Python自动化xpath实现自动抢票抢货
小伙伴们,这次推文讲的是‘xpath‘,掌握起来不难的哦。而且,熟悉了这套路,别说pubmed,任何你能在浏览器实现的操作,都基本能通过selenium自动化进行。
总代码:
for i in range(51,56):
driver.implicitly_wait(10)
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-results-panel-trigger"]')).click().perform()
Select(driver.find_element_by_xpath('//*[@id="save-action-selection"]')).select_by_visible_text("All results on this page")
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-action-format"]')).click().perform()
Select(driver.find_element_by_xpath('/html/body/main/div[1]/div/form/div[2]/select')).select_by_visible_text("CSV")
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-action-panel-form"]/div[3]/button[1]')).click().perform()
target =driver.find_element_by_xpath('//*[@id="search-results"]/section/div[3]/a/span')
driver.execute_script("arguments[0].();", target)
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="search-results"]/section/div[3]/a/span')).click().perform()
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="search-page"]/div[12]/div/form/button')).click().perform()
print('第'+str(i)+'页下载成功')
print('跳转第'+str(i+1)+'页面中')
driver.quit()
print('全部下载完毕,自动退出。')
代码1

for i in range(1,50+1): printg('我错了')

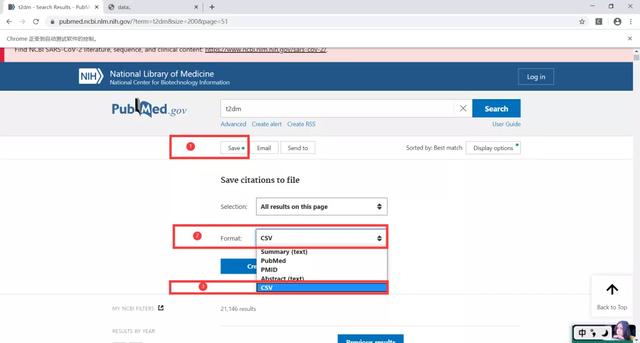
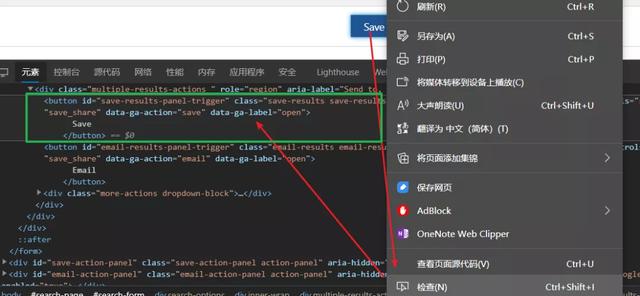
操作如下:鼠标移动到Save按钮→鼠标右击→检查,
可以发现源代码有一块区域亮起来了
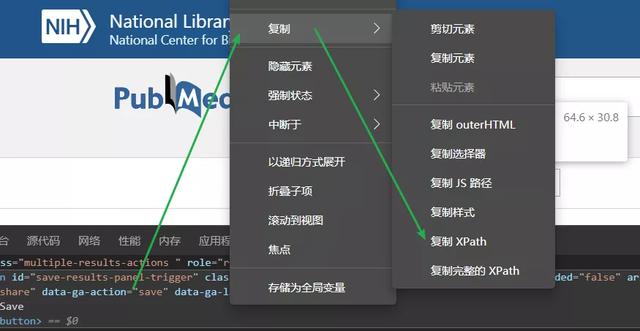
这块区域就是Save按钮对应的源代码→鼠标移动到该源代码区域→右击→复制→复制XPath,
这样我们就复制了Save按钮的Xpath了,接下来只需要粘贴到代码就行.
