Python grequests模块使用场景及代码实例
使用场景:
1) 爬虫设置ip代理池时验证ip是否有效
2)进行压测时,进行批量请求等等场景
grequests 利用 requests和gevent库,做了一个简单封装,使用起来非常方便。
grequests.map(requests, stream=False, size=None, exception_handler=None, gtimeout=None)
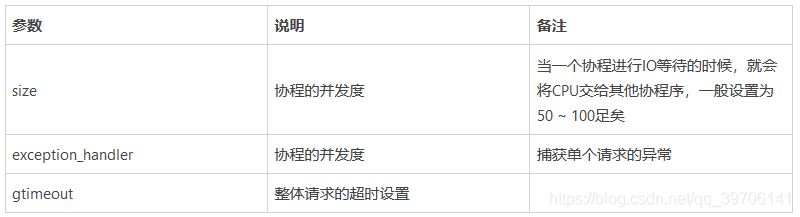
另外,由于grequests底层使用的是requests,因此它支持
GET,OPTIONS, HEAD, POST, PUT, DELETE 等各种http method
所以以下的任务请求都是支持的
grequests.post(url, json={“name”:“zhangsan”})
grequests.delete(url)
代码如下:
import grequests
urls = [
'http://www.baidu.com',
'http://www.qq.com',
'http://www.163.com',
'http://www.zhihu.com',
'http://www.toutiao.com',
'http://www.douban.com'
]
rs = (grequests.get(u) for u in urls)
print(grequests.map(rs)) # [<Response [200]>, None, <Response [200]>, None, None, <Response [418]>]
def exception_handler(request, exception):
print("Request failed")
reqs = [
grequests.get('http://httpbin.org/delay/1', timeout=0.001),
grequests.get('http://fakedomain/'),
grequests.get('http://httpbin.org/status/500')
]
print(grequests.map(reqs, exception_handler=exception_handler))
实际操作中,也可以自定义返回的结果
修改grequests源码文件:
例如:
新增extract_item() 函数合修改map()函数
def extract_item(request):
"""
提取request的内容
:param request:
:return:
"""
item = dict()
item["url"] = request.url
item["text"] = request.response.text or ""
item["status_code"] = request.response.status_code or 0
return item
def map(requests, stream=False, size=None, exception_handler=None, gtimeout=None):
"""Concurrently converts a list of Requests to Responses.
:param requests: a collection of Request objects.
:param stream: If True, the content will not be downloaded immediately.
:param size: Specifies the number of requests to make at a time. If None, no throttling occurs.
:param exception_handler: Callback function, called when exception occured. Params: Request, Exception
:param gtimeout: Gevent joinall timeout in seconds. (Note: unrelated to requests timeout)
"""
requests = list(requests)
pool = Pool(size) if size else None
jobs = [send(r, pool, stream=stream) for r in requests]
gevent.joinall(jobs, timeout=gtimeout)
ret = []
for request in requests:
if request.response is not None:
ret.append(extract_item(request))
elif exception_handler and hasattr(request, 'exception'):
ret.append(exception_handler(request, request.exception))
else:
ret.append(None)
yield ret
可以直接调用:
import grequests urls = [ 'http://www.baidu.com', 'http://www.qq.com', 'http://www.163.com', 'http://www.zhihu.com', 'http://www.toutiao.com', 'http://www.douban.com' ] rs = (grequests.get(u) for u in urls) response_list = grequests.map(rs, gtimeout=10) for response in next(response_list): print(response)
支持事件钩子
def print_url(r, *args, **kwargs):
print(r.url)
url = “http://www.baidu.com”
res = requests.get(url, hooks={“response”: print_url})
tasks = []
req = grequests.get(url, callback=print_url)
tasks.append(req)
ress = grequests.map(tasks)
print(ress)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python logging模块进行封装实现原理解析
1. 简介 追踪某些软件运行时所发生事件的方法, 可以在代码中调用日志中某些方法来记录发生的事情 一个事件可以用一个可包含可选变量数据的消息来描述 事件有自己的重要性等级 2. 使用logging日志系统四大组件 loggers日志器 提供应用程序代码直接使用的接口 handlers处理器 用于将日志记录发送到指定的目的位置 filters过滤器 过滤, 决定哪些输出哪些日志记录, 其余忽略 formatters格式器 控制日志输出格式 使用代码如下 import os, time,
-
Python如何重新加载模块
问题 你想重新加载已经加载的模块,因为你对其源码进行了修改. 解决方案 使用imp.reload()来重新加载先前加载的模块.举个例子: >>> import spam >>> import imp >>> imp.reload(spam) <module 'spam' from './spam.py'> >>> 讨论 重新加载模块在开发和调试过程中常常很有用.但在生产环境中的代码使用会不安全,因为它并不总是像您期望的那样
-
Python如何将将模块分割成多个文件
问题 你想将一个模块分割成多个文件.但是你不想将分离的文件统一成一个逻辑模块时使已有的代码遭到破坏. 解决方案 程序模块可以通过变成包来分割成多个独立的文件.考虑下下面简单的模块: # mymodule.py class A: def spam(self): print('A.spam') class B(A): def bar(self): print('B.bar') 假设你想mymodule.py分为两个文件,每个定义的一个类.要做到这一点,首先用mymodule目录来替换文件mymodu
-
Python configparser模块封装及构造配置文件
1.configparser模块简介 使用配置文件来灵活的配置一些参数是一件很常见的事情,配置文件的解析并不复杂,在python里更是如此,在官方发布的库中就包含有做这件事情的库,那就是configParser configParser解析的配置文件的格式比较象ini的配置文件格式,就是文件中由多个section构成,每个section下又有多个配置项 2.看一下configparser生成的配置文件的格式 ini配置文件格式如下: 这里是注释 [log] log_path = base_dir
-
Python中logger日志模块详解
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
-
Python实现打包成库供别的模块调用
1.创建python项目bricewulib 2.新建test_package包并创建info1类以及print_hello方法 3.为了让包的结构再复杂点,我们再在test_package下面新建一个test_package2包并创建Info2类以及print_hello2方法(注意:这里是Info2,不是上面的Info1) 4.此时整个test_package编写完成,目录结构(test_package包包含test_package2包以及info1类,test_package2包中又包含i
-
Python3安装模块报错Microsoft Visual C++ 14.0 is required的解决方法
问题一:安装模块时出现报错 Microsoft Visual C++ 14.0 is required,也下载安装了运行库依然还是这个错误 解决: 1.打开Unofficial Windows Binaries for Python Extension Packages(http://www.lfd.uci.edu/~gohlke/pythonlibs/),这里面有很多封装好的Python模块的运行环境 2.找到所需要下载的模块文件对应版本进行下载. 如,需要下载Pymssql,本机安装是32位
-
Python基于xlrd模块处理合并单元格
目的: python能使用xlrd模块实现对Excel数据的读取,且按照想要的输出形式. 总体思路: (1)要想实现对Excel数据的读取,需要用到第三方应用,直接应用. (2)实际操作时候和我们实际平时打开一个文件进行操作一样,先找到文件-->打开文件-->定义要读取的sheet-->读取出内容. Excel处理合并单元格: 已存在合并单元格如下: xlrd中的 merged_cells 属性介绍:[code]import xlrd import xlrd workbook = xlr
-
Python grequests模块使用场景及代码实例
使用场景: 1) 爬虫设置ip代理池时验证ip是否有效 2)进行压测时,进行批量请求等等场景 grequests 利用 requests和gevent库,做了一个简单封装,使用起来非常方便. grequests.map(requests, stream=False, size=None, exception_handler=None, gtimeout=None) 另外,由于grequests底层使用的是requests,因此它支持 GET,OPTIONS, HEAD, POST, PUT, D
-
对Python random模块打乱数组顺序的实例讲解
在我们使用一些数据的过程中,我们想要打乱数组内数据的顺序但不改变数据本身,可以通过改变索引值来实现,也就是将索引值重新随机排列,然后生成新的数组.功能主要由python中random模块的sample()函数实现. sample(population, k) method of random.Random instance Chooses k unique random elements from a population sequence or set. 下面的代码实现的是打乱iris数据,i
-
Python统计时间内的并发数代码实例
这篇文章主要介绍了Python统计时间内的并发数代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python实现并发的手段: 1.操作系统提供:进程.线程: 2.编程语言提供:协程:用户空间的调度(py3): # coding:utf-8 # 1.导入模块 # datatime模块用于定义时间及时间的加减操作 # MySQLdb模块用于Python2.0连接数据库,Python3.0连接数据库使用pymysql # xlwt模块是exc
-
python argparse模块通过后台传递参数实例
我就废话不多说了,大家还是直接看代码吧! cmd.py # -*- coding: utf-8 -*- from PySide import QtGui, QtCore import os,sys import tory import argparse parser = argparse.ArgumentParser() parser.add_argument("-v", "--verbosity", help="increase output verbo
-

Python pkg_resources模块动态加载插件实例分析
使用标准库importlib的import_module()函数.django的import_string(),它们都可以动态加载指定的 Python 模块. 举两个动态加载例子: 举例一: 在你项目中有个test函数,位于your_project/demo/test.py中,那么你可以使用import_module来动态加载并调用这个函数而不需要在使用的地方通过import导入. module_path = 'your_project/demo' module = import_module(
-
python XlsxWriter模块创建aexcel表格的实例讲解
安装使用pip install XlsxWriter来安装,Xlsxwriter用来创建excel表格,功能很强大,下面具体介绍: 1.简单使用excel的实例: #coding:utf-8 import xlsxwriter workbook = xlsxwriter.Workbook('d:\\suq\\test\\demo1.xlsx') #创建一个excel文件 worksheet = workbook.add_worksheet('TEST') #在文件中创建一个名为TEST的shee
-
python英语单词测试小程序代码实例
这篇文章主要介绍了python英语单词测试小程序代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 爬取了扇贝英语网,并制作了一个英语单词测试的小程序,还能生成错词本,一起来看下代码吧- import requests #扇贝网爬虫,获取英语单词 category_res=requests.get('https://www.shanbay.com/api/v1/vocabtest/category/?_=1566889802182') ca
-
python制作英语翻译小工具代码实例
这篇文章主要介绍了python制作英语翻译小工具代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 用python爬虫可以制作英语翻译小工具.来看下代码吧- import requests,json #函数封装 def translator(): session=requests.session() i=input('请问你要翻译什么?') url='http://fanyi.youdao.com/translate' headers={
-
用Python画一个LinkinPark的logo代码实例
这篇文章主要介绍了用Python画一个LinkinPark的logo代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 # -*- coding: UTF-8 -*- from turtle import * width(17) right(25) circle(150,200,20) left(65) forward(240) left(120) forward(195) left(120) forward(135) left(
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)