Pytorch 神经网络—自定义数据集上实现教程
第一步、导入需要的包
import os import scipy.io as sio import numpy as np import torch import torch.nn as nn import torch.backends.cudnn as cudnn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms, utils from torch.autograd import Variable
batchSize = 128 # batchsize的大小 niter = 10 # epoch的最大值
第二步、构建神经网络
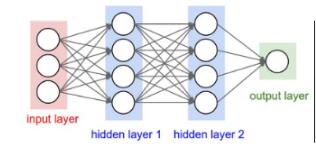
设神经网络为如上图所示,输入层4个神经元,两层隐含层各4个神经元,输出层一个神经。每一层网络所做的都是线性变换,即y=W×X+b;代码实现如下:
class Neuralnetwork(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Neuralnetwork, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
model = Neuralnetwork(1*3, 4, 4, 1)
print(model) # net architecture
Neuralnetwork( (layer1): Linear(in_features=3, out_features=4, bias=True) (layer2): Linear(in_features=4, out_features=4, bias=True) (layer3): Linear(in_features=4, out_features=1, bias=True) )
第三步、读取数据
自定义的数据为demo_SBPFea.mat,是MATLAB保存的数据格式,其存储的内容如下:包括fea(1000*3)和sbp(1000*1)两个数组;fea为特征向量,行为样本数,列为特征宽度;sbp为标签
class SBPEstimateDataset(Dataset):
def __init__(self, ext='demo'):
data = sio.loadmat(ext+'_SBPFea.mat')
self.fea = data['fea']
self.sbp = data['sbp']
def __len__(self):
return len(self.sbp)
def __getitem__(self, idx):
fea = self.fea[idx]
sbp = self.sbp[idx]
"""Convert ndarrays to Tensors."""
return {'fea': torch.from_numpy(fea).float(),
'sbp': torch.from_numpy(sbp).float()
}
train_dataset = SBPEstimateDataset(ext='demo')
train_loader = DataLoader(train_dataset, batch_size=batchSize, # 分批次训练
shuffle=True, num_workers=int(8))
整个数据样本为1000,以batchSize = 128划分,分为8份,前7份为104个样本,第8份则为104个样本。在网络训练过程中,是一份数据一份数据进行训练的
第四步、模型训练
# 优化器,Adam
optimizer = optim.Adam(list(model.parameters()), lr=0.0001, betas=(0.9, 0.999),weight_decay=0.004)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.997)
criterion = nn.MSELoss() # loss function
if torch.cuda.is_available(): # 有GPU,则用GPU计算
model.cuda()
criterion.cuda()
for epoch in range(niter):
losses = []
ERROR_Train = []
model.train()
for i, data in enumerate(train_loader, 0):
model.zero_grad()# 首先提取清零
real_cpu, label_cpu = data['fea'], data['sbp']
if torch.cuda.is_available():# CUDA可用情况下,将Tensor 在GPU上运行
real_cpu = real_cpu.cuda()
label_cpu = label_cpu.cuda()
input=real_cpu
label=label_cpu
inputv = Variable(input)
labelv = Variable(label)
output = model(inputv)
err = criterion(output, labelv)
err.backward()
optimizer.step()
losses.append(err.data[0])
error = output.data-label+ 1e-12
ERROR_Train.extend(error)
MAE = np.average(np.abs(np.array(ERROR_Train)))
ME = np.average(np.array(ERROR_Train))
STD = np.std(np.array(ERROR_Train))
print('[%d/%d] Loss: %.4f MAE: %.4f Mean Error: %.4f STD: %.4f' % (
epoch, niter, np.average(losses), MAE, ME, STD))
[0/10] Loss: 18384.6699 MAE: 135.3871 Mean Error: -135.3871 STD: 7.5580 [1/10] Loss: 17063.0215 MAE: 130.4145 Mean Error: -130.4145 STD: 7.8918 [2/10] Loss: 13689.1934 MAE: 116.6625 Mean Error: -116.6625 STD: 9.7946 [3/10] Loss: 8192.9053 MAE: 89.6611 Mean Error: -89.6611 STD: 12.9911 [4/10] Loss: 2979.1340 MAE: 52.5410 Mean Error: -52.5279 STD: 15.0930 [5/10] Loss: 599.7094 MAE: 22.2735 Mean Error: -19.9979 STD: 14.2069 [6/10] Loss: 207.2831 MAE: 11.2394 Mean Error: -4.8821 STD: 13.5528 [7/10] Loss: 189.8173 MAE: 9.8020 Mean Error: -1.2357 STD: 13.7095 [8/10] Loss: 188.3376 MAE: 9.6512 Mean Error: -0.6498 STD: 13.7075 [9/10] Loss: 186.8393 MAE: 9.6946 Mean Error: -1.0850 STD: 13.6332
