CentOS7安装GlusterFS集群的全过程
目录
- 环境说明:
- 服务器:
- client:
- 安装:
- 配置 GlusterFS 集群:
- 查看集群状态:
- 创建数据存储目录:
- 查看volume 状态:
- 创建GlusterFS磁盘:
- GlusterFS 几种volume 模式说明:
- 再查看 volume 状态:
- gluster 性能调优:
- 测试:
- 其他的维护命令:
- 总结
CentOS 7 GlusterFS

环境说明:
3台机器安装 GlusterFS 组成一个集群。
使用 docker volume plugin GlusterFS
服务器:
10.6.0.140
10.6.0.192
10.6.0.196
配置 hosts
10.6.0.140 swarm-manager
10.6.0.192 swarm-node-1
10.6.0.196 swarm-node-2
client:
10.6.0.94 node-94
安装:
CentOS 安装 glusterfs 非常的简单
在三个节点都安装glusterfs
yum install centos-release-gluster yum install -y glusterfs glusterfs-server glusterfs-fuseglusterfs-rdma
配置 GlusterFS 集群:
启动 glusterFS
systemctl start glusterd.service systemctl enable glusterd.service
在 swarm-manager 节点上配置,将 节点 加入到 集群中。
[root@swarm-manager ~]#gluster peer probe swarm-manager peer probe: success. Probe on localhost not needed [root@swarm-manager ~]#gluster peer probe swarm-node-1 peer probe: success. [root@swarm-manager ~]#gluster peer probe swarm-node-2 peer probe: success.
查看集群状态:
[root@swarm-manager ~]#gluster peer status Number of Peers: 2 Hostname: swarm-node-1 Uuid: 41573e8b-eb00-4802-84f0-f923a2c7be79 State: Peer in Cluster (Connected) Hostname: swarm-node-2 Uuid: da068e0b-eada-4a50-94ff-623f630986d7 State: Peer in Cluster (Connected)
创建数据存储目录:
[root@swarm-manager ~]#mkdir -p /opt/gluster/data [root@swarm-node-1 ~]# mkdir -p /opt/gluster/data [root@swarm-node-2 ~]# mkdir -p /opt/gluster/data
查看volume 状态:
[root@swarm-manager ~]#gluster volume info No volumes present
创建GlusterFS磁盘:
[root@swarm-manager ~]#gluster volume create models replica 3 swarm-manager:/opt/gluster/data swarm-node-1:/opt/gluster/data swarm-node-2:/opt/gluster/data force volume create: models: success: please start the volume to access data
GlusterFS 几种volume 模式说明:
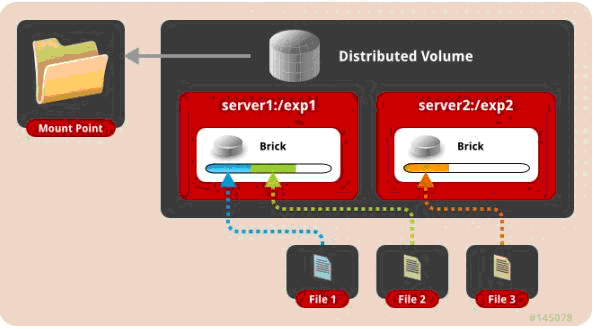
一、 默认模式,既DHT, 也叫 分布卷: 将文件已hash算法随机分布到 一台服务器节点中存储。
gluster volume create test-volume server1:/exp1 server2:/exp2
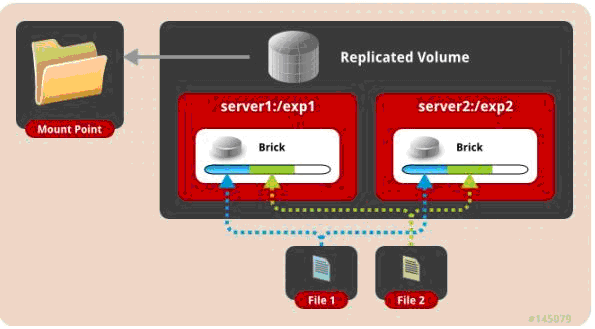
二、 复制模式,既AFR, 创建volume 时带 replica x 数量: 将文件复制到 replica x 个节点中。
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2
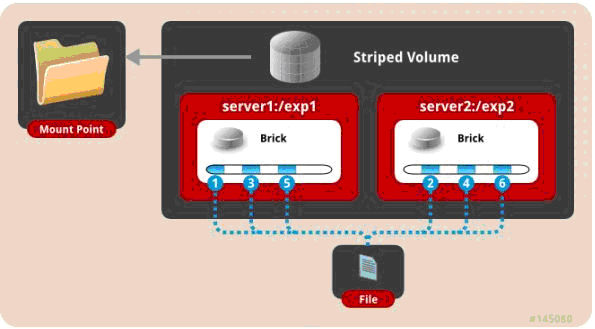
三、 条带模式,既Striped, 创建volume 时带 stripe x 数量: 将文件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2
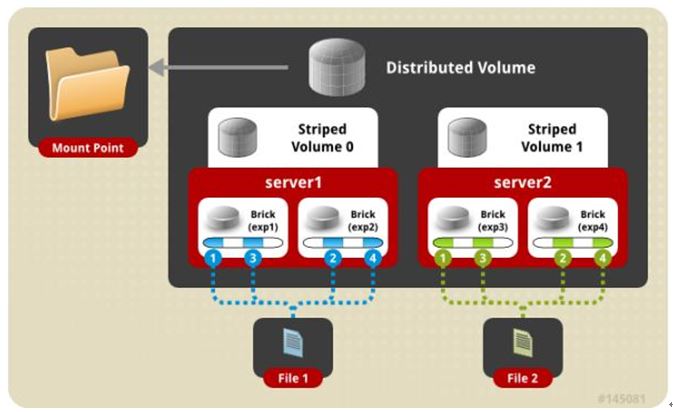
四、 分布式条带模式(组合型),最少需要4台服务器才能创建。 创建volume 时 stripe 2 server = 4 个节点: 是DHT 与 Striped 的组合型。
gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
五、 分布式复制模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 replica 2 server = 4 个节点:是DHT 与 AFR 的组合型。
