R语言与格式,日期格式,格式转化的操作
R语言的基础包中提供了两种类型的时间数据,一类是Date日期数据,它不包括时间和时区信息,另一类是POSIXct/POSIXlt类型数据,其中包括了日期、时间和时区信息。
基本总结如下:
日期data,存储的是天;
时间POSIXct 存储的是秒,POSIXlt 打散,年月日不同;
日期-时间=不可运算。
一般来讲,R语言中建立时序数据是通过字符型转化而来,但由于时序数据形式多样,而且R中存贮格式也是五花八门,例如Date/ts/xts/zoo/tis/fts等等。lubridate包(后续有介绍,应用四),timeDate包,都有用。
常见的格式:
| as.numeric | 转化为数值型 |
| as.logic | 转化为逻辑型 |
| as.complex | 转化为复数型 |
| as.character | 转化为字符型 |
| as.array | 转化为数组 |
| as.data.frame | 转化为数据框 |
d<-as.character(z) #将数值向量z<-(0:9)转化为字符向量c("0", "1", "2", ..., "9")。
as.integer(d) #将d转化为数值向量
e <- numeric() #产生一个numeric型的空向量e
a=data.frame(a) #变成R的数据框
factor() #变成因子 可以用levels()来看因子个数
在data.frame中,是可以实现数据集重命名的,比如data.frame(x=iris,y=cars),
也可以实现横向、纵向重命名,data.frame(x=iris,y=cars,row.names=iris)
后续加更内容
应用1——如何通过生日计算年龄
应用2——日期分组
应用三——生成按天的时间序列并进行回归
应用四:灵活处理时间数据—lubridate包(来源TipDM)
应用五:如何在循环、函数中,输出实时时间消耗?
时间的标准格式
mydate = as.POSIXlt('2005-4-19 7:01:00')
names(mydate)
默认情况下,日期之前是以/或者-进行分隔,而时间则以:进行分隔;
输入的标准格式为:日期 时间(日期与时间中间有空隔隔开)
时间的标准格式为:时:分 或者 时:分:秒;
如果输入的格式不是标准格式,则同样需要使用strptime函数,利用format来进行指定。
一、日期型数据——data
1、as.Data函数
在R中自带的日期形式为:as.Date();以数值形式存储;
对于规则的格式,则不需要用format指定格式;如果输入的格式不规则,可以通过format指定的格式读入;其中以1970-01-01定义为第0天,之后的年份会以距离这天来计算。
> x<-as.Date("1970-01-01")
> unclass(x)
[1] 0
>
> unclass(as.Date("1970-02-01")) #19700201代表第31天
[1] 31
代码解读:unclass可以将日期变成以天来计数,比如1970-02-01输出的31,就代表着距离1970-01-01有31天。
as.data中的参数格式:年-月-日或者年/月/日;如果不是以上二种格式,则会提供错误——错误于charTo按照Date(x) : 字符串的格式不够标准明确;
例如这样的数据格式,就常常报错。
19:15.
显示为:2011/1/1 19:15
as.Date('23-2013-1',format='%d-%Y-%m')
#其中这个%d%Y可以节选其中一个
#%Y%y 大写代表年份四位数,小写代表年份二位数,要注意
2、%d%y%m-基本格式
|
格式 |
意义 |
|
%d |
月份中当的天数 |
|
%m |
月份,以数字形式表示 |
|
%b |
月份,缩写 |
|
%B |
月份,完整的月份名,指英文 |
|
%y |
年份,以二位数字表示 |
|
%Y |
年份,以四位数字表示 |
#其它日期相关函数
weekdays()取日期对象所处的周几;
months()取日期对象的月份;
quarters()取日期对象的季度。
二、时间型——POSIXct与POSIXlt
POSIXct 是以1970年1月1号开始的以秒进行存储,如果是负数,则是1970-01-01年以前;正数则是1970年以后。
POSIXlt 是以列表的形式存储:年、月、日、时、分、秒,作用是打散时间;
1、POSIXlt 格式
主要特点:作用是打散时间,把时间分成年、月、日、时、分、秒,并进行存储。
可以作为时间筛选的一种。
> today<-Sys.time() > unclass(as.POSIXlt(today)) $sec [1] 53.27151 $min [1] 38 $hour [1] 20 $mday [1] 6 $mon [1] 5 $year [1] 116 $wday [1] 1 $yday [1] 157 $isdst [1] 0 $zone [1] "CST" $gmtoff [1] 28800 attr(,"tzone") [1] "" "CST" "CDT"
代码解读:unclass将时间打散。
2、POSIXct 格式
主要特点:以秒进行存储。
> today<-Sys.time() > today [1] "2016-06-06 20:42:22 CST" > unclass(as.POSIXct(today)) [1] 1465216942
解读:比如今天,unclass之后,代表今天2016-06-06距离1970-01-01为1465216942秒。
#GMT代表时区,德意志时间,CST也代表时区
三、时间运算
1、基本运算函数
Sys.Date() #字符串类型 typeof(Sys.Date()) #系统日期类型
2、直接加减
相同的格式才能相互减,不能加。二进列的+法对"Date"、"POSIXt"对象不适用。
> as.Date("2011-07-01") - as.Date(today)
Time difference of -1802 days
> as.POSIXct(today)-as.POSIXct(as.Date("2012-10-25 01:00:00"))
Time difference of 1320.529 days
> as.POSIXlt(today)-as.POSIXlt(as.Date("2012-10-25 01:00:00"))
Time difference of 1320.529 days
相互减之后,一般结果输出的天数。
3、difftime函数——计算时差
不同格式的时间都可以进行运算。并且可以实现的是计算两个时间间隔:秒、分钟、小时、天、星期。
但是不能计算年、月、季度的时间差。
gtd <- as.Date("2011-07-01")
difftime(as.POSIXct(today), gtd, units="hours") #只能计算日期差,还可以是“secs”, “mins”, “hours”, “days”
4、format函数——提取关键信息
> today<-Sys.time() > format(today,format="%B-%d-%Y") [1] "六月-06-2016"
format函数可以将时间格式,调节成指定时间样式。format(today,format="%Y")其中的format可以自由调节,获取你想要的时间信息。
并且format函数可以识别as.Data型以及POSIXct与POSIXlt型,将其日期进行提取与之后要讨论的split类型。
> today<-Sys.time() > format(as.Date(today),format="%Y") [1] "2016" > format(as.POSIXlt(today),format="%Y") [1] "2016" > format(as.POSIXct(today),format="%Y") [1] "2016"
但是format出来的时间不能直接做减法,会出现错误: non-numeric argument to binary operator
5、strptime函数
该函数是将字符型时间转化为 "POSIXlt" 和"POSIXct"两类。跟format比较相似。
strptime之后的时间是可以直接做减法,因为直接是"POSIXlt" 和"POSIXct"格式了。
> strptime("2006-01-08 10:07:52", "%Y-%m-%d")-strptime("2006-01-15 10:07:52", "%Y-%m-%d")
Time difference of -7 days
> class(strptime("2006-01-08 10:07:52", "%Y-%m-%d"))
[1] "POSIXlt" "POSIXt"
四、遇见的问题
1、常常报错。
错误于charTo按照Date(x) : 字符串的格式不够标准明确。这个错误经常出现,我本来的数据格式是
19:15.
后来换成“2011/1/1”这样的就不会报错了,需要数据库自动改变。
#几种错误汇总
dtV<-data.frame(as.POSIXct(a$b,format="%d.%m.%Y")) #错,读出来都是NA
as.Date(a$b, "%Y年%m月%d日") #错,读不出来
as.POSIXct(strptime(a$b, "%Y-%m-%d")) #读不出来
#转化成xts格式也读不出来
install.packages("xts")
library(xts)
as.xts(read.zoo("time.csv",header=T))
a <- as.xts(a, descr='my new xts object')
as.xts(read.zoo("a.csv",header=T))
#错
#转化成数值型也不对
c=as.numeric(sales[,2])
2、excel另存为csv时发生的错误。
一位网友说:我以前是在excel里另存为csv格式,百度上说CSV档如果以EXCEL开启,由于计算机档案数据转换的原因,会将其CRC之数值改做科学记号方式储存,而造成档案中的 CRC值发生错误。
应用1——如何通过生日计算年龄
1、format函数
timeformat<-function(x){
format(as.POSIXct(x),format="%Y")
}
sapply(as.Date(data$birthdate),timeformat)
format只能一个一个操作,可以先写成函数,然后计算得出年份,之后用如今的年份相减得到年龄。
2、字符型——strsplit
先转化为字符型,然后进行分割。
data.frame(sapply(as.character(data$birthdate),function(x){strsplit(x,"-")[[1]][1]}))
注意,其中strsplit中的"-",根据具体时间格式情况来定义。
应用2——日期分组
一种按照日期范围——例如按照周、月、季度或者年——对其进行分组的超简便处理方式:R语言的cut()函数。
假设vector中存在以下示例数据:
vDates <- as.Date(c("2013-06-01", "2013-07-08", "2013-09-01", "2013-09-15")) #as.Data()函数的作用非常重要;如果没有它,R语言会认为以上内容仅仅是数字串而非日期对象
[1] "2013-06-01" "2013-07-08" "2013-09-01" "2013-09-15"
vDates.bymonth <- cut(vDates, breaks = "month")
[1] 2013-06-01 2013-07-01 2013-09-01 2013-09-01
Levels: 2013-06-01 2013-07-01 2013-08-01 2013-09-01
Dates <- data.frame(vDates, vDates.bymonth)
应用三——生成按天的时间序列并进行回归
如果是生成简单的年度,月度数据,ts函数可以满足,但是如果生成的是每天。因为有闰年缘故,所以zoo包可以很好地解决这个问题。
还有笔者在做一个简单的时间序列回归时候,疑惑:
做关于时间序列的ols最小二乘法回归方程,按年来好说,但是如果是按天,如果进行计算呢?
1、把天变成一排规律递增的数字来代替;
2、ts函数变化之后,也是变成一个递增的数字。
以上两种,做的结果都一样,所以没有什么太大的区别。
关于ts函数by day每一天的时间序列生成,该如何呢?
n=30
t<-ts(1:n,frequency=1,start=as.Date("2010-01-09"))
生成一个按天的时间序列。
应用四:灵活处理时间数据—lubridate包(来源TipDM)
lubridate包是由Garrett Grolemund 和 Hadley Wickham写的,可以灵活地处理时间数据。lubridate包主要有两类函数,一类是处理时点数据(time instants),另一类是处理时段数据(time spans)。
1、时点类函数
主要包括解析、抽取、修改。
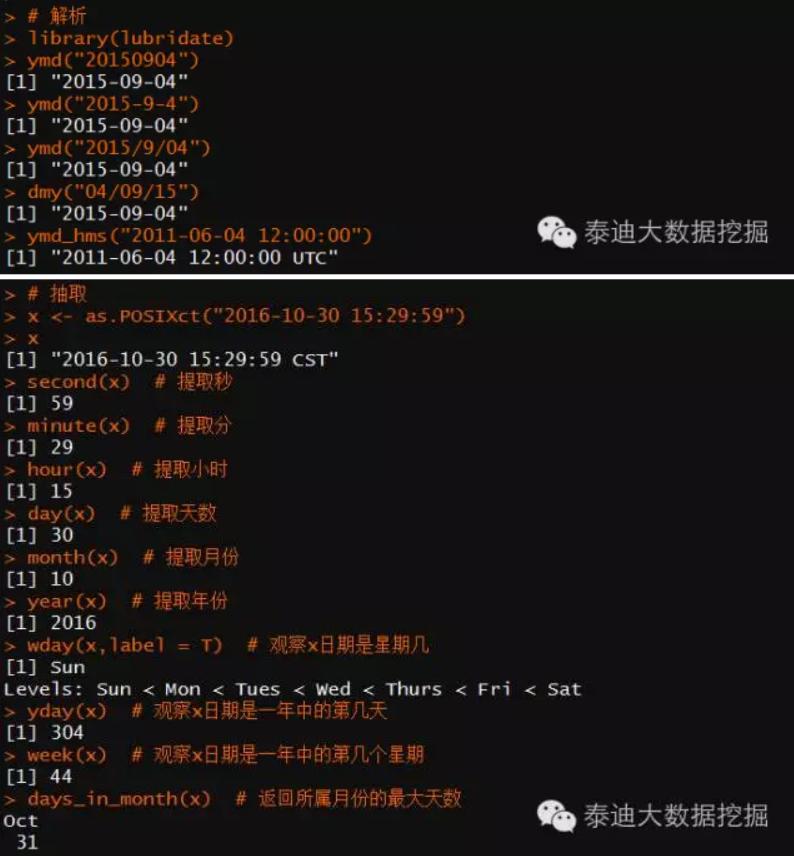

2、时段类函数
可以处理三类对象,分别是:
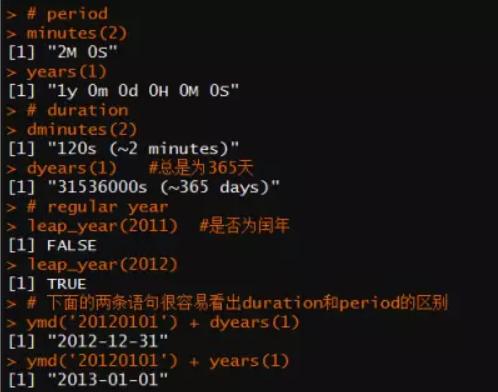
interval:最简单的时段对象,它由两个时点数据构成。
duration:去除了时间两端的信息,纯粹以秒为单位计算时段的长度,不考虑闰年和闰秒,它同时也兼容基本包中的difftime类型对象。
period:以较长的时钟周期来计算时段长度,它考虑了闰年和闰秒,适用于长期的时间计算。以2012年为例,duration计算的一年是标准不变的365天,而period计算的一年就会变成366天。
有了时点和时段数据,就可以进行各种计算了。

3、时区信息
lubridate包提供了三个函数:
tz:提取时间数据的时区
with_tz:将时间数据转换为另一个时区的同一时间
force_tz:将时间数据的时区强制转换为另一个时区

应用五:如何在循环、函数中,输出实时时间消耗?
