Python实现爬取网页中动态加载的数据
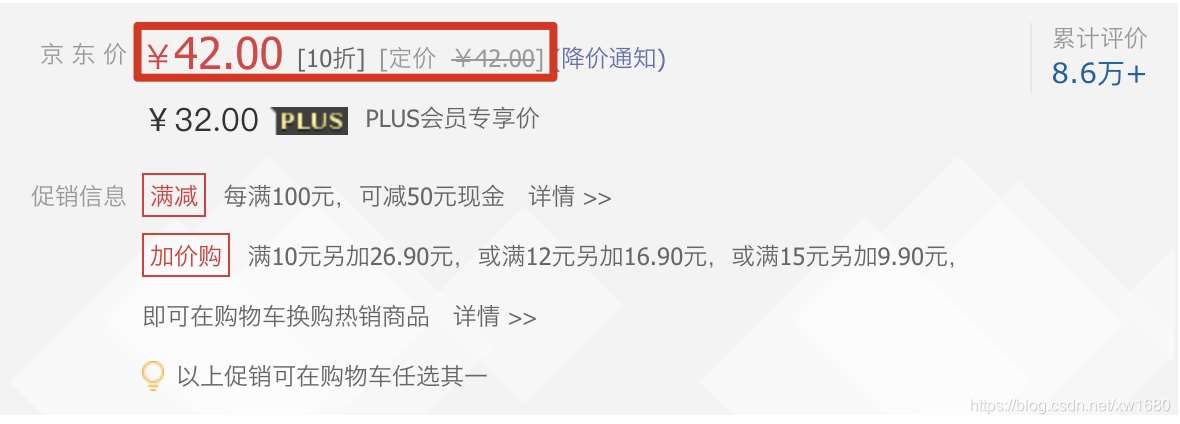
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据。例如,获取某网页中,商品价格时就会出现此类现象。如下图所示。本文将实现爬取网页中类似的动态加载的数据。
1. 那么什么是动态加载的数据?
我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的。而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数据。(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其他url中获取数据)