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
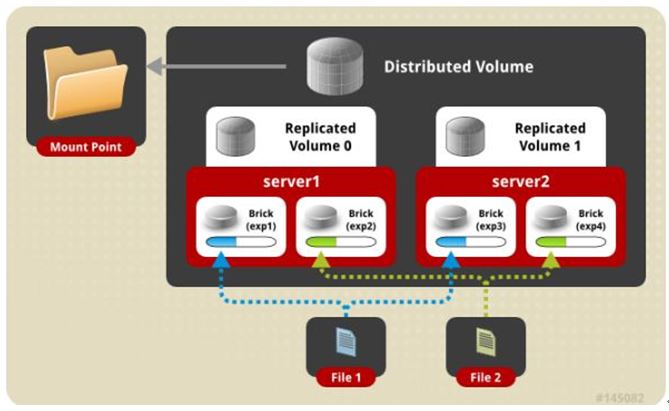
六、 条带复制卷模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 stripe 2 replica 2 server = 4 个节点: 是 Striped 与 AFR 的组合型。
gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4

七、 三种模式混合, 至少需要8台 服务器才能创建。 stripe 2 replica 2 , 每4个节点 组成一个 组。
gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8

再查看 volume 状态:
[root@swarm-manager ~]#gluster volume info Volume Name: models Type: Replicate Volume ID: e539ff3b-2278-4f3f-a594-1f101eabbf1e Status: Created Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: swarm-manager:/opt/gluster/data Brick2: swarm-node-1:/opt/gluster/data Brick3: swarm-node-2:/opt/gluster/data Options Reconfigured: performance.readdir-ahead: on
启动 models
[root@swarm-manager ~]#gluster volume start models volume start: models: success
gluster 性能调优:
开启 指定 volume 的配额: (models 为 volume 名称)
gluster volume quota models enable
限制 models 中 / (既总目录) 最大使用 80GB 空间
gluster volume quota models limit-usage / 80GB #设置 cache 4GB gluster volume set models performance.cache-size 4GB #开启 异步 , 后台操作 gluster volume set models performance.flush-behind on #设置 io 线程 32 gluster volume set models performance.io-thread-count 32 #设置 回写 (写数据时间,先写入缓存内,再写入硬盘) gluster volume set models performance.write-behind on
部署GlusterFS客户端并mount GlusterFS文件系统 (客户端必须加入 glusterfs hosts 否则报错。)
[root@node-94 ~]#yum install -y glusterfs glusterfs-fuse [root@node-94 ~]#mkdir -p /opt/gfsmnt [root@node-94 ~]#mount -t glusterfs swarm-manager:models /opt/gfsmnt/ [root@node-94 ~]#df -h 文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/vg001-root 98G 1.2G 97G 2% / devtmpfs 32G 0 32G 0% /dev tmpfs 32G 0 32G 0% /dev/shm tmpfs 32G 130M 32G 1% /run tmpfs 32G 0 32G 0% /sys/fs/cgroup /dev/mapper/vg001-opt 441G 71G 370G 17% /opt /dev/sda2 497M 153M 344M 31% /boot tmpfs 6.3G 0 6.3G 0% /run/user/0 swarm-manager:models 441G 18G 424G 4% /opt/gfsmnt
测试:
DHT 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1 记录了1+0 的读入 记录了1+0 的写出 1048576000字节(1.0 GB)已复制,9.1093 秒,115 MB/秒 real 0m9.120s user 0m0.000s sys 0m1.134s
AFR 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello.txt bs=1024M count=1 录了1+0 的读入 记录了1+0 的写出 1073741824字节(1.1 GB)已复制,27.4566 秒,39.1 MB/秒 real 0m27.469s user 0m0.000s sys 0m1.065s
Striped 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1 记录了1+0 的读入 记录了1+0 的写出 1048576000字节(1.0 GB)已复制,9.10669 秒,115 MB/秒 real 0m9.119s user 0m0.001s sys 0m0.953s