以上这篇Pytorch 神经网络—自定义数据集上实现教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch中的自定义数据处理详解
pytorch在数据中采用Dataset的数据保存方式,需要继承data.Dataset类,如果需要自己处理数据的话,需要实现两个基本方法. :.getitem:返回一条数据或者一个样本,obj[index] = obj.getitem(index). :.len:返回样本的数量 . len(obj) = obj.len(). Dataset 在data里,调用的时候使用 from torch.utils import data import os from PIL import Image 数
-
pytorch 自定义数据集加载方法
pytorch 官网给出的例子中都是使用了已经定义好的特殊数据集接口来加载数据,而且其使用的数据都是官方给出的数据.如果我们有自己收集的数据集,如何用来训练网络呢?此时需要我们自己定义好数据处理接口.幸运的是pytroch给出了一个数据集接口类(torch.utils.data.Dataset),可以方便我们继承并实现自己的数据集接口. torch.utils.data torch的这个文件包含了一些关于数据集处理的类. class torch.utils.data.Dataset: 一个抽象类
-
PyTorch上实现卷积神经网络CNN的方法
一.卷积神经网络 卷积神经网络(ConvolutionalNeuralNetwork,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此CNN在
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
Pytorch 神经网络—自定义数据集上实现教程
第一步.导入需要的包 import os import scipy.io as sio import numpy as np import torch import torch.nn as nn import torch.backends.cudnn as cudnn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms, ut
-
pytorch加载语音类自定义数据集的方法教程
前言 pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.utils.data.Dataset:所有继承他的子类都应该重写 __len()__ , __getitem()__ 这两个方法 __len()__ :返回数据集中数据的数量 __getitem()__ :返回支持下标索引方式获取的一个数据 torch.utils.data.DataLoad
-
pytorch学习教程之自定义数据集
自定义数据集 在训练深度学习模型之前,样本集的制作非常重要.在pytorch中,提供了一些接口和类,方便我们定义自己的数据集合,下面完整的试验自定义样本集的整个流程. 开发环境 Ubuntu 18.04 pytorch 1.0 pycharm 实验目的 掌握pytorch中数据集相关的API接口和类 熟悉数据集制作的整个流程 实验过程 1.收集图像样本 以简单的猫狗二分类为例,可以在网上下载一些猫狗图片.创建以下目录: data-------------根目录 data/test-------测
-
使用 PyTorch 实现 MLP 并在 MNIST 数据集上验证方式
简介 这是深度学习课程的第一个实验,主要目的就是熟悉 Pytorch 框架.MLP 是多层感知器,我这次实现的是四层感知器,代码和思路参考了网上的很多文章.个人认为,感知器的代码大同小异,尤其是用 Pytorch 实现,除了层数和参数外,代码都很相似. Pytorch 写神经网络的主要步骤主要有以下几步: 1 构建网络结构 2 加载数据集 3 训练神经网络(包括优化器的选择和 Loss 的计算) 4 测试神经网络 下面将从这四个方面介绍 Pytorch 搭建 MLP 的过程. 项目代码地址:la
-

Python深度学习理解pytorch神经网络批量归一化
目录 训练深层网络 为什么要批量归一化层呢? 批量归一化层 全连接层 卷积层 预测过程中的批量归一化 使用批量归一化层的LeNet 简明实现 争议 训练深层神经网络是十分困难的,特别是在较短的实践内使他们收敛更加棘手.在本节中,我们将介绍批量归一化(batch normalization),这是一种流行且有效的技术,可持续加速深层网络的收敛速度.在结合之后将介绍的残差快,批量归一化使得研究人员能够训练100层以上的网络. 训练深层网络 为什么要批量归一化层呢? 让我们回顾一下训练神经网络时出现的
-
用Pytorch训练CNN(数据集MNIST,使用GPU的方法)
听说pytorch使用比TensorFlow简单,加之pytorch现已支持windows,所以今天装了pytorch玩玩,第一件事还是写了个简单的CNN在MNIST上实验,初步体验的确比TensorFlow方便. 参考代码(在莫烦python的教程代码基础上修改)如下: import torch import torch.nn as nn from torch.autograd import Variable import torch.utils.data as Data import tor
-
关于Pytorch的MNIST数据集的预处理详解
关于Pytorch的MNIST数据集的预处理详解 MNIST的准确率达到99.7% 用于MNIST的卷积神经网络(CNN)的实现,具有各种技术,例如数据增强,丢失,伪随机化等. 操作系统:ubuntu18.04 显卡:GTX1080ti python版本:2.7(3.7) 网络架构 具有4层的CNN具有以下架构. 输入层:784个节点(MNIST图像大小) 第一卷积层:5x5x32 第一个最大池层 第二卷积层:5x5x64 第二个最大池层 第三个完全连接层:1024个节点 输出层:10个节点(M
-
总结近几年Pytorch基于Imgagenet数据集图像分类模型
AlexNet (2012 ) 2012 年,AlexNet 由 Alex Krizhevsky 为 ImageNet 大规模视觉识别挑战赛 ( ILSVRV ) 提出的,ILSVRV 评估用于对象检测和图像分类的算法. AlexNet 总共由八层组成 其中前5层是卷积层,后3层是全连接层. 前两个卷积层连接到重叠的最大池化层以提取最大数量的特征. 第三.四.五卷积层直接与全连接层相连. 卷积层和全连接层的所有输出都连接到 ReLu 非线性激活函数. 最后的输出层连接到一个 softmax 激活
-
pytorch神经网络从零开始实现多层感知机
目录 初始化模型参数 激活函数 模型 损失函数 训练 我们已经在数学上描述了多层感知机,现在让我们尝试自己实现一个多层感知机.为了与我们之前使用softmax回归获得的结果进行比较,我们将继续使用Fashion-MNIST图像分类数据集. import torch from torch import nn from d2l import torch as d2l batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnis