通过微信公众平台获取公众号文章的方法示例
我之前自己维护了一个公众号,但因为个人关系很久没有更新了,今天上来缅怀一下,却偶然发现了一个获取微信公众号文章的方法。
之前获取方法有很多,通过搜狗、清博、网页端、客户端等等都还可以,这个可能并没有其他的优秀,但是操作简单,很容易理解。
so、 首先需要有一个微信公众平台的账号
微信公众平台:https://mp.weixin.qq.com/

登陆之后,进入首页,点击新建群发。

选择自建图文:

似乎像是公众号运营教学了
进入编辑页面之后,点击超链接

弹出选择框,我们在框中输入对应的公众号名字,即可出现对应的文章列表

是不是很惊奇,可以打开控制台,查看一下请求的接口
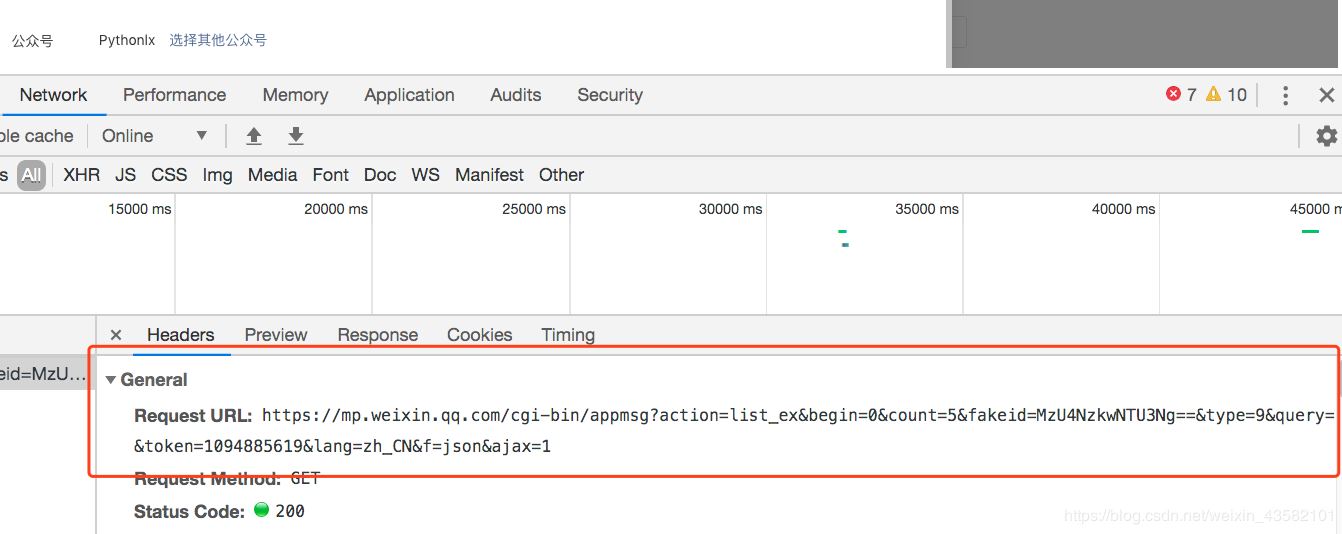
打开response,里面就是我们需要的文章链接

确定了数据以后,我们需要分析一下这个接口。
感觉很简单,一个GET请求,携带一些参数。

fakeid是公众号的独有ID,所以想通过名字直接获取文章列表,还需要先获取一下fakeid。
当我们输入公众号名字后,点击搜索。可以看到触发了搜索接口,返回了fakeid。

这个接口所需参数也不多。
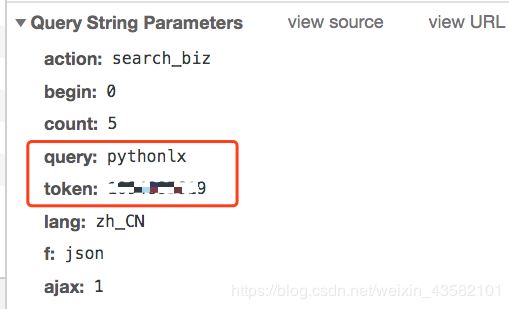
接下来,我们可以用代码来模拟以上的操作了。
但是还需要使用现有Cookie避免登陆。

目前Cookie的有效期,我还没有测试。可能需要及时更新Cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就能获取最新的10篇文章了,如果想要获取更多的历史文章,可以修改data中的"begin"参数,0是第一页,5是第二页,10是第三页(以此类推)
但是如果想要大规模抓取的话:
请给自己安排一个稳定的代理,降低爬虫的速度,准备多个账号,来减少被封禁的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python爬取指定微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 该方法是依赖于urllib2库来完成的,首先你需要安装好你的python环境,然后安装urllib2库 程序的起始方法(返回值是公众号文章列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面 url = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query=要爬取的公众号名
-

python爬取微信公众号文章的方法
最近在学习Python3网络爬虫开发实践(崔庆才 著)刚好也学习到他使用代理爬取公众号文章这里,但是照着他的代码写,出现了一些问题.在这里我用到了这本书的前面讲的一些内容进行了完善.(作者写这个代码已经是半年前的事了,但腾讯的网站在这半年前进行了更新) 下面我直接上代码: TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
-
python抓取搜狗微信公众号文章
初学python,抓取搜狗微信公众号文章存入mysql mysql表: 代码: import requests import json import re import pymysql # 创建连接 conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8') # 创建游标 cursor = conn.cursor() cursor.execute("sel
-
用好anyproxy提高公众号文章采集效率
影响因素主要会有以下几点: 1.网络环境不佳: 2.手机或模拟器中微信客户端崩溃: 3.其它一些网络传输错误: 因为我比较看重采集系统的运行成本,这个成本包括硬件投入,运算力投入和占用的人工精力.所以必须提高运行的稳定性.因此如果采集中断,必然增加人工精力的成本.所以针对这一点我对anyproxy做了一些进阶的改造,并且借助了其它一些工具提高了运行效率.以下就是具体的解决方法: 一.代码升级 1)微信浏览器白屏 解决方法:修改文件requestHandler.js,还是在rule_default
-
python下载微信公众号相关文章
本文实例为大家分享了python下载微信公众号相关文章的具体代码,供大家参考,具体内容如下 目的:从零开始学自动化测试公众号中下载"pytest"一系列文档 1.搜索微信号文章关键字搜索 2.对搜索结果前N页进行解析,获取文章标题和对应URL 主要使用的是requests和bs4中的Beautifulsoup Weixin.py import requests from urllib.parse import quote from bs4 import BeautifulSoup im
-
python爬取微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
-
python采集微信公众号文章
本文实例为大家分享了python采集微信公众号文章的具体代码,供大家参考,具体内容如下 在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py. 代码如下: 1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
-
PHP写微信公众号文章页采集方法
通过搜狗搜索采集公众号历史消息有几个问题: 1.有验证码: 2.历史消息列表只有最近10条群发内容: 3.文章地址是有有效期的: 4.据说批量采集还要换ip: 通过我前面文章的方法就没有这些问题,虽然采集系统搭建不如传统采集器写个规则去爬就可以了那么简单.但是一次搭建好之后批量采集的效率还是可以的.而且采集的文章地址是永久有效的,并且可以采集到一个公众号所有的历史消息. 我们还是从一个公众号文章的链接地址开始看: 1.从微信右上角菜单复制到的链接地址: http://mp.weixin.qq.c
-
微信小程序如何访问公众号文章
前言 随着小程序不断的发展,现在个人的小程序也开放了很多功能了,个人小程序直接打开公众号链接.在群里看到的一款小程序,点击可以直接阅读文章了,所以琢磨了一下,写了一些源码. 主要代码: <web-view src="https://mp.weixin.qq.com/s?__biz=MzI2ODUxMzg4Nw==&mid=2247485016&idx=1&sn=e5f60600ea30f669264ddcf5db4fb080&chksm=eaef2168dd
-
通过微信公众平台获取公众号文章的方法示例
