python神经网络使用tensorflow实现自编码Autoencoder
目录
- 学习前言
- antoencoder简介
- 1、为什么要降维
- 2、antoencoder的原理
- 3、python中encode的实现
- 全部代码
学习前言
当你发现数据的维度太多怎么办!没关系,我们给它降维!
当你发现不会降维怎么办!没关系,来这里看看怎么autoencode
antoencoder简介
1、为什么要降维
随着社会的发展,可以利用人工智能解决的越来越多,人工智能所需要处理的问题也越来越复杂,作为神经网络的输入量,维度也越来越大,也就出现了当前所面临的“维度灾难”与“信息丰富、知识贫乏”的问题。
维度太多并不是一件优秀的事情,太多的维度同样会导致训练效率低,特征难以提取等问题,如果可以通过优秀的方法对特征进行提取,将会大大提高训练效率。
常见的降维方法有PCA(主成分分析)和LDA(线性判别分析,Fisher Linear Discriminant Analysis),二者的使用方法我会在今后的日子继续写BLOG进行阐明。
2、antoencoder的原理
如图是一个降维的神经网络的示意图,其可以将n维数据量降维2维数据量:
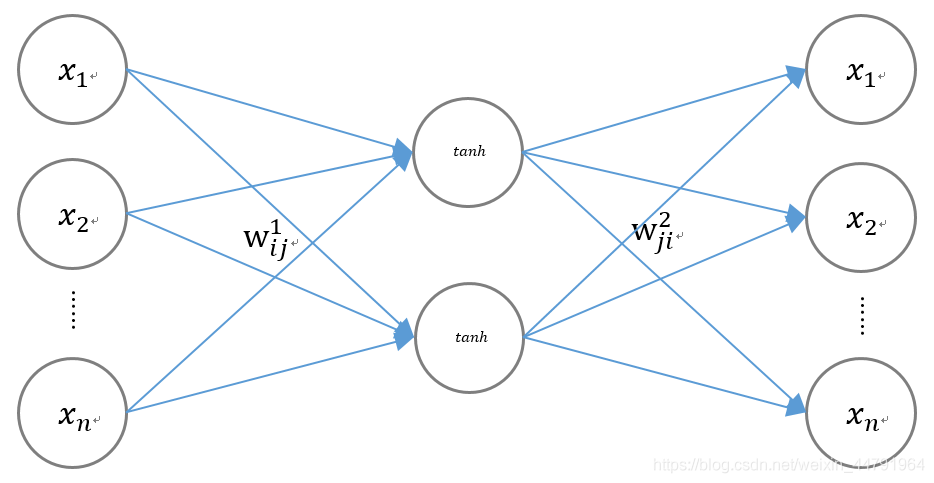
输入量与输出量都是数据原有的全部特征,我们利用tensorflow的optimizer对w1ij和w2ji进行优化。在优化的最后,w1ij就是我们将n维数据编码到2维的编码方式,w2ji就是我们将2维数据进行解码到n维数据的解码方式。
3、python中encode的实现
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
其中encode函数的输出就是编码后的结果。
全部代码
该例子为手写体识别例子,将784维缩小为2维,并且以图像的方式显示。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
learning_rate = 0.01 #学习率
training_epochs = 10 #训练十次
batch_size = 256
display_step = 1
examples_to_show = 10
n_input = 784
X = tf.placeholder(tf.float32,[None,n_input])
#encode的过程分为4次,分别是784->128、128->64、64->10、10->2
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
#这四个是用于encode的
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
#这四个是用于decode的
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
#这四个是用于encode的
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
#这四个是用于decode的
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
def encoder(x):
#encode函数,分为四步,layer4为编码后的结果
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
#decode函数,分为四步,layer4为解码后的结果
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
#将编码再解码的结果与原始码对比,查看区别
y_pred = decoder_op
y_label = X
#比较特征损失情况
cost = tf.reduce_mean(tf.square(y_pred-y_label))
train = tf.train.AdamOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#每个世代进行total_batch次训练
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
_,c = sess.run([train,cost],feed_dict={X:batch_xs})
if epoch % display_step == 0:
print("Epoch :","%02d"%epoch,"cost =","%.4f"%c)
#利用test测试机进行测试
encoder_result = sess.run(encoder_op,feed_dict={X:mnist.test.images})
plt.scatter(encoder_result[:,0],encoder_result[:,1],c=np.argmax(mnist.test.labels,1),s=1)
plt.show()
实现结果为:
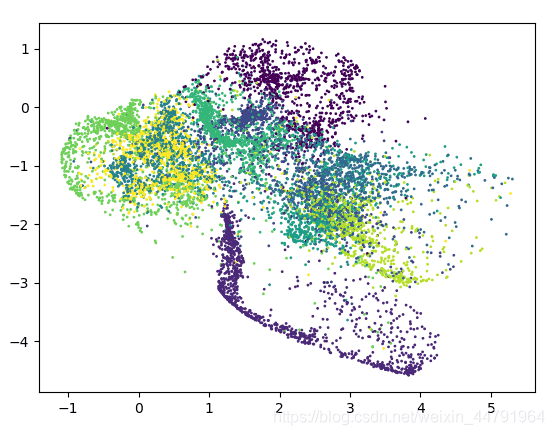
可以看到实验结果分为很多个区域块,基本可以识别。
以上就是python神经网络使用tensorflow实现自编码Autoencoder的详细内容,更多关于tensorflow自编码Autoencoder的资料请关注我们其它相关文章!
