Oracle中的instr()函数应用及使用详解
1、instr()函数的格式 (俗称:字符查找函数)
格式一:instr( string1, string2 ) // instr(源字符串, 目标字符串)
格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) // instr(源字符串, 目标字符串, 起始位置, 匹配序号)
解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2。
注:在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。只检索一次,也就是说从字符的开始到字符的结尾就结束。
2、实例
格式一
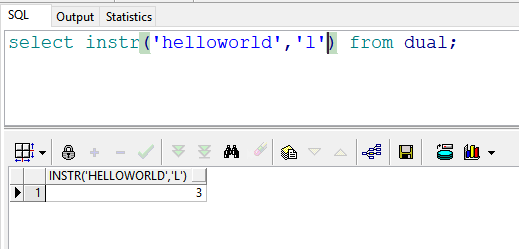
select instr('helloworld','l') from dual; --返回结果:3 默认第一次出现“l”的位置
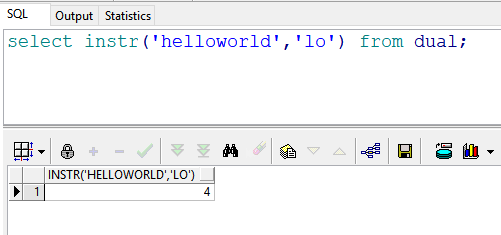
select instr('helloworld','lo') from dual; --返回结果:4 即“lo”同时(连续)出现,“l”的位置
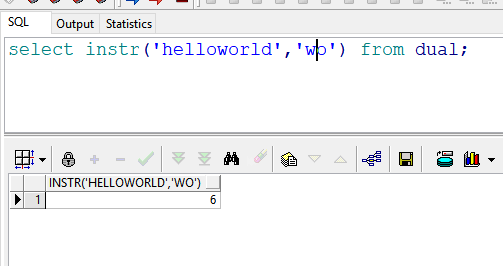
select instr('helloworld','wo') from dual; --返回结果:6 即“w”开始出现的位置
格式二
select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
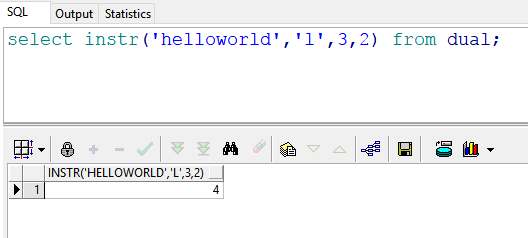
select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第二次出现的“l”的位置
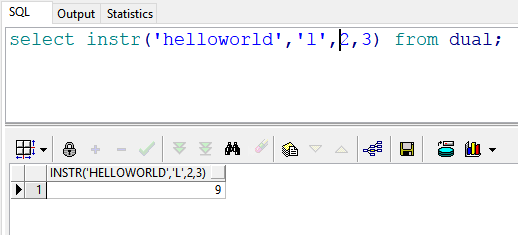
select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
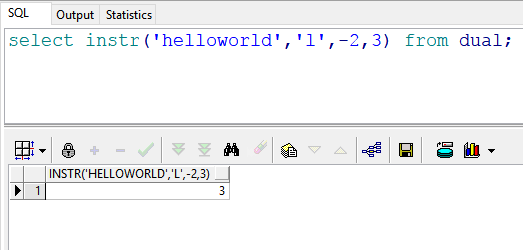
select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置
注:MySQL中的模糊查询 like 和 Oracle中的 instr() 函数有同样的查询效果; 如下所示:
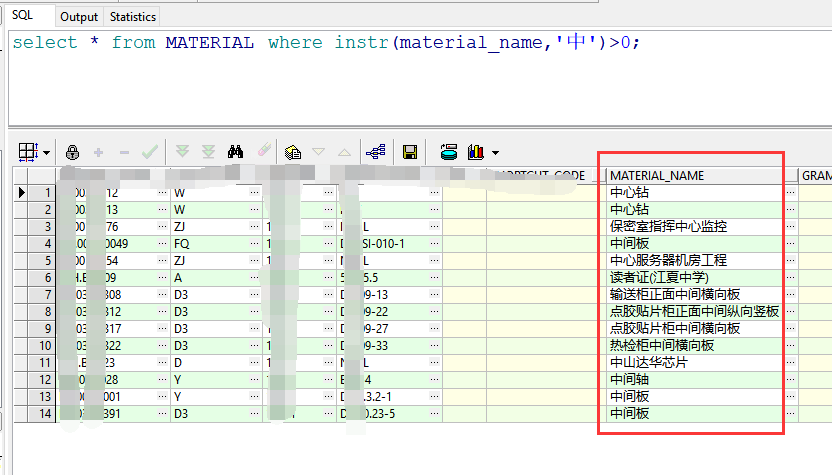
MySQL: select * from tableName where name like '%helloworld%'; Oracle:select * from tableName where instr(name,'helloworld')>0; --这两条语句的效果是一样的

3、实例截图
1、
2、
3、
4、

5、
6、

7、
8、
9、

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
oracle截取字符(substr)检索字符位置(instr)示例介绍
一:理论 oracle 截取字符(substr),检索字符位置(instr) case when then else end语句使用 收藏 常用函数:substr和instr 1.SUBSTR(string,start_position,[length]) 求子字符串,返回字符串 解释:string 元字符串 start_position 开始位置(从0开始) length 可选项,子字符串的个数 For example: substr("ABCDEFG", 0); //返回:ABCD
-
Oracle中Like与Instr模糊查询性能大比拼
instr(title,'手册')>0 相当于 title like '%手册%' instr(title,'手册')=1 相当于 title like '手册%' instr(title,'手册')=0 相当于 title not like '%手册%' t表中将近有1100万数据,很多时候,我们要进行字符串匹配,在SQL语句中,我们通常使用like来达到我们搜索的目标.但经过实际测试发现,like的效率与instr函数差别相当大.下面是一些测试结果: SQL> set timing on
-
Oracle中instr函数使用方法
INSTR (源字符串, 目标字符串, 起始位置, 匹配序号) 在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置.只检索一次,就是说从字符的开始到字符的结尾就结束. 语法如下: instr( string1, string2 [, start_position [, nth_appearance ] ] ) 参数分析: string1 源字符串,要在此字符串中查找. string2 要在string1中查找的字符串. start_position 代表string
-
Oracle的substr和instr函数简单用法
Oracle的substr函数简单用法 substr(字符串,截取开始位置,截取长度) //返回截取的字 substr('Hello World',0,1) //返回结果为 'H' *从字符串第一个字符开始截取长度为1的字符串 substr('Hello World',1,1) //返回结果为 'H' *0和1都是表示截取的开始位置为第一个字符 substr('Hello World',2,4) //返回结果为 'ello' substr('Hello World',-3,3)//返回结果为
-
oracle使用instr或like方法判断是否包含字符串
首先想到的就是contains,contains用法如下: select * from students where contains(address, 'beijing') 但是,使用contains谓词有个条件,那就是列要建立索引,也就是说如果上面语句中students表的address列没有建立索引,那么就会报错. 好在我们还有另外一个办法,那就是使用instr,instr的用法如下: select * from students where instr(address, 'beijing
-
Oracle中的INSTR,NVL和SUBSTR函数的用法详解
Oracle中INSTR的用法: INSTR方法的格式为 INSTR(源字符串, 要查找的字符串, 从第几个字符开始, 要找到第几个匹配的序号) 返回找到的位置,如果找不到则返回0. 例如:INSTR('CORPORATE FLOOR','OR', 3, 2)中,源字符串为'CORPORATE FLOOR', 在字符串中查找'OR',从第三个字符位置开始查找"OR",取第三个字后第2个匹配项的位置. 默认查找顺序为从左到右.当起始位置为负数的时候,从右边开始查找. 所以SELECT I
-
SQL中Charindex和Oracle中对应的函数Instr对比
sql :charindex('字符串',字段)>0 charindex('administrator',MUserID)>0 oracle:instr(字段,'字符串',1,1) >0 instr(MUserID,'administrator',1,1)>0 在项目中用到了Oracle中 Instr 这个函数,顺便仔细的再次学习了一下这个知识. Oracle中,可以使用 Instr 函数对某个字符串进行判断,判断其是否含有指定的字符. 其语法为: Instr(string, su
-
Oracle中instr和substr存储过程详解
instr和substr存储过程,分析内部大对象的内容 instr函数 instr函数用于从指定的位置开始,从大型对象中查找第N个与模式匹配的字符串. 用于查找内部大对象中的字符串的instr函数语法如下: dbms_lob.instr( lob_loc in blob, pattern in raw, offset in integer := 1; nth in integer := 1) return integer; dbms_lob.instr( lob_loc in clob char
-
Oracle中的instr()函数应用及使用详解
1.instr()函数的格式 (俗称:字符查找函数) 格式一:instr( string1, string2 ) // instr(源字符串, 目标字符串) 格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) // instr(源字符串, 目标字符串, 起始位置, 匹配序号) 解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检
-
ES6中Array.copyWithin()函数的用法实例详解
ES6为Array增加了copyWithin函数,用于操作当前数组自身,用来把某些个位置的元素复制并覆盖到其他位置上去. Array.prototype.copyWithin(target, start = 0, end = this.length) 该函数有三个参数. target:目的起始位置. start:复制源的起始位置,可以省略,可以是负数. end:复制源的结束位置,可以省略,可以是负数,实际结束位置是end-1. 例: 把第3个元素(从0开始)到第5个元素,复制并覆盖到以第1个位置
-
对python中矩阵相加函数sum()的使用详解
假如矩阵A是n*n的矩阵 A.sum()是计算矩阵A的每一个元素之和. A.sum(axis=0)是计算矩阵每一列元素相加之和. A.Sum(axis=1)是计算矩阵的每一行元素相加之和. 以上这篇对python中矩阵相加函数sum()的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数 1.交叉验证(Cross-validation) 交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和.这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型. 下图所示 2.StratifiedShuffleSplit函数的使用 官方文档 用法: from sklearn.
-
Oracle中分组查询group by用法规则详解
Oracle中group by用法 在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回的是每一个组的汇总信息. 使用having子句 限制返回的结果集.group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果. 在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包
-
oracle中去掉回车换行空格的方法详解
去除换行update zhzl_address t set t.add_administration_num=replace(t.add_administration_num,chr(10),'');去掉回车update zhzl_address t set t.add_administration_num=replace(t.add_administration_num,chr(13),'');去掉空格update zhzl_address t set t.add_administration
-

Oracle中直方图对执行计划的影响详解
前言 大家应该都知道,在Oracle数据库中,CBO会默认目标列的数据在其最小值low_value和最大值high_value之间均匀分布,并按照均匀分布原则,来计算目标列 施加查询条件后的可选择率以及结果集的cardinality. 如果对目标收集了直方图,则意味着CBO不再认为目标列上的数据是均匀分布的.CBO会用该列上的直方图的统计信息计算返回结果集的cardinality. 验证直方图对执行计划的影响步骤: 1.创建一张表T1 2.往表中插入倾斜度很高的数据 3.在B字段上创建索引 4.
-
oracle合并列的函数wm_concat的使用详解
oracle wm_concat(column)函数使我们经常会使用到的,下面就教您如何使用oracle wm_concat(column)函数实现字段合并,如果您对oracle wm_concat(column)函数使用方面感兴趣的话,不妨一看.shopping:-----------------------------------------u_id goods num------------------------------------------1
-
Oracle中的半联结和反联结详解
当两张表进行联结的时候,如果表1中的数据行是否出现在结果集中需要根据表2中出现或不出现至少一个相匹配的数据行来判断,这种情况就会发生半联结:而反联结便是半联结的补集,它们会作为数据库中常见的联结方法如NESTED LOOPS,MERGE SORT JOIN,HASH JOIN的选项出现. 实际上半联结和反联结本身也可以被认同是两种联结方法:在CBO优化模式下,优化器能够根据实际情况灵活的转换执行语句从而实现半联结和反联结方法,毕竟没有什么SQL语法可以显式的调用半联结和反联结,它们只是SQL语句
-
C语言中关于scanf函数的一些问题详解
在学习创建二叉树时遇到了scanf的一些问题,在此记录下来 创建根节点A后理想情况是输入A的左子树,若不为空继续创建左子树,但输入A后发现重复创建了一个左子树,测试后发现输入A换行后scanf函数接收了换行符(ASCII码10) 若想按次序创建各个节点则需要使用getchar()吸收换行符 不接收换行符也可以输入一个完整的二叉树序列,也可以成功创建. void CreateBiTree(BiTree &T) { char ch, temp; scanf("%c", &c