2. 如何检测网页中是否存在动态加载得数据?
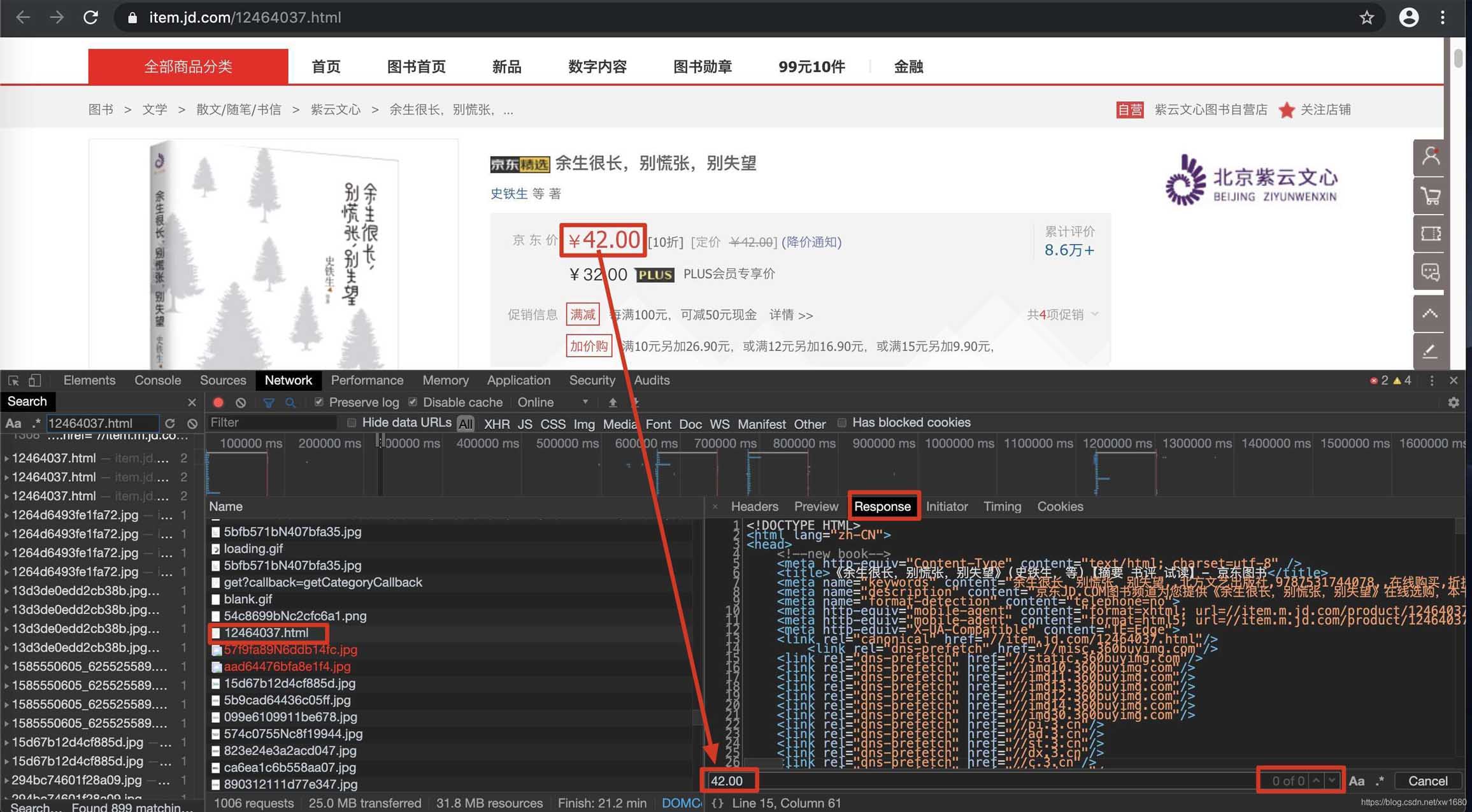
在当前页面中打开抓包工具,捕获到地址栏中的url对应的数据包,在该数据包的response选项卡搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如图所示:
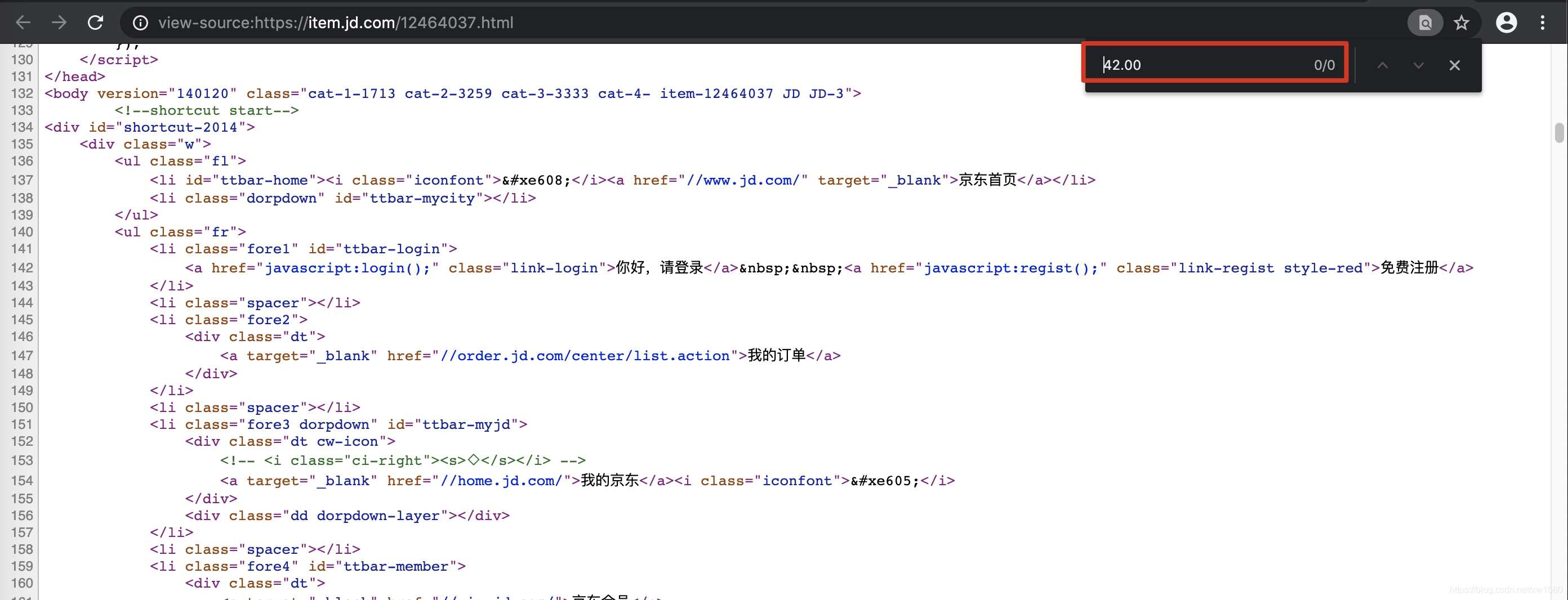
或者鼠标右键单击要爬取的页面显示网页源代码搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如图所示:
3. 如果数据为动态加载,那么我们如何捕获到动态加载的数据?