相关推荐
-
Python通过TensorFlow卷积神经网络实现猫狗识别
这份数据集来源于Kaggle,数据集有12500只猫和12500只狗.在这里简单介绍下整体思路 处理数据 设计神经网络 进行训练测试 1. 数据处理 将图片数据处理为 tf 能够识别的数据格式,并将数据设计批次. 第一步get_files() 方法读取图片,然后根据图片名,添加猫狗 label,然后再将 image和label 放到 数组中,打乱顺序返回 将第一步处理好的图片 和label 数组 转化为 tensorflow 能够识别的格式,然后将图片裁剪和补充进行标准化处理,分批次返回. 新建
-

TensorFlow实现AutoEncoder自编码器
一.概述 AutoEncoder大致是一个将数据的高维特征进行压缩降维编码,再经过相反的解码过程的一种学习方法.学习过程中通过解码得到的最终结果与原数据进行比较,通过修正权重偏置参数降低损失函数,不断提高对原数据的复原能力.学习完成后,前半段的编码过程得到结果即可代表原数据的低维"特征值".通过学习得到的自编码器模型可以实现将高维数据压缩至所期望的维度,原理与PCA相似. 二.模型实现 1. AutoEncoder 首先在MNIST数据集上,实现特征压缩和特征解压并可视化比较解压后的数
-
keras tensorflow 实现在python下多进程运行
如下所示: from multiprocessing import Process import os def training_function(...): import keras # 此处需要在子进程中 ... if __name__ == '__main__': p = Process(target=training_function, args=(...,)) p.start() 原文地址:https://stackoverflow.com/questions/42504669/ker
-
Python通过TensorFLow进行线性模型训练原理与实现方法详解
本文实例讲述了Python通过TensorFLow进行线性模型训练原理与实现方法.分享给大家供大家参考,具体如下: 1.相关概念 例如要从一个线性分布的途中抽象出其y=kx+b的分布规律 特征是输入变量,即简单线性回归中的 x 变量.简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征. 标签是我们要预测的事物,即简单线性回归中的 y 变量. 样本是指具体的数据实例.有标签样本是指具有{特征,标签}的数据,用于训练模型,总结规律.无标签样本只具有特征的数据x,通过
-
python用TensorFlow做图像识别的实现
一.TensorFlow简介 TensorFlow是由谷歌开发的一套机器学习的工具,使用方法很简单,只需要输入训练数据位置,设定参数和优化方法等,TensorFlow就可以将优化结果显示出来,节省了很大量的编程时间,TensorFlow的功能很多很强大,这边挑选了一个比较简单实现的方法,就是利用TensorFlow的逻辑回归算法对数据库中的手写数字做识别,让机器找出规律,然后再导入新的数字让机器识别. 二.流程介绍 上图是TensorFlow的流程,可以看到一开始要先将参数初始化,然后导入训练数
-
python 使用Tensorflow训练BP神经网络实现鸢尾花分类
Hello,兄弟们,开始搞深度学习了,今天出第一篇博客,小白一枚,如果发现错误请及时指正,万分感谢. 使用软件 Python 3.8,Tensorflow2.0 问题描述 鸢尾花主要分为狗尾草鸢尾(0).杂色鸢尾(1).弗吉尼亚鸢尾(2). 人们发现通过计算鸢尾花的花萼长.花萼宽.花瓣长.花瓣宽可以将鸢尾花分类. 所以只要给出足够多的鸢尾花花萼.花瓣数据,以及对应种类,使用合适的神经网络训练,就可以实现鸢尾花分类. 搭建神经网络 输入数据是花萼长.花萼宽.花瓣长.花瓣宽,是n行四列的矩阵. 而输
-
python神经网络使用tensorflow实现自编码Autoencoder
目录 学习前言 antoencoder简介 1.为什么要降维 2.antoencoder的原理 3.python中encode的实现 全部代码 学习前言 当你发现数据的维度太多怎么办!没关系,我们给它降维!当你发现不会降维怎么办!没关系,来这里看看怎么autoencode antoencoder简介 1.为什么要降维 随着社会的发展,可以利用人工智能解决的越来越多,人工智能所需要处理的问题也越来越复杂,作为神经网络的输入量,维度也越来越大,也就出现了当前所面临的“维度灾难”与“信息丰富.知识贫乏
-
python神经网络使用tensorflow构建长短时记忆LSTM
目录 LSTM简介 1.RNN的梯度消失问题 2.LSTM的结构 tensorflow中LSTM的相关函数 tf.contrib.rnn.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 LSTM简介 1.RNN的梯度消失问题 在过去的时间里我们学习了RNN循环神经网络,其结构示意图是这样的: 其存在的最大问题是,当w1.w2.w3这些值小于0时,如果一句话够长,那么其在神经网络进行反向传播与前向传播时,存在梯度消失的问题. 0.925=0.07,如果一句话有20到30个