条带复制卷模式 (Number of Bricks: 1 x 2 x 2 = 4) 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1 记录了1+0 的读入 记录了1+0 的写出 1048576000字节(1.0 GB)已复制,17.965 秒,58.4 MB/秒 real 0m17.978s user 0m0.000s sys 0m0.970s
分布式复制模式 (Number of Bricks: 2 x 2 = 4) 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=haha bs=100M count=10 记录了10+0 的读入 记录了10+0 的写出 1048576000字节(1.0 GB)已复制,17.7697 秒,59.0 MB/秒 real 0m17.778s user 0m0.001s sys 0m0.886s
针对 分布式复制模式还做了如下测试:
4K随机写 测试:
安装 fio (yum -y install libaio-devel (否则运行fio 会报错engine libaio not loadable, 已安装需重新编译,否则一样报错))
[root@node-94 ~]#fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randwrite -size=10G -filename=1.txt -name="EBS 4KB randwrite test" -iodepth=32 -runtime=60 write: io=352204KB, bw=5869.9KB/s, iops=1467, runt= 60002msec WRITE: io=352204KB, aggrb=5869KB/s, minb=5869KB/s, maxb=5869KB/s, mint=60002msec, maxt=60002msec
4K随机读 测试:
fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randread -size=10G -filename=1.txt -name="EBS 4KB randread test" -iodepth=8 -runtime=60 read: io=881524KB, bw=14692KB/s, iops=3672, runt= 60001msec READ: io=881524KB, aggrb=14691KB/s, minb=14691KB/s, maxb=14691KB/s, mint=60001msec, maxt=60001msec
512K 顺序写 测试:
fio -ioengine=libaio -bs=512k -direct=1 -thread -rw=write -size=10G -filename=512.txt -name="EBS 512KB seqwrite test" -iodepth=64 -runtime=60 write: io=3544.0MB, bw=60348KB/s, iops=117, runt= 60135msec WRITE: io=3544.0MB, aggrb=60348KB/s, minb=60348KB/s, maxb=60348KB/s, mint=60135msec, maxt=60135msec
其他的维护命令:
1. 查看GlusterFS中所有的volume:
[root@swarm-manager ~]#gluster volume list
2. 删除GlusterFS磁盘:
[root@swarm-manager ~]#gluster volume stop models #停止名字为 models 的磁盘 [root@swarm-manager ~]#gluster volume delete models #删除名字为 models 的磁盘
注: 删除 磁盘 以后,必须删除 磁盘( /opt/gluster/data ) 中的 ( .glusterfs/ .trashcan/ )目录。
否则创建新 volume 相同的 磁盘 会出现文件 不分布,或者 类型 错乱 的问题。
3. 卸载某个节点GlusterFS磁盘
[root@swarm-manager ~]#gluster peer detach swarm-node-2
4. 设置访问限制,按照每个volume 来限制
[root@swarm-manager ~]#gluster volume set models auth.allow 10.6.0.*,10.7.0.*
5. 添加GlusterFS节点:
[root@swarm-manager ~]#gluster peer probe swarm-node-3 [root@swarm-manager ~]#gluster volume add-brick models swarm-node-3:/opt/gluster/data
注:如果是复制卷或者条带卷,则每次添加的Brick数必须是replica或者stripe的整数倍
6. 配置卷
[root@swarm-manager ~]# gluster volume set
7. 缩容volume:
先将数据迁移到其它可用的Brick,迁移结束后才将该Brick移除:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data start
在执行了start之后,可以使用status命令查看移除进度:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data status