在实现爬取动态加载的数据信息时,首先需要在浏览器的网络监视器中根据动态加载的技术选择网络请求的类型,然后通过逐个筛选的方式查询预览信息中的关键数据,并获取对应的请求地址,最后进行信息的解析工作即可。具体步骤如下:
在浏览器中快捷键F12打开开发者工具,然后选择Network(网络监视器)并在网络类型中选择JS,再按快捷键F5刷新,如下图所示。

在请求信息的列表中,依次单击每个请求信息,然后在对应的Preview(请求结果预览)中核对是否为需要获取的动态加载数据,如下图所示。

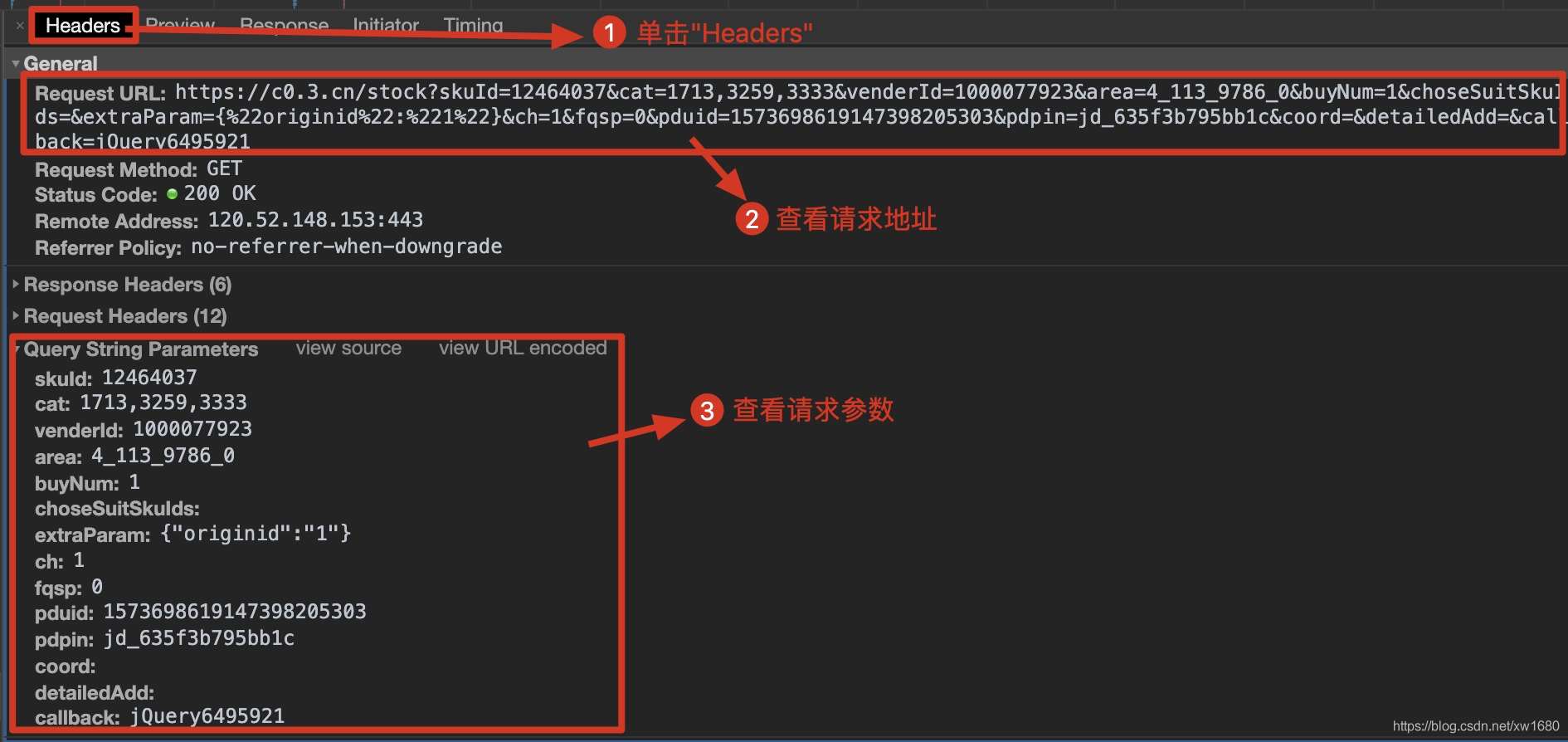
动态加载的数据信息核对完成后,单击Headers获取当前的网络请求地址以及所需参数,如下图所示。
根据以上步骤获取到的请求地址,发送网络请求并从返回的信息中提取商品价格信息。笔者在代码中使用到了反序列化,关于json序列化和反序列化可以点击 此处 进行学习,代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
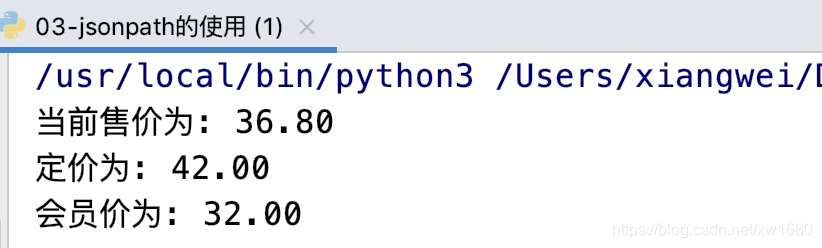
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
笔者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载数据信息时,需要根据不同的网页使用不同的方式进行数据的提取。如果在运行源码时出现了错误,请根据操作步骤获取新的请求地址即可。
到此这篇关于Python实现爬取网页中动态加载的数据的文章就介绍到这了,更多相关Python 爬取网页动态数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
python爬取Ajax动态加载网页过程解析
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 :网站根据IP地址访问频率进行反爬,短时间内进制IP访问 解决方案: 1.构造自己IP代理池,每次访问随机选择代理,经常更新代理池 2.购买开放代理或私密代理IP 3.降低爬取的速度 3.User-Agent限制 :类似于IP限制 解决方案: 构造自己的User-Agent池,每次访问随机选择 5.