小伙伴们是否还记得ActionChains的万能公式:
ActionChains(driver).move_to_element(driver.find_element_by_xpath('xpath_content')).click().perform()
我们只需要把刚才复制的xpath粘贴到代码中的“xpath_content”区域就行
是不是很熟悉呢,是的,这便是我们使用ActionChains模块实现的第一个操作,后续的一样噢,只需要复制对应的Xpath直接粘贴就行了。

最后,因为以上均是循环体的内容,当代码执行完整个循环体了,我们可以通过代码直接关掉浏览器,提醒我们打印完了,代码如下
driver.quit()
print('全部下载完毕,结束了')
因为这两句代码已经不是循环体的内容了,所以无需另起一行空两个,而且,小伙伴记得噢,所有字符都是英文字符,包括括号、引号等等。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python selenium xpath定位操作
xpath是一种在xm文档中定位的语言,详细简介,请自行参照百度百科,本文主要总结一下xpath的使用方法,个人看法,如有不足和错误,敬请指出. 注意:xpath的定位 同一级别的多个标签 索引从1开始 而不是0 1. 绝对定位: 此方法最为简单,具体格式为 xxx.find_element_by_xpath("绝对路径") 具体例子: xxx.find_element_by_xpath("/html/body/div[x]/form/input") x 代表第x个
-
Python中利用xpath解析HTML的方法
在进行网页抓取的时候,分析定位html节点是获取抓取信息的关键,目前我用的是lxml模块(用来分析XML文档结构的,当然也能分析html结构), 利用其lxml.html的xpath对html进行分析,获取抓取信息. 首先,我们需要安装一个支持xpath的python库.目前在libxml2的网站上被推荐的python binding是lxml,也有beautifulsoup,不嫌麻烦的话还可以自己用正则表达式去构建,本文以lxml为例讲解. 假设有如下的HTML文档: <html> <
-
python3 xpath和requests应用详解
根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库. etree使用xpath语法. import requests import ssl from lxml import etree ssl._create_default_https_context = ssl._create_unverified_context session = requests.Session() for id in range(0, 251, 25): URL = 'https://movie.
-
Python基于lxml模块解析html获取页面内所有叶子节点xpath路径功能示例
本文实例讲述了Python基于lxml模块解析html获取页面内所有叶子节点xpath路径功能.分享给大家供大家参考,具体如下: 因为需要使用叶子节点的路径来作为特征,但是原始的lxml模块解析之后得到的却是整个页面中所有节点的xpath路径,不是我们真正想要的形式,所以就要进行相关的处理才行了,差了很多网上的博客和文档也没有找到一个是关于输出html中全部叶子节点的API接口或者函数,也可能是自己没有那份耐心,没有找到合适的资源,只好放弃了寻找,但是这并不说明没有其他的方法了,在对页面全部节点
-
python的xpath获取div标签内html内容,实现innerhtml功能的方法
python的xpath没有获取div标签内html内容的功能,也就是获取div或a标签中的innerhtml,写了个小程序实现一下: 源代码 [webadmin@centos7 csdnd4q] #162> vim /mywork/python/csdnd4q/z040.py #去掉最外层标签,保留其内的所有html标记和文本 def getinnerhtml(data): return data[data.find(">")+1:data.rfind("<
-
Python xpath表达式如何实现数据处理
xpath表达式 1. xpath语法 <bookstore> <book> <title lang="eng">Harry Potter</title> <price>999</price> </book> <book> <title lang="eng">Learning XML</title> <price>888</pri
-
Python自动化xpath实现自动抢票抢货
小伙伴们,这次推文讲的是'xpath',掌握起来不难的哦.而且,熟悉了这套路,别说pubmed,任何你能在浏览器实现的操作,都基本能通过selenium自动化进行. 总代码: for i in range(51,56): driver.implicitly_wait(10) ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-results-panel-trigger"]'))
-
python+selenium实现自动抢票功能实例代码