我之前自己维护了一个公众号,但因为个人关系很久没有更新了,今天上来缅怀一下,却偶然发现了一个获取微信公众号文章的方法. 之前获取方法有很多,通过搜狗.清博.网页端.客户端等等都还可以,这个可能并没有其他的优秀,但是操作简单,很容易理解. so. 首先需要有一个微信公众平台的账号 微信公众平台:https://mp.weixin.qq.com/ 登陆之后,进入首页,点击新建群发. 选择自建图文: 似乎像是公众号运营教学了 进入编辑页面之后,点击超链接 弹出选择框,我们在框中输入对应的公众号名字,即
-
微信小程序获取公众号文章列表及显示文章的示例代码
微信小程序中如何打开公众号中的文章,步骤相对来说不麻烦. 1.公众号设置 小程序若要获取公众号的素材,公众号需要做一些设置. 1.1 绑定小程序 公众号需要绑定目标小程序,否则无法打开公众号的文章. 在公众号管理界面,点击小程序管理 --> 关联小程序 输入小程序的AppID搜索,绑定即可. 1.2 公众号开发者功能配置 (1) 在公众号管理界面,点击开发模块中的基本配置选项. (2) 开启开发者秘密(AppSecret),注意保存改秘密. (3) 设置ip白名单,这个就是发起请求的机器的外网i
-
Java微信公众平台开发(7) 公众平台测试帐号的申请
前面几篇一直都在写一些比较基础接口的使用,在这个过程中一直使用的都是我个人微博认证的一个个人账号,原本准备这篇是写[多媒体消息回复]的,后来主要到我个人账号的接口权限不够,所以在这里插入一篇[公众平台测试帐号的申请]的文章,同时也提醒各位开发者一定要注意在开发过程中需要注意接口权限,以防想当然的写完代码才发现接口不能使用,但是同样的我们也可以先预演接口的功能然后再将其应用到实际中! ①登入到微信公众平台,我们到[开发]-->[开发者工具]-->[公众平台测试账号]--进入: 首次进入可能会需要
-
php实现基于微信公众平台开发SDK(demo)扩展的方法
本文实例讲述了php实现基于微信公众平台开发SDK(demo)扩展的方法.分享给大家供大家参考.具体分析如下: 该扩展基于官方的微信公众平台SDK,这里只做了简单地封装,实现了一些基本的功能(如天气查询,翻译,自动聊天机器人,自定义菜单接口)仅供学习之用.代码如下: 复制代码 代码如下: define("TOKEN", "xingans"); $wechatObj = new wechatCallbackapiTest(); $wechatObj->respo
-
微信公众平台开发实现2048游戏的方法
本文实例讲述了微信公众平台开发实现2048游戏的方法.分享给大家供大家参考.具体如下: 一.2048游戏概述 <2048>是比较流行的一款数字游戏.原版2048首先在github上发布,原作者是Gabriele Cirulli.它是基于<1024>和<小3传奇>的玩法开发而成的新型数字游戏 . 随后2048便出现各种版本,走各大平台.由Ketchapp公司移植到IOS的版本最为火热,现在约有1000万下载,其名字跟原版一模一样.衍生版中最出名的是<2048六边形&
-
微信小程序获取用户openId的实现方法
微信小程序获取用户openId的实现方法 前端: wx.login({ success: function (res) { res.code }) 获取到code后,传到后台, 然后请求微信接口 https://api.weixin.qq.com/sns/jscode2session?appid=APPID&secret=SECRET&js_code=JSCODE&grant_type=authorization_code 把参数替换为自己的参数,这个接口就直接返回openId了
-
微信小程序获取手机网络状态的方法【附源码下载】
本文实例讲述了微信小程序获取手机网络状态的方法.分享给大家供大家参考,具体如下: 1.效果展示 2.关键代码 index.wxml布局文件代码 <view>手机网络状态:{{netWorkType}}</view> index.js逻辑文件代码 Page({ data: { netWorkType:'' }, onLoad: function () { var that=this wx.getNetworkType({ success: function(res) { that.s
-
浅谈使用Java Web获取客户端真实IP的方法示例详解
Java-Web获取客户端真实IP: 发生的场景:服务器端接收客户端请求的时候,一般需要进行签名验证,客户端IP限定等情况,在进行客户端IP限定的时候,需要首先获取该真实的IP. 一般分为两种情况: 方式一.客户端未经过代理,直接访问服务器端(nginx,squid,haproxy): 方式二.客户端通过多级代理,最终到达服务器端(nginx,squid,haproxy): 客户端请求信息都包含在HttpServletRequest中,可以通过方法getRemoteAddr()获得该客户端IP.
-
微信小程序转化为uni-app项目的方法示例
前言: 之前自己做一个uni-app的项目的时候前端需要实现一个比较复杂的动态tab和swiper切换的功能,但是由于自己前端抠脚的原因没有写出来,然后自己在网上搜索的时候发现了有个微信小程序里面的页面及极其的符合我的需求.那么问题来了我该如何将微信小程序转为为uni-app项目呢?搜索了下网上的相关解决方案还真有个将微信小程序转化为uni-app的项目,该项目名称叫做[miniprogram-to-uniapp],接下来就看看如何实操吧! miniprogram-to-uniapp项目介绍: