python DataFrame中stack()方法、unstack()方法和pivot()方法浅析
目录
- 1.stack()
- 2. unstack()
- 3. pivot()
- 总结
1.stack()
stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦:
准备一组数据,给其设置双索引。
import pandas as pd
data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324],
['B类', 'b1', 112, 412, 466], ['B类', 'b2', 224, 235, 345], ['B类', 'b3', 369, 214, 352],
['C类', 'c1', 236, 251, 485], ['C类', 'c2', 378, 216, 515], ['C类', 'c3', 135, 421, 312],
['D类', 'd1', 306, 325, 496], ['D类', 'd2', 147, 235, 524], ['D类', 'd3', 520, 222, 267]]
df = pd.DataFrame(data=data, columns=['类别', '编号', 'A指标', 'B指标', 'C指标'])
df = df.set_index(['类别', '编号'])
print(df)

df = df.stack() print(df)

如图,成功将索引列之外的 A指标,B指标,C指标三列放在了同一列。
此时的df,不再是一个DataFrame,而变为了一个Series对象。:
print(type(df))

该Series的index列不同于原DataFrame的index列,而是在原DataFrame的index列的基础上,又增加了从右边合并过来的部分:
print(df.index)
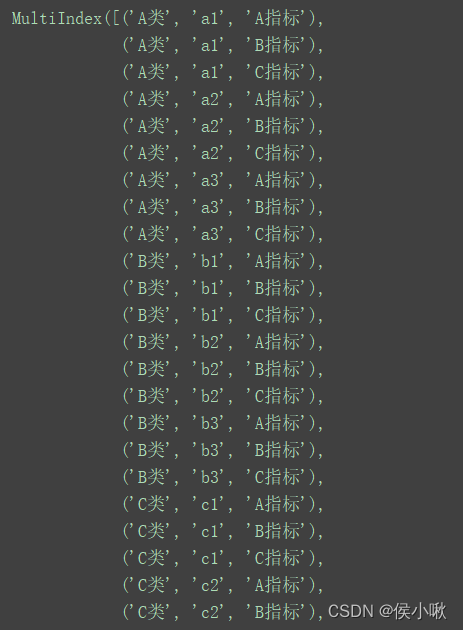
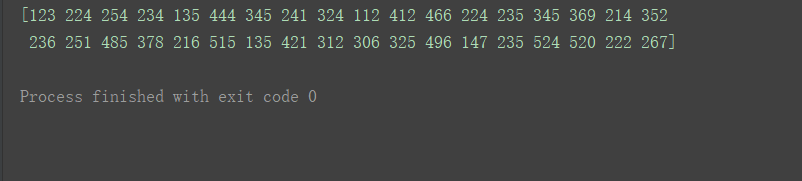
此时Values为:
print(df.values)
2. unstack()
unstack是stack的逆向操作。
在上述示例的代码的基础上,对上边的df继续调用unstack()方法:
df1 = df.unstack() print(df1)

可以看到unstack变回了原来的样子。
3. pivot()
这里对于上边例子中的数据稍作调整:
不设置多重索引
import pandas as pd
data = [['A类', '1', 123, 224, 254], ['A类', '2', 234, 135, 444], ['A类', '3', 345, 241, 324],
['B类', '1', 112, 412, 466], ['B类', '2', 224, 235, 345], ['B类', '3', 369, 214, 352],
['C类', '1', 236, 251, 485], ['C类', '2', 378, 216, 515], ['C类', '3', 135, 421, 312],
['D类', '1', 306, 325, 496], ['D类', '2', 147, 235, 524], ['D类', '3', 520, 222, 267]]
df = pd.DataFrame(data=data, columns=['类别', '编号', 'A指标', 'B指标', 'C指标'])
print(df)

df2 = df.pivot(index='编号', columns='类别', values='A指标') print(df2)

index和columns分别指设定那一列的值为index,设置那一列的值为columns。values指表格要体现的指标。
df3 = df.pivot(index='类别', columns='编号', values='A指标') print(df3)

