. 中国象棋是一款具有浓郁中国特色的益智游戏,新增的联网对战,趣味多多,聚会可以约小朋友一起来挑战.精彩的对弈让你感受中国象棋的博大精深. <中国象棋>游戏是用java语
-
Java实现雪花算法的示例代码
一.介绍 SnowFlow算法是Twitter推出的分布式id生成算法,主要核心思想就是利用64bit的long类型的数字作为全局的id.在分布式系统中经常应用到,并且,在id中加入了时间戳的概念,基本上保持不重复,并且持续一种向上增加的方式. 在这64bit中,其中``第一个bit是不用的,然后用其中的41个bit作为毫秒数,用10bit作为工作机器id,12bit`作为序列号.具体如下图所示: 第一个部分:0,这个是个符号位,因为在二进制中第一个bit如果是1的话,那么都是负数,但是我们生成
-
Java实现俄罗斯方块游戏的示例代码
目录 引言 效果图 实现思路 代码实现 创建窗口 画布1 创建菜单及菜单选项 绘制游戏区域 画布2 画布2绘制一个小方块 创建图形 创建模型类 模型旋转变形 方块累计 方块消除和积分 加入自动向下线程,并启动 引言 俄罗斯方块,相信很多80.90后的小伙伴都玩过,也是当年非常火的游戏,当年读中学的时候,有一个同学有这个游戏机,大家都很喜欢玩,这个游戏给当时的我们带来了很多欢乐,时光飞逝,感慨颇多! 人终归是要长大的,回忆再美好,日子也一去不复返了,以前我们只会玩游戏,心里想自己能做一个出来多牛逼