Python基于pandas爬取网页表格数据
以网页表格为例:https://www.kuaidaili.com/free/
该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的。
今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定。
原网页结构如下:

python代码如下:
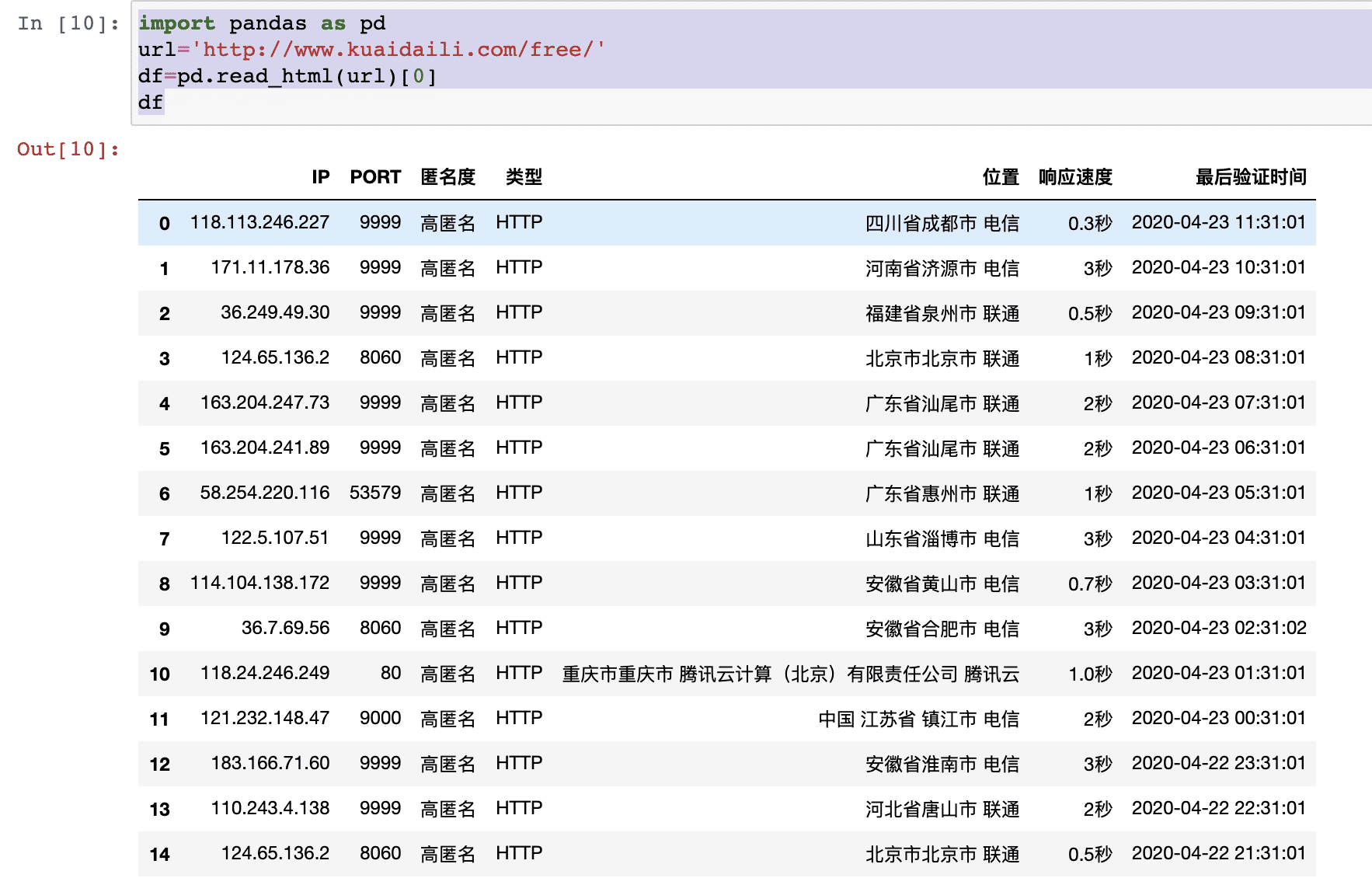
import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html(url)[0] # [0]:表示第一个table,多个table需要指定,如果不指定默认第一个 # 如果没有【0】,输入dataframe格式组成的list df
输出dataframe格式数据