总结
到此这篇关于python DataFrame中stack()方法、unstack()方法和pivot()方法的文章就介绍到这了,更多相关DataFrame stack()、unstack()和pivot()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas.DataFrame的pivot()和unstack()实现行转列
示例:有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings import filterwarnings # 由于create table if not exists总会抛出warning,因此使用filterwarnings消除 filterwarnings('ignore', category = MySQLdb.Warning) from sqlalchemy im
-

python DataFrame中stack()方法、unstack()方法和pivot()方法浅析
目录 1.stack() 2. unstack() 3. pivot() 总结 1.stack() stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦: 准备一组数据,给其设置双索引. import pandas as pd data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324], ['B类', 'b1', 112, 412, 46
-
在Python dataframe中出生日期转化为年龄的实现方法
我们在做数据挖掘项目或大数据竞赛时,如果个体是人的时候,获得的数据中可能有出生日期的Series,举个简单例子,比如这样的一些数: # -*- coding: utf-8 -*- import pandas as pd from pandas import Series, DataFrame import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline data = {'bi
-
Java线程中的常见方法(start方法和run方法)
目录 start方法和run方法 示例代码 注意 sleep方法与yield方法 sleep yield 线程优先级 sleep的应用-防止cpu占用100% join方法 有实效的等待 interrupt方法 打断正常运行的线程,不会清空打断状态 守护线程 start方法和run方法 $start()$方法用来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到$cpu$时间片,就开始执行$run()$方法.而直接调用$run()$方法,仅仅只是调用了一个类里的方法,其本质上还
-
python字典setdefault方法和get方法使用实例
这篇文章主要介绍了python字典setdefault方法和get方法使用实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在python的字典对象中,可以直接使用键名获取键值,像这样: >>> d = {"x":1,"y":2} >>> d["x"] >>> d["y"] >>> 但如果键名不存在,则
-
AngularJS中$apply方法和$watch方法用法总结
本文实例总结了AngularJS中$apply方法和$watch方法用法.分享给大家供大家参考,具体如下: 引言 最近在项目中封装控件的时候用到了$watch方法来监听module中的值的变化,当时小编对这个方法不是很了解,所以在网上找了一些资料来学习一下,下面小编就给大家简单介绍一些AngularJS中Scope 提供$apply 方法传播Model 的变化和$watch方法监听module变化. $apply使用情景 AngularJS 外部的控制器(DOM 事件.外部的回调函数如 jQue
-
js中scrollTop()方法和scroll()方法用法示例
本文实例讲述了js中scrollTop()方法和scroll()方法用法.分享给大家供大家参考,具体如下: 设置滚动条据顶部的高度: $("div").scrollTop(100); //把 scroll top offset 设置为 100px 获得滚动条的高度: $("div").scrollTop()://获得 scroll top offset 触发滚动事件 $(selector).scroll() 将函数绑定到滚动事件中: $(selector).scro
-
区分ASP.NET中get方法和post方法
在网页设计中,无论是动态还是静态,get方法是默认的,它在URL地址长度是有限的,所以get请求方法能传送的数据也是有限的,一般get方法能传递256字节的数据,当get请求方法传递的数据长度不能满足需求时,就需要采用另一种请求方法post,post方法可传递的数据最大值为2mb相应地,读取post方法传递过来的数据时,需要采用form方法来获取:post方法在aspx页面执行时,地址栏看不到传送过来的参数数据,更加有利于页面的安全,所以一般情况采用post方法传送页面数据. 这里举个简单的例子
-
asp.net TemplateField模板中的Bind方法和Eval方法
比如我们要取个日期型的数据,在数据库中列名是updated,数值是2008/06/01.但是想2008年06月01日这样显示,我们可以这样来写Bind("updated", "{0:yyyy年MM月dd日}"),Eval也是如此. 2者都能读取数据中的值,并显示.当我们使用编辑更新操作时,Bind能够自动的将修改的值更新到数据库中,并显示出修改后的值.但是用了Eval却只能得到错误画面,新的数据没有更新到数据库中. 从这点看来,Bind方法和Eval方法的区别就是:
-
JQuery中attr方法和removeAttr方法用法实例
本文实例讲述了JQuery中attr方法和removeAttr方法用法.分享给大家供大家参考.具体如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"
-
jquery中live()方法和bind()方法区别分析
本文实例讲述了jquery中live()方法和bind()方法区别.分享给大家供大家参考,具体如下: live()不受加载时间顺序的影响,只要查找能够配对上就能够绑定对应的事件,而bind方法只有在第一次被加载的时候才绑定时间,如果代码之后再加载配对的元素,则不能绑定对应的事件 $("#manual_disconnect").live("click", function(){ connectionProfile("0"); }); $("