不进行数据迁移,直接删除该Brick:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit
注意,如果是复制卷或者条带卷,则每次移除的Brick数必须是replica或者stripe的整数倍。
扩容:
gluster volume add-brick models swarm-node-2:/opt/gluster/data
8. 修复命令:
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit -force
9. 迁移volume:
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data start pause 为暂停迁移 [root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data pause abort 为终止迁移 [root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data abort status 查看迁移状态 [root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data status 迁移结束后使用commit 来生效 [root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit
10. 均衡volume:
[root@swarm-manager ~]#gluster volume models lay-outstart [root@swarm-manager ~]#gluster volume models start [root@swarm-manager ~]#gluster volume models startforce [root@swarm-manager ~]#gluster volume models status [root@swarm-manager ~]#gluster volume models stop
总结
到此这篇关于CentOS7安装GlusterFS集群的文章就介绍到这了,更多相关CentOS7安装GlusterFS内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
在centos 7中安装配置k8s集群的步骤详解
配置背景介绍 kubernetes是google开源的容器集群管理系统,提供应用部署.维护.扩展机制等功能,利用kubernetes能方便管理跨集群运行容器化的应用,简称:k8s(k与s之间有8个字母) 为什么要用kubernetes这么复杂的docker集群管理工具呢?一开始接触了docker内置的swarm,这个工具非常简单快捷的完成docker集群功能.但是在使用docker1.13内置的swarm做集群的时候遇到vip负载均衡没有正确映射端口到外网,或者出现地址被占用的情况,这对高可用性
-
centos系统安装Kubernetes集群步骤
目录 前言 1.安装Docker 2.安装Kubernetes 1.基本环境 2.安装kubelet.kubeadm.kubectl(三台机器全部都要设置) 3.初始化master节点 3.安装Calico网络插件 4.加入worker节点 5.验证 总结 前言 安装前请准备选择4核8G(master).8核16G(node1).8核16G(node2) 三台机器,按量付费进行实验,CentOS7.9 这里的机器默认都是干净的,建议租云上的机器,差不多一个小时3块钱,自己搭虚拟机也行 云上机器v
-
在CentOS中安装Rancher2并配置kubernetes集群的图文教程
准备 一台CentOS主机,安装DockerCE,用于安装Rancher2 一台CentOS主机,安装DockerCE,用于安装kubernetes集群管理主机 多台CentOS主机,安装DockerCE,用于运行kubernetes工作节点,工作节点需要与集群管理主机在同一个子网中 掌握Docker常用操作,了解K8s基本原理 安装Rancher2 第一步:执行命令,运行Rancher2,绑定主机端口80和443. docker run -d --restart=unless-stopped
-
CentOS 7下安装 redis 3.0.6并配置集群的过程详解
安装依赖 [root@centos7-1 ~]# yum -y install gcc openssl-devel libyaml-devel libffi-devel readline-devel zlib-devel gdbm-devel ncurses-devel gcc-c++ automake autoconf 安装 redis [root@centos7-1 ~]# wget http://download.redis.io/releases/redis-3.0.6.tar.gz [
-

CentOS7安装GlusterFS集群的全过程
目录 环境说明: 服务器: client: 安装: 配置 GlusterFS 集群: 查看集群状态: 创建数据存储目录: 查看volume 状态: 创建GlusterFS磁盘: GlusterFS 几种volume 模式说明: 再查看 volume 状态: gluster 性能调优: 测试: 其他的维护命令: 总结 CentOS 7 GlusterFS 环境说明: 3台机器安装 GlusterFS 组成一个集群. 使用 docker volume plugin GlusterFS 服务器: 10
-