简介 什么是Selenium? Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件.执行测试和记录测试结果.它采用Javascript单元测试工具JSUnit为核心,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等等,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件.(Selenium的
-

为了顺利买到演唱会的票用Python制作了自动抢票的脚本
目录 知识点: 开发环境: 先导入本次所需的模块 第一步,实现免登录 确定目标,设置全局变量 初始化加载 登录调用设置cookie 获取cookie 登录 打开浏览器 第二步,抢票并下单 判断元素是否存在 选票操作 选择座位 下单操作 抢票完成,退出 测试代码是否成功 最后看下效果如何 知识点: 面向对象编程 selenium 操作浏览器 pickle 保存和读取Cookie实现免登陆 time 做延时操作 os 创建文件,判断文件是否存在 开发环境: 版 本:anaconda5.2.0(pyt
-
python自动12306抢票软件实现代码
昨天我发的是抓取的12306数据包,然后分析了一下,今天按照昨天的分析 用代码实现了,如果有需要的同学们可以看一下,实现的功能有,登录,验证码识别,自动查票,有余票点击预定, 差了最后一步提交订单.同学们可以自己研究一下. import requests import time import dmpt import re import random from copyheaders import headers_raw_to_dict DEFAULT_HEADERS={ 'Host':'kyfw
-
python实现12306抢票及自动邮件发送提醒付款功能
#写在前面,这个程序我已经弄出来了,但是因为黄牛泛滥以及懒人太多,整个程序的代码就不贴出来了,这里纯粹就是技术交流. 只做技术交流..... 嗯,程序结束后,自己还是得手动付款. 废话不多说,下面就直接开始技术主要部分阐述. 先讲理论部分:首先我们需要代码实现一个浏览器功能,那么模块基本上可以确定urllib.parse.urllib.request,这两个包都是和网址有关的模块,那么咱们去登录一个网址,特别是有验证码这些的网址,我们登录进去是不是就行了?答案是对的,但是我们用代码实现的话,这个
-
python+splinter自动刷新抢票功能
抢票脚本,python +splinter自动刷新抢票,可以成功抢到(依赖自己的网络环境太厉害,还有机器的好坏),但是感觉不是很完美. 有大神请指导完善一下(或者有没有别的好点的思路),不胜感谢. # -*- coding: utf-8 -*- """ @author: liuyw """ from splinter.browser import Browser from time import sleep import traceback im
-
Python + selenium + requests实现12306全自动抢票及验证码破解加自动点击功能
测试结果: 整个买票流程可以再快一点,不过为了稳定起见,有些地方等待了一些时间 完整程序,拿去可用 整个程序分了三个模块:购票模块(主体).验证码识别模块.余票查询模块 购票模块: from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.commo
-
春节到了 教你使用python来抢票回家
这篇文章主要介绍了春节到了 教你使用python来抢票回家,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 不知不觉,一年一度的春运抢票大幕已经拉开,想快速抢到回家的车票吗?作为程序员,这些技术手段,你一定要知道. 为了让大家更快捷更便利的抢火车票,各种各样的抢票软件应需而生,这类软件大部分都是付费抢票的机制. 作为程序员,如何用技术手段抢到回家的票?来看看用 Python 写的抢票脚本. 手把手教你用 Python 抢票回家过年 环境介绍 wi
-
手把手教你用python抢票回家过年(代码简单)
首先看看如何快速查看剩余火车票? 当你想查询一下火车票信息的时候,你还在上12306官网吗?或是打开你手机里的APP?下面让我们来用Python写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习. 接口设计 一个应用写出来最终是要给人使用的,哪怕只是给你自己使用.所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets好了.我们希望用户只要输入出发站,到达站以
-
火车票抢票python代码公开揭秘!
市场上很多火车票抢票软件大家应该非常熟悉,但很少有人研究具体是怎么实现的,所以觉得很神秘,其实很简单.下面使用Python模拟抢票程序,给大家揭秘抢票到底是怎么回事. 该代码仅供参考,主要用于大家沟通交流,禁止用于商业用途. 具体代码如下,可以修改成自己的12306用户名账号: # -*- coding: utf-8 -*- from splinter.browser import Browser from time import sleep import traceback import ti