-
Python神经网络TensorFlow基于CNN卷积识别手写数字
目录 基础理论 一.训练CNN卷积神经网络 1.载入数据 2.改变数据维度 3.归一化 4.独热编码 5.搭建CNN卷积神经网络 5-1.第一层:第一个卷积层 5-2.第二层:第二个卷积层 5-3.扁平化 5-4.第三层:第一个全连接层 5-5.第四层:第二个全连接层(输出层) 6.编译 7.训练 8.保存模型 代码 二.识别自己的手写数字(图像) 1.载入数据 2.载入训练好的模型 3.载入自己写的数字图片并设置大小 4.转灰度图 5.转黑底白字.数据归一化 6.转四维数据 7.预测 8.显示
-
Python深度学习TensorFlow神经网络基础概括
目录 一.基础理论 1.TensorFlow 2.TensorFlow过程 1.构建图阶段 2.执行图阶段(会话) 二.TensorFlow实例(执行加法) 1.构造静态图 1-1.创建数据(张量) 1-2.创建操作(节点) 2.会话(执行) API: 普通执行 fetches(多参数执行) feed_dict(参数补充) 总代码 一.基础理论 1.TensorFlow tensor:张量(数据) flow:流动 Tensor-Flow:数据流 2.TensorFlow过程 TensorFlow
-
python神经网络TensorFlow简介常用基本操作教程
目录 要将深度学习更快且更便捷地应用于新的问题中,选择一款深度学习工具是必不可少的步骤. TensorFlow是谷歌于2015年11月9日正式开源的计算框架.TensorFlow计算框架可以很好地支持深度学习的各种算法. TensorFlow很好地兼容了学术研究和工业生产的不同需求. 一方面,TensorFlow的灵活性使得研究人员能够利用它快速实现新的模型设计: 另一方面,TensorFlow强大的分布式支持,对工业界在海量数据集上进行的模型训练也至关重要.作为谷歌开源的深度学习框架,Tens
-
python神经网络tensorflow利用训练好的模型进行预测
目录 学习前言 载入模型思路 实现代码 学习前言 在神经网络学习中slim常用函数与如何训练.保存模型文章里已经讲述了如何使用slim训练出来一个模型,这篇文章将会讲述如何预测. 载入模型思路 载入模型的过程主要分为以下四步: 1.建立会话Session: 2.将img_input的placeholder传入网络,建立网络结构: 3.初始化所有变量: 4.利用saver对象restore载入所有参数. 这里要注意的重点是,在利用saver对象restore载入所有参数之前,必须要建立网络结构,因
-
python神经网络Keras搭建RFBnet目标检测平台
目录 什么是RFBnet目标检测算法 RFBnet实现思路 一.预测部分 1.主干网络介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的RFB模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是RFBnet目标检测算法 RFBnet是SSD的一种加强版,主要是利用了膨胀卷积这一方法增大了感受野,相比于普通的ssd,RFBnet也是一种加强吧 RF
-
python深度学习TensorFlow神经网络模型的保存和读取
目录 之前的笔记里实现了softmax回归分类.简单的含有一个隐层的神经网络.卷积神经网络等等,但是这些代码在训练完成之后就直接退出了,并没有将训练得到的模型保存下来方便下次直接使用.为了让训练结果可以复用,需要将训练好的神经网络模型持久化,这就是这篇笔记里要写的东西. TensorFlow提供了一个非常简单的API,即tf.train.Saver类来保存和还原一个神经网络模型. 下面代码给出了保存TensorFlow模型的方法: import tensorflow as tf # 声明两个变量
-
python神经网络学习使用Keras进行回归运算
目录 学习前言 什么是Keras Keras中基础的重要函数 1.Sequential 2.Dense 3.model.compile 全部代码 学习前言 看了好多Github,用于保存模型的库都是Keras,我觉得还是好好学习一下的好 什么是Keras Keras是一个由Python编写的开源人工神经网络库,可以作Tensorflow.Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计.调试.评估.应用和可视化. Keras相当于比Tensorflow和The
-
python神经网络tf.name_scope和tf.variable_scope函数区别
目录 学习前言 两者区别 tf.variable_scope函数 测试代码 1.使用reuse=True共享变量 2.使用AUTO_REUSE共享变量 学习前言 最近在学目标检测……SSD的源码好复杂……看了很多版本的SSD源码,发现他们会使用tf.variable_scope,刚开始我还以为就是tf.name_scope,才发现原来两者是不一样的 两者区别 tf.name_scope()和tf.variable_scope()是两个作用域,一般与两个创建/调用变量的函数tf.variable(