想知道循环中进行到哪里?这样可以合理安排函数进程。那么怎么办呢?
第一办法:使用Rstudio 1.0版本,里面有一个Profiling with profvis,可以很好的对你函数每一步的耗时进行参看。
R︱Rstudio 1.0版本尝鲜(R notebook、下载链接、sparkR、代码时间测试profile)
当然,这个不能实时输出内容。
第二办法:利用difftime函数
t1 = Sys.time()
for (i in 1:5){
a=a+1
b=a*a
print(difftime(Sys.time(), t1, units = 'sec'))
}
先预设当前时间,然后用difftime+print方式,循环输出。
应用六:因子型数据转化为数值型
因子型转化的时候会发现,譬如10000这个数字,会变为6,也就是因子型里面对应的次序,这样并不是我们想要的。所以,可以先变为字符型as.character:
as.numeric(as.character(data))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言格式化输出sprintf实例讲解
用%s替代字符串 name <- 'max' sprintf('my name is %s',name) [1] "my name is max" 用%d替代整数 age <- 18 sprintf('age:%d',age) [1] "age:18" d前面添加数字n,可以添加n-替代数字位数的空格 sprintf('age:%3d',age) [1] "age: 18" d前面添加0加上数字n,可以添加n-替代数字位数的0 spr
-
R语言-如何定义数据框的列名
1.在定义数据框时,定义列名: 例如: a<-c(2,23,45,6,7,1,6,7) b<-c(4,6,1,2,5,66,10,2) df<-data.frame(a,b) 此时数据框df中的列名分别是a.b 也可以如下: df<-data.frame(a1=a,b1=b) 此时的列名是a1.b1 2.修改数据框中列的名字 如果希望修改数据框中的列名,可以使用name函数进行修改 例如: names(df)<-c("a2","b2")
-

R语言如何将大型Excel文件转为dta格式详解
本文以2000年度我国工业企业数据库为例,该文件后缀名为xlsx,包含约16万条记录,文件有88M这么大.直接使用Excel打开都费劲:等待时间久,电脑风扇呼呼呼作响.如果尝试用Stata打开该xlsx文件,则会出现提示报错. 报错原因在于,Stata无法读取超过40M的Excel文件. 这就好比瓜迪奥拉的传控足球固然美丽,但是面对摆大巴的球队无能为力. 破大巴需要攻城锤,这把锤子的名字就是R语言.万事开头难啊,正憧憬着数据清洗和花式选取变量建模呢,可不能连数据们长啥模样都没见着啊.R语言适时挺
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg
-
R语言科学计数法介绍:digits和scipen设置方式
控制R语言科学计算法显示有两个option: digitis和scipen.介绍的资料很少,而且有些是错误的.经过翻看R语言的帮助和做例子仔细琢磨,总结如下: 默认的设置是: getOption("digits") [1] 7 getOption("scipen") [1] 0 digits 有效数字字符的个数,默认是7, 范围是[1,22] scipen 科学计数显示的penalty,可以为正为负,默认是0 R输出数字时,使用普通数字表示的长度 <= 科学计
-
R语言读取xls与xlsx格式文件过程
目录 1. ROOBC 2. xlsReadWrite 3. XLConnect 4. xlsx 1)装Java 2)装xlsx 3)实际使用 在数据分析的过程中,第一步就是读取数据. 通常我们遇到的数据是csv格式或者txt格式的数据,这时我们使用系统自带的read.csv()与read.table()就可对这些格式的数据进行读取,只是读取时需注意编码格式.对于大型csv格式的数据(当然小数据也可以),可以使用data.table包中的fread()进行读取可以极大地提升读取速度. 但当遇到了
-
R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言变量重编码、重命名的操作
1.变量重编码 重编码涉及根据同一个变量和/或其他变量的现有值创建新值的过程,如将符合某个条件的值重新赋值等,这里主要介绍两种常见的方法: #第一种方法 per <- data.frame(name = c("张三","李四","王五","赵六"), age = c(23,45,34,1000)) per per$age[per$age == 1000] <- NA #设置缺失值 per$age1[per$age
-
R语言 实现在循环中输出图片的操作
今天在循环导出图片时,遇到了一个问题: 使用R语言导出图片的代码: setwd("E://R") jpeg(file="A.jpeg") print(plot(PEO$X, PEO$Y, pch=PEO$S)) dev.off() 但是若是将此代码运用到循环之中,则只会出来一张图A.jpeg 想了好久原因,发现--..!!!! 命名方法不对啊!!! 只有一个名字!!!当然不行啊!!! 于是搜索如何循环命名- 找到了老朋友paste() yourfilename=pa
-
R语言数值取消科学计数法表示的操作
我就废话不多说了,大家还是直接看代码吧~ >#取消科学计数法 >options(scipen = 200) >#scipen 表示在200个数字以内都不使用科学计数法 补充:R语言去除科学计数法 保留小数位 R语言 去除科学计数法 保留小数位 options("scipen"=100, "digits"=4) 补充:R语言科学计数法数据改变/丢失/失准,取消科学计数法的原因和解决方法 问题描述 如何在R中取消科学计数法 & 对R中使用科学技
-
R语言 设置ylab每个汉字竖向排列的操作
只看标题可能不知道啥意思,所以先上图了. 从图中可以看到ylab中汉字的排列方式是从上到下的,要实现这样的效果有两个关键步骤: 一是ylab不是常规的"月工作量",而是'月\n工\n作\n量',每个汉字中间要进行换行. 二是要对ylab进行旋转. 下面给出代码: library(ggplot2) #数据 df <- data.frame( gp = factor(rep(letters[1:3], each = 10)), y = rnorm(30) ) #ggplot绘制 p0
-
R语言之左连接的三种实现操作
数据处理中经常遇到表连接问题,本次介绍R语言中三种左连接方法,这三种是等价的,不过会有时间快慢问题,斟酌使用. 法一: > data0 <- merge(a,c,all.x=TRUE,by='CELLPHONE') 法二: > data1 <- sqldf('select a.*,b.* from a left join c on a.CELLPHONE=c.CELLPHONE') 法三: > data2 <- c[a,on='CELLPHONE'] 注意:第三种方法的
-
R语言 实现手动设置xy轴刻度的操作
在R中,plot函数作图时会自动给出xy轴的刻度标度,如下图: 有时我们需要自己定义xy轴的刻度,这时我们可以用axis中的at和labels参数来更改. 首先,我们先令plot不要画出xy轴的标度 然后,用axis函数设置xy轴的刻度 这样xy轴的刻度就完全按照我们自己的意愿显示了,也可以设置at参数不是均匀的,总之,用这两个参数就可以完全自己控制xy轴的刻度显示了 补充:R语言自定义坐标轴示例 我就废话不多说了,大家还是直接看代码吧~ x <- c(1:10) y <- x z <-
-
R语言利用caret包比较ROC曲线的操作
说明 我们之前探讨了多种算法,每种算法都有优缺点,因而当我们针对具体问题去判断选择那种算法时,必须对不同的预测模型进行重做评估. 为了简化这个过程,我们使用caret包来生成并比较不同的模型与性能. 操作 加载对应的包与将训练控制算法设置为10折交叉验证,重复次数为3: library(ROCR) library(e1071) library("pROC") library(caret) library("pROC") control = trainControl(
-
R语言之xlsx包读写Excel数据的操作
感谢Adrian A. Drǎgulescu发布的xlsx包 xlsx包提供了必要的工具来与Excel 2007进行交互.用户可以阅读和编写xlsx,并可以通过设置数据格式.字体.颜色和边框来控制电子表格的外观.设置打印区域,缩放控制,创建分割和冻结面板,添加页眉和页脚.包使用Apache POI项目中的java库.本篇主要分享利用xlsx工具包在读写xlsx过程中所碰到的问题及解决办法. 工具准备 强烈建议大家使用RStudio这个IDE,它是以今为止对R语言最友好的一个IDE之一,而且使用很