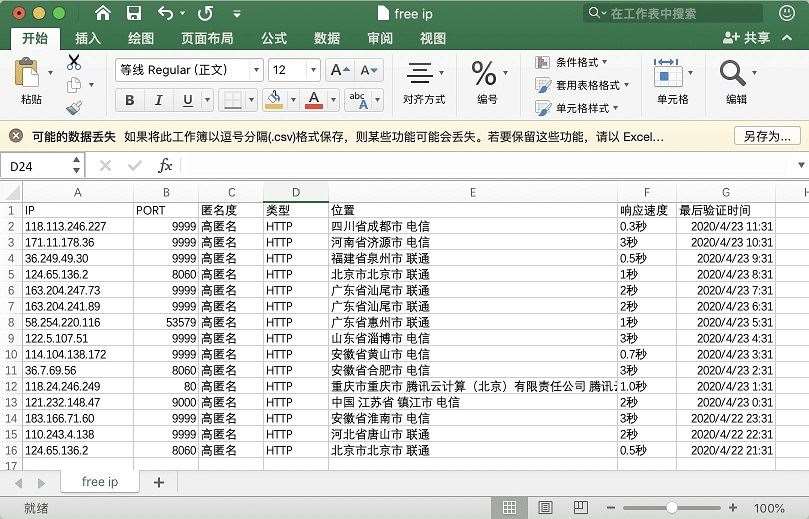
再次保存到本地,csv格式,注意中文编码:utf_8_sig
print(type(df))df.to_csv('free ip.csv',mode='a', encoding='utf_8_sig', header=1, index=0)print('done!')
查看csv文件
先来了解一下read_html函数的api:
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
常用的参数:
- io:可以是url、html文本、本地文件等;
- flavor:解析器;
- header:标题行;
- skiprows:跳过的行;
- attrs:属性,比如 attrs = {'id': 'table'};
- parse_dates:解析日期
注意:返回的结果是**DataFrame**组成的**list**。
若要dataframe,直接取list【0】
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python使用Pandas读写Excel实例解析
这篇文章主要介绍了Python使用Pandas读写Excel实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pandas是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. Pandas提供了大量能使我们快速便捷地处理数据的函数和方法. Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/ Pandas中文文档:https:/
-
python pandas移动窗口函数rolling的用法
超级好用的移动窗口函数 最近经常使用移动窗口函数,觉得很方便,功能强大,代码简单,故将pandas中的移动窗口函数都做介绍.它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能. rolling_count 计算各个窗口中非NA观测值的数量 函数 pandas.rolling_count(arg, window, freq=None, center=False, how=None) arg : DataFrame 或 numpy的ndarray 数组格式 window :
-
Python pandas库中的isnull()详解
问题描述 python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,我们通过几个例子学习它的使用方法. 首先我们创建一个dataframe,其中有一些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
浅谈python已知元素,获取元素索引(numpy,pandas)
目前搜索到的方法有: np.where('元素') 还有就是pandas的方法: df.index('元素') 但是第二个方法的问题就是会报错,嗯,这就比较尴尬了,查询了网上的解决方案,有这样的: 此外使用 df[df['列名'].isin([相应的值])] 这个命令会输出等于该值的行. 此外如果想快速找到dataframe最后几行的话,可以使用的方法是tail,可以获取若干行的值 以上这篇浅谈python已知元素,获取元素索引(numpy,pandas)就是小编分享给大家的全部内容了,希望能给
-
python pandas利用fillna方法实现部分自动填充功能
昨天,我们学习了pandas中的dropna方法,今天,学习一下fillna方法.该方法的主要作用是实现对NaN值的填充功能.该方法主要有3个参数,分别是:value,method,limit等.其余参数可以通过调用help函数获取信息. (1)value 该参数主要是确定填充数值 >>> df = pd.read_excel(r'D:/myExcel/1.xlsx') >>> df name Chinese Chinese.1 id 0 bob 12.0 12 123
-

Python pandas RFM模型应用实例详解
本文实例讲述了Python pandas RFM模型应用.分享给大家供大家参考,具体如下: 什么是RFM模型 根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有3个神奇的要素,这3个要素构成了数据分析最好的指标: 最近一次消费 (Recency): 客户最近一次交易时间的间隔.R值越大,表示客户交易距今越久,反之则越近: 消费频率 (Frequency): 客户在最近一段时间内交易的次数.F值越大,表示客户交易越频繁,反之则不够活跃: 消费金额 (Monetary): 客户
-
Python基于pandas爬取网页表格数据
以网页表格为例:https://www.kuaidaili.com/free/ 该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的. 今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定. 原网页结构如下: python代码如下: import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
python基于selenium爬取斗鱼弹幕
针对弹幕的爬取我们如果只需要获取看到的网页里面的而数据,使用selenium就能实现,对于直播平台来说,往往有第三方平台api让你获取数据(可以获取发弹幕,发弹幕者的名字礼物等等,这需要客户端向弹幕服务器发送登录请求,心跳信息的发送等等)只获取弹幕信息储存到txt文件中,上代码,上图片 代码如下: import time from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 使用headless无界
-
python爬虫之爬取谷歌趋势数据
一.前言 爬取谷歌趋势数据需要科学上网~ 二.思路 谷歌数据的爬取很简单,就是代码有点长.主要分下面几个就行了 爬取的三个界面返回的都是json数据.主要获取对应的token值和req,然后构造url请求数据就行 token值和req值都在这个链接的返回数据里.解析后得到token和req就行 socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了.全部代码如下 import socket import socks import requests import json im
-
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成 1)搜索要点 美团美食,地址:北京,搜索关键词:火锅 2)爬取的url https://bj.meituan.com/s/%E7%81%AB%E9%94%85/ 3)说明 url会有自动编码中文功能.所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85. 通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词. 这样我们就可以了解到当前url的构造. 2.分析页面数据来源(F12开发者工具) 开启F12开发
-
详解python定时简单爬取网页新闻存入数据库并发送邮件
本人小白一枚,简单记录下学校作业项目,代码十分简单,主要是对各个库的理解,希望能给别的初学者一点启发. 一.项目要求 1.程序可以从北京工业大学首页上爬取新闻内容:http://www.bjut.edu.cn 2.程序可以将爬取下来的数据写入本地MySQL数据库中. 3.程序可以将爬取下来的数据发送到邮箱. 4.程序可以定时执行. 二.项目分析 1.爬虫部分利用requests库爬取html文本,再利用bs4中的BeaultifulSoup库来解析html文本,提取需要的内容. 2.使用pymy
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
Python用requests-html爬取网页的实现
目录 1. 开始 2. 原理 3. 元素定位 css 选择器 4. CSS 简单规则 5. Xpath简单规则 6. 人性化操作 7. 加载 js 8. 总结 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是介绍 BeautifulSoup 这个库,我平常也是常用这个库,最近用 Xpath 用得比较多,使用 BeautifulSoup 就不大习惯,很久之前就知道 Reitz 大神出了一个叫 Requests
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题