docker安装pxc集群的详细教程
前言 现在mysql自建集群方案有多种,keepalived.MHA.PXC.MYSQL主备等,但是目前根据自身情况和条件,选择使用pxc的放来进行搭建,最大的好处就是,多主多备,即主从一体,没有同步延时问题,方便易用. 本人使用过,直接安装pxc和docker容器方式的安装,个人觉得docker下安装更为方便,也更易维护,所以也推荐大家使用此方式. 搭建环境 环境 centos7 pxc版本镜像:最新版,目前为8.0+ 主机ip 部署 swarm 172.16.9.40 pxc1 manage
-
kubernetes存储之GlusterFS集群详解
目录 1.glusterfs概述 1.1.glusterfs简介 1.2.glusterfs特点 1.3.glusterfs卷的模式 2.heketi概述 3.部署heketi+glusterfs 3.1.准备工作 3.1.1.所有节点安装glusterfs客户端 3.1.2.节点打标签 3.1.3.所有节点加载对应模块 3.2.创建glusterfs集群 3.2.1.下载相关安装文件 3.2.2.创建集群 3.2.3.查看gfs pods 3.3.创建heketi服务 3.3.1.创建heke
-
Linux(Centos7)下redis5集群搭建和使用说明详解
1.简要说明 2018年十月 Redis 发布了稳定版本的 5.0 版本,推出了各种新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli的方式,是集群的构建方式复杂度大大降低.关于集群的更新可以在 Redis5 的版本说明中看到,如下: The cluster manager was ported from Ruby (redis-trib.rb) to C code inside redis-cli. check `redis-cli --cluster h
-
Redis自动化安装及集群实现搭建过程
Redis实例安装 安装说明:自动解压缩安装包,按照指定路径编译安装,复制配置文件模板到Redis实例路的数据径下,根据端口号修改 配置文件模板 配置文件,当前shell脚本,安装包 参数1:basedir,redis安装包路径 参数2:安装实例路径 参数3:安装包名称 参数4:安装实例的端口号 #!/bin/bash set -e if [ $# -lt 4 ]; then echo "$(basename $0): Missing script argument" echo &qu
-
Linux下安装Hadoop集群详细步骤
目录 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件 3.使文件生效 4.进入Hadoop目录下 5.编辑配置文件 6.进入slaves添加主节点和从节点 7.将各个文件复制到其他虚拟机上 8.格式化hadoop (仅在主节点中进行操作) 9.回到Hadoop目录下(仅在主节点操作) 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件
-
关于docker compose安装redis集群的问题(集群扩容、集群收缩)
目录 一.redis 配置信息模板 二.编写批量生成配置文件脚本 三.批量生成配置文件 四.编写 docker-compose 文件 五.做集群.分配插槽 六.测试: 七.手动扩容 八.添加主从节点 1.添加主节点 2.添加从节点 九.分配插槽 十.集群测试 十一.常用命令 一.redis 配置信息模板 文件名:redis-cluster.tmpl # redis端口 port ${PORT} #redis 访问密码 requirepass 123456 #redis 访问Master节点密码
-
在AWS-EC2中安装Minikube集群的详细过程
目录 一.启动EC2实例(Ubantu) 1.选择实例镜像 2.选择实例类型 3.添加存储(最低10GiB) 4.添加标签(可选) 5.添加安全组(按需求开放端口) 6.核验并启动实例 7.查看实例 二.登录到实例 1.打开SecureCRT 2.导入密钥 3.连接实例 三.安装kubectl(Ubuntu用户非root) 四.安装Docker(ubuntu用户) 五.安装并查看MiniKube 1.安装conntrack(root 用户) 2.安装minikube 六.启动miniKube并检
-
在redhat6.4安装redis集群【教程】
参考: http://redis.io/topics/cluster-tutorial(主要是Creating a Redis Cluster using the create-cluster script部分) https://ruby.taobao.org/ 安装一款不熟悉的软件前先看INSTALL,README,这是习惯,生产上要建立普通用户并调节适当参数,下面是以root身份安装运行. 下载解压并安装redis make test提示需要更高版本的tcl,跳到安装过程可能遇到的问题 wg
-
Redis集群的离线安装步骤及原理详析
前言 本文主要是记录一下Redis集群在linux系统下离线的安装步骤,毕竟在生产环境下一般都是无法联网的,Redis的集群的Ruby环境安装过程还是很麻烦的,涉及到很多的依赖的安装,所以写了一个文章来进行记录.本文分为两部分,第一部分先通过原生命令的安装来实现redis集群的部署,通过原生命令的安装对于了解redis集群的实现原理有很大的帮助,第二部分通过官方工具Ruby来进行Redis集群的安装,通过Ruby安装Redis集群的时候主要是搭建好Ruby环境,真正Redis集群的安装配置通过R