利用Pandas索引和选取数据方法详解
目录
- 1. 导入数据集
- 2. 列选择
- 3. 行选择
- 数字Index
- 字符串Index
- 4. 行+列选择,找到元素
- 获取北汽2019年11月的销量
- 获取前5个品牌从2019年10月到12月的销量
- 5. 条件选择
- 6. 查找元素位置
- 在已知列中查找
- 在整个DataFrame中查找
我们将使用2019年全国新能源汽车的销量数据作为演示数据,数据保存在一个csv文件中,读者可以在GitHub仓库下载到 https://github.com/pythonlibrary/practice-pandas-skills.git
本篇文章中会使用到两个库pandas 和 numpy,确保它们都正确的安装,而工作环境则使用jupyter notebook,如果有需要学习如何搭建环境的,可以阅读 数据科学家的一种工作环境 – virtualenv和Jupyter Notebook。
文章中用于演示的代码也可以在前边提到的GitHub仓库中找到对应的notebook源文件,文件名为 index_select_data.ipynb
首先在notebook中导入pandas和numpy,按照常用习惯,pandas导入为pd,numpy导入为np
import pandas as pd import numpy as np
1. 导入数据集
在这一节中,我们会将数据文件导入为pandas中的数据对象,同时针对这个数据对象,做一些基本的信息展示,方便我们理解我们将要工作的数据。
我们的原始数据文件为csv格式,因此可以快速的使用pandas提供的read_csv方法将csv文件导入为pandas的DataFrame,同时利用DataFrame对象的head方法查看前两行数据的内容。
df = pd.read_csv('NEV_sales.csv')
df.head(2)
head方法接收一个整数为参数,代表,我们想要获得的行数,默认为5行,这里我们获得了2行,可以看出,数据的索引(index)是数字,列(column)里边包含了品牌以及2019年从1月份到12月份的销售量。

为了后边演示,我们将利用df这个数据集再创建一个新的数据集名为df_brand_index,它跟df的区别是,它将使用品牌(brand)作为索引,列为2019年从1月份到12月份的销售量。我们使用set_index方法来实现。这次,我们使用跟head方法相对应的tail方法来查看df_brand_index和df的不同。
df_brand_index = df.set_index('brand')
df_brand_index.tail(2)

可以看出,输出的第一列名称brand相比其他列名称向下移了一点,它已经变成了索引,跟原来的索引不同,它具有索引名,即brand,但是所支持的操作方法跟索引是一致的。
另外,在输出中我们看到了两个有趣的信息,一是,最后一行品牌为总计,这表明我们的原始数据中最后一行是所有行的总计,在真正的数据分析中,它肯定会对结果有不好的影响,因此可以排除掉,而本文侧重于pandas的操作,因此它对我们没影响,二是,奔驰品牌在2019年每个月的销量都是NaN,NaN是pandas中的一个特殊值,代表缺失值,而在我们这个数据集中,其实也就是销量为0。
接下来我们从3个方面简单的看看我们的数据。
首先是数据量,我们正在分析多大的量的数据呢,DataFrame的shape属性会告诉我们数据有多少行,多少列。通过下述代码获取到df_brand_index和df的形状。
df_brand_index.shape, df.shape

对于df,总过有77行,15列,而df_brand_index有77行,14列因为我们将品牌列转换为了索引,所以少了一列。
然后是数据类型,我们的数据中是否有一些非法数据类型,我们分析的是新能源车销量,因此,期望所有的数据都是数字,而非字符串或者其他,DataFrame的dtypes属性会告诉我们这样的信息。
df_brand_index.dtypes

没问题,所有的列都是数字(因为类型都是float64),如果有任一列出现了 object字样,那就是说该列包含非数字的内容。
最后是销售量的基本信息,例如每个月的销售量的最大,最小,平均值等等,使用DataFrame的describe()方法可以或者到这些信息。
df_brand_index.describe()

比如,2019年11月,新能源车在所有品牌的平均销量为3831台,最大为72795台(不合理,对吧?),为什么呢,记得我们前边使用了tail方法看到数据的最后一行为总计,因此这个最大值其实就是总计的值。
2. 列选择
我们尽量避免使用列索引的称呼,因为如果看英文文档的话,pandas并不使用column index来称呼列,而是直接使用column,如果称呼列索引的话恐怕会带来歧义。
通过方括号[]可以从DataFrame获取到某一列或者某几列的数据。这里注意:如果我们获取多列的数据,则得到的仍然是一个DataFrame,而如果我们仅获取一列数据,将会得到一个Series(跟DataFrame同一等级的pandas对象,也是pandas中的另外一种常用的数据结构)
sr_brand_index = df_brand_index['2019-11'] sr_brand_index.head(2)

上边,我们获取了2019年11月的销量数据,查看内容发现,索引名称还是为品牌,但是列没有了名称。
而下方,我们获取了2019年11月和12月两个月的销量数据,查看内容发现,不仅索引名称在,同样的DataFrame具有两列,分别对应两个月的数据。
df_brand_index[['2019-12', '2019-11']].head(2)

3. 行选择
这一节,我们将按行来选择数据。在pandas中最常用的,也是官方推荐的两种进行列选择的方法为loc和iloc,两者比较容易混淆,这里按照官方方法提供一个简单的快速记忆方法loc代表location,使用标签来定位, 而iloc中的i解读为integer,即integer location通过数字来定位。什么意思呢?看下边对比。
数字Index
首先我们使用df这个DataFrame,还记得吧,这个对象使用数字作为index,索引,我们来使用loc获取index标签从0到4的行:
df.loc[0:4]

我们最终得到了5行内容,而index为从0到4.
然后,我们来使用iloc获取index从位置0到位置4的行:
df.iloc[0:4]

这里大家发现了区别,我们仅仅得到了4行,index为从0到3,为什么呢,iloc代表利用整数编号来获取,其行为类似于python内置数据结构list的操作方法,获取到的结果为[0,4)。
到这里,或许读者已经有点晕了,别着急,看过下边这个例子以后,你就会恍然大悟,并明白为什么loc和iloc有时候很容易混淆。
字符串Index
我们再在df_brand_index上边使用loc和iloc来看看效果,还记得吧df_brand_index中的Index是品牌名称。
加入向上边一样,使用df_brand_index.loc[0:4]来获取前5行,那么我们会得到一个异常
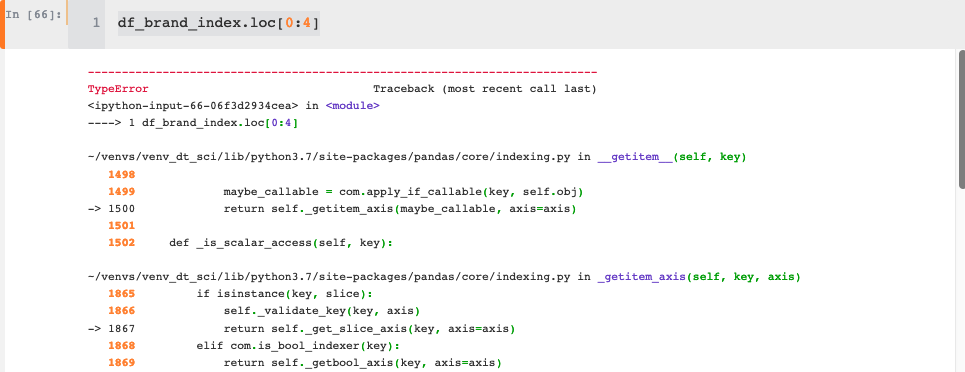
为什么呢?因为loc是使用标签来做选择,而这个数据集的Index标签为字符串而不是数字,正确的用法为:
df_brand_index.loc['北京':'宝骏']

然后iloc的用法就很容易理解并且显而易见了。
df_brand_index.iloc[0:4]

4. 行+列选择,找到元素
避免混淆,我们将继续使用df_brand_index来做演示。假如说现在我们想找到某北汽品牌在2019年11月的销量,或者前5个品牌在2019年10月到12月的销量,我们就需要结合行列来一起进行选择,pandas会智能的根据找到的元素的形状返回相应的数据类型,例如:
获取北汽2019年11月的销量
df_brand_index.loc['北京', '2019-11']

如果使用iloc方法,下边的方法可已得到等价的结果
df_brand_index.iloc[0, 1] # 1st column is 2019-11 in df_brand_index
获取前5个品牌从2019年10月到12月的销量
df_brand_index.loc['北京':'宝骏', '2019-12':'2019-10']

类似的使用iloc方法,下边的方法也可以得到等价的结果
df_brand_index.iloc[0:5, 0:3]
5. 条件选择
另外一个常用的数据选择筛选办法是根据元素的内容,比如,我们想获取到2019年11月和12月销量均大于3000台的品牌数据。
df_brand_index[(df_brand_index['2019-12'] > 3000) & (df_brand_index['2019-11'] > 3000)]

这里,我们使用了pandas的布尔选择功能,即在[]中提供一个布尔条件,(df_brand_index[‘2019-12'] > 3000) & (df_brand_index[‘2019-11'] > 3000)代表,11月和12月销量均大于3000,只得特别注意的是,条件中的括号非常重要,是一定需要使用的,否则,pandas将抛出异常。
6. 查找元素位置
最后,在实际项目中还会有需要通过某一个元素的值来寻找它在数据中出现的位置,例如我们想知道2019年11月销量为6046的品牌,或者我们想知道在整个DataFrame中销量为6046的所有品牌和对应的月份
在已知列中查找
如果我们想知道2019年11月销量为6046的品牌,我们完全可以使用第五节中的条件选择先选取到相应的数据,然后再使用DataFrame的index属性得到其对应的品牌。
df_brand_index[df_brand_index['2019-11']==6046].index

在整个DataFrame中查找
如果我们想知道在整个DataFrame中销量为6046的所有品牌和对应的月份,那么pandas提供的内建方法就无法满足这个要求了,我们可以借助numpy来快速实现。
numpy提供了where方法,它可以返回满足条件的元素在输入的numpy arry的行列位置编号,通过位置编号就可以在DataFrame中获取到品牌。
DataFrame中有一个to_numpy方法,可以将DataFrame转换为numpy array,将两部分连起来,就可以获得index和column的编号。
idx = np.where(df_brand_index.to_numpy()==6046)[0][0] col = np.where(df_brand_index.to_numpy()==6046)[1][0] idx, col
上边代码会输入(2,1)。其中2为index的编号,1为column编号,对应于df_brand_index中为:

更多关于Pandas的相关文章请查看下面的相关文章
相关推荐
-
pandas DataFrame 行列索引及值的获取的方法
pandas DataFrame是二维的,所以,它既有列索引,又有行索引 上一篇里只介绍了列索引: import pandas as pd df = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]}) print df # 结果: A B 0 0 3 1 1 4 2 2 5 行索引自动生成了 0,1,2 如果要自己指定行索引和列索引,可以使用 index 和 column 参数: 这个数据是5个车站10天内的客流数据: ridership_df = pd
-
pandas DataFrame的修改方法(值、列、索引)
对于DataFrame的修改操作其实有很多,不单单是某个部分的值的修改,还有一些索引的修改.列名的修改,类型修改等等.我们仅选取部分进行介绍. 一.值的修改 DataFrame的修改方法,其实前面介绍loc方法的时候介绍了一些. 1. loc方法修改 loc方法实际上是定位某个位置的数据的,但是定位完以后就可以对此位置的数据进行修改,使用此方法可以对DataFrame进行的修改如下: 1.对某行.某N行进行修改: 2.对某列.某N列进行修改: 3.对横坐标为某行或某N行,纵坐标为某列或者某N列的
-
Pandas之DataFrame对象的列和索引之间的转化
约定: import pandas as pd DataFrame对象的列和索引之间的转化 我们常常需要将DataFrame对象中的某列或某几列作为索引,或者将索引转化为对象的列.pandas提供了set_index()/reset_index() 来供我们使用. 一.列转化为索引 df1=pd.DataFrame({'X':range(5),'Y':range(5),'S':list("aaabb"),'Z':[1,1,2,2,2]}) df1 代码结果: S X Y Z 0 a 0
-
Pandas时间序列基础详解(转换,索引,切片)
时间序列的类型: 时间戳:具体的时刻 固定的时间区间:例如2007年的1月或整个2010年 时间间隔:由开始时间和结束时间表示,时间区间可以被认为是间隔的特殊情况 实验时间和消耗时间:每个时间是相对于特定开始时间的时间的量度,(例如自从被放置在烤箱中每秒烘烤的饼干的直径) 日期和时间数据的类型及工具 datetime模块中的类型: date 使用公历日历存储日历日期(年,月,日) time 将时间存储为小时,分钟,秒,微秒 datetime 存储日期和时间 timedelta 表示两个datet
-
Pandas之ReIndex重新索引的实现
约定: import pandas as pd import numpy as np ReIndex重新索引 reindex()是pandas对象的一个重要方法,其作用是创建一个新索引的新对象. 一.对Series对象重新索引 se1=pd.Series([1,7,3,9],index=['d','c','a','f']) se1 代码结果: d 1 c 7 a 3 f 9 dtype: int64 调用reindex将会重新排序,缺失值则用NaN填补. se2=se1.
-

Python Pandas 获取列匹配特定值的行的索引问题
给定一个带有列"BoolCol"的DataFrame,如何找到满足条件"BoolCol" == True的DataFrame的索引 目前有迭代的方式来做到这一点: for i in range(100,3000): if df.iloc[i]['BoolCol']== True: print i,df.iloc[i]['BoolCol'] 这虽然可行,但不是标准的 Pandas 方式.经过一番研究,我目前正在使用这个代码: df[df['BoolCol'] == T
-
利用Pandas索引和选取数据方法详解
目录 1. 导入数据集 2. 列选择 3. 行选择 数字Index 字符串Index 4. 行+列选择,找到元素 获取北汽2019年11月的销量 获取前5个品牌从2019年10月到12月的销量 5. 条件选择 6. 查找元素位置 在已知列中查找 在整个DataFrame中查找 我们将使用2019年全国新能源汽车的销量数据作为演示数据,数据保存在一个csv文件中,读者可以在GitHub仓库下载到 https://github.com/pythonlibrary/practice-pandas-sk
-
对python pandas 画移动平均线的方法详解
数据文件 66001_.txt 内容格式: date,jz0,jz1,jz2,jz3,jz4,jz5 2012-12-28,0.9326,0.8835,1.0289,1.0027,1.1067,1.0023 2012-12-31,0.9435,0.8945,1.0435,1.0031,1.1229,1.0027 2013-01-04,0.9403,0.8898,1.0385,1.0032,1.1183,1.0030 ... ... pd_roll_mean1.py # -*- coding: u
-
利用OpenCV实现YOLO对象检测方法详解
目录 前言 什么是YOLO物体检测器? 项目结构 检测图像 检测视频 前言 本文将教你如何使用YOLOV3对象检测器.OpenCV和Python实现对图像和视频流的检测.用到的文件有yolov3.weights.yolov3.cfg.coco.names,这三个文件的github链接如下: GitHub - pjreddie/darknet: Convolutional Neural Networks https://pjreddie.com/media/files/yolov3.weights
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
javascript解析json格式的数据方法详解
JSON (JavaScript Object Notation)是一种简单的数据格式,比xml更轻巧. 它是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包.那么如何用JavaScript来解析json呢? 首先,科普一下json.在json中,有两种结构:对象和数组. 一个对象以"{"(左括号)开始,"}"(右括号)结束.每个"名称"后跟一个":"
-
Java利用StampedLock实现读写锁的方法详解
目录 概述 StampedLock介绍 演示例子 性能对比 总结 概述 想到读写锁,大家第一时间想到的可能是ReentrantReadWriteLock.实际上,在jdk8以后,java提供了一个性能更优越的读写锁并发类StampedLock,该类的设计初衷是作为一个内部工具类,用于辅助开发其它线程安全组件,用得好,该类可以提升系统性能,用不好,容易产生死锁和其它莫名其妙的问题.本文主要和大家一起学习下StampedLock的功能和使用. StampedLock介绍 StampedLock的状态
-
对python3 Serial 串口助手的接收读取数据方法详解
其实网上已经有许多python语言书写的串口,但大部分都是python2写的,没有找到一个合适的python编写的串口助手,只能自己来写一个串口助手,由于我只需要串口能够接收读取数据就可以了,故而这个串口助手只实现了数据的接收读取. 创建串口助手首先需要创建一个类,重构类的实现过程如下: #coding=gb18030 import threading import time import serial class ComThread: def __init__(self, Port='COM3
-
python pandas修改列属性的方法详解
使用astype如下: df[[column]] = df[[column]].astype(type) type即int.float等类型. 示例: import pandas as pd data = pd.DataFrame([[1, "2"], [2, "2"]]) data.columns = ["one", "two"] print(data) # 当前类型 print("----\n修改前类型:&quo
-
python更新数据库中某个字段的数据(方法详解)
连接数据库基本操作,我把每一步的操作是为什么给大家注释一下,老手自行快进. 请注意这是连接数据库操作,还不是更新. import pymysql #导包 #连接数据库 db = pymysql.connect(host='localhost', user='用户名', password='数据库密码', port=3306, db='你的数据库名字') #定义游标 cursor = db.cursor() #sql语句 sql = 'select * from students;' cursor
-
js 数组当前行添加数据方法详解
需求:1.点击新增一栏商品信息,表单验证区分 2.输入SKU编码,带出当前行的产品名称,品牌及单位 解决: 到此这篇关于js 数组当前行添加数据方法详解的文章就介绍到这了,更多相关js 数组当前行添加数据方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!