-
Python实现的爬取网易动态评论操作示例
本文实例讲述了Python实现的爬取网易动态评论操作.分享给大家供大家参考,具体如下: 打开网易的一条新闻的源代码后,发现并没有所要得评论内容. 经过学习后发现,源代码只是一个完整页面的"骨架",而我所需要的内容是它的填充物,这时候需要打开工具里面的开发人员工具,从加载的"骨肉"里找到我所要的评论 圈住的是类型 找到之后打开网页,发现json类型的格式,用我已学过的正则,bs都不好闹,于是便去了解了正则,发现把json的格式换化成python的格式后,用列表提取内容
-
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
Python实现爬取网页中动态加载的数据
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据.例如,获取某网页中,商品价格时就会出现此类现象.如下图所示.本文将实现爬取网页中类似的动态加载的数据. 1. 那么什么是动态加载的数据? 我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的.而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数据.(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其
-
python如何爬取网页中的文字
用Python进行爬取网页文字的代码: #!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re # 下载一个网页 url = 'https://www.biquge.tw/75_75273/3900155.html' # 模拟浏览器发送http请求 response = requests.get(url) # 编码方式 response.encoding='utf-8' # 目标小说主页的网页源码 html = re
-
Python使用Selenium爬取淘宝异步加载的数据方法
淘宝的页面很复杂,如果使用分析ajax或者js的方式,很麻烦 抓取淘宝'美食'上面的所有食品信息 spider.py #encoding:utf8 import re from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
在WPF中动态加载XAML中的控件实例代码
本文实例讲述了在WPF中动态加载XAML中的控件的方法.分享给大家供大家参考,具体如下: using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Windows; using System.Windows.Controls; using System.Windows.Data; using System.Windows.Documents; using S
-
javascript操作向表格中动态加载数据
本文实例为大家分享了javascript实现向表格中动态加载数据的具体代码,供大家参考,具体内容如下 首先在HTML中编写表格信息 <table width="500px" border="1"> //表格头部信息 <thead> <tr> <th>编号</th> <th>姓名</th> <th>身份</th> <th>操作</th>
-
Vue3的setup在el-tab中动态加载组件的方法
公司某项目需求在页面显示的组件是根据角色变化而变化的,在这个项目中我使用了elementplus的el-tabs来动态的显示这些组件,如下图所示 <template> <component style="margin-top:15px" v-for="item in pageList" :is="item.module_id"/> </template> 数据内容大概是这样的 在未使用setup语法糖时候我要引
-
JQuery Ajax动态加载Table数据的实例讲解
我们在jsp定义一个select和一个table,要求实现根据select的选值,动态加载table数据. <select id="type" name="type" onchange="reloadTable(this)"></select> <table id="import-table" class="table table-striped table-bordered table
-
ajax动态加载json数据并详细解析
效果图 jsp代码 <form > 姓名:<input name="name" type="text"/> 年龄:<input name="age" type="text"/> <input type="button" class="get" value="get提交"/> <input type="bu
-
AJAX 动态加载后台数据 绑定select的方法
直接上代码 是可以用的,后台代码我就不贴了,我相信后台代码大家都会,直接返回json数据,我是前端比较差的,所以喜欢把每次不会的全部记起来 html代码 <select id="select" style="width : 80px;height : 30px;"> //下拉框数据动态加载 </select> js代码 $.ajax({ url: "", //后台webservice里的方法名称 contentType: