Python如何使用ElementTree解析xml
以country.xml为例,内容如下:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
1.解析
1)调用parse()方法,返回解析树
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
tree = ET.parse("country.xml") # <class 'xml.etree.ElementTree.ElementTree'>
root = tree.getroot() # 获取根节点 <Element 'data' at 0x02BF6A80>
2)调用from_string(),返回解析树的根元素
import xml.etree.ElementTree as ET
data = open("country.xml").read()
root = ET.fromstring(data) # <Element 'data' at 0x036168A0>
3)调用ElementTree类ElementTree(self, element=None, file=None) # 这里的element作为根节点
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file="country.xml") # <xml.etree.ElementTree.ElementTree object at 0x03031390>
root = tree.getroot() # <Element 'data' at 0x030EA600>
1)简单遍历
import xml.etree.ElementTree as ET
tree = ET.parse("country.xml")
root = tree.getroot()
print(root.tag, ":", root.attrib) # 打印根元素的tag和属性
# 遍历xml文档的第二层
for child in root:
# 第二层节点的标签名称和属性
print(child.tag,":", child.attrib)
# 遍历xml文档的第三层
for children in child:
# 第三层节点的标签名称和属性
print(children.tag, ":", children.attrib)
可以通过下标的方式直接访问节点
# 访问根节点下第一个country的第二个节点year,获取对应的文本
year = root[0][1].text # 2008
2)ElementTree提供的方法
find(match) # 查找第一个匹配的子元素, match可以时tag或是xpaht路径
findall(match) # 返回所有匹配的子元素列表
findtext(match, default=None) #
iter(tag=None) # 以当前元素为根节点 创建树迭代器,如果tag不为None,则以tag进行过滤
iterfind(match) #
例子:
# 过滤出所有neighbor标签
for neighbor in root.iter("neighbor"):
print(neighbor.tag, ":", neighbor.attrib)
# 遍历所有的counry标签
for country in root.findall("country"):
# 查找country标签下的第一个rank标签
rank = country.find("rank").text
# 获取country标签的name属性
name = country.get("name")
print(name, rank)
1) 属性相关
# 将所有的rank值加1,并添加属性updated为yes
for rank in root.iter("rank"):
new_rank = int(rank.text) + 1
rank.text = str(new_rank) # 必须将int转为str
rank.set("updated", "yes") # 添加属性
# 再终端显示整个xml
ET.dump(root)
# 注意 修改的内容存在内存中 尚未保存到文件中
# 保存修改后的内容
tree.write("output.xml")
import xml.etree.ElementTree as ET
tree = ET.parse("output.xml")
root = tree.getroot()
for rank in root.iter("rank"):
# attrib为属性字典
# 删除对应的属性updated
del rank.attrib['updated']
ET.dump(root)
小结: 关于classxml.etree.ElementTree.Element 属性相关
- attrib 为包含元素属性的字典
- keys() 返回元素属性名称列表
- items() 返回(name,value)列表
- get(key, default=None) 获取属性
- set(key, value) # 跟新/添加 属性
- del xxx.attrib[key] # 删除对应的属性
2) 节点/元素 相关
删除子元素remove()
import xml.etree.ElementTree as ET
tree = ET.parse("country.xml")
root = tree.getroot()
# 删除rank大于50的国家
for country in root.iter("country"):
rank = int(country.find("rank").text)
if rank > 50:
# remove()方法 删除子元素
root.remove(country)
ET.dump(root)
添加子元素
代码:
import xml.etree.ElementTree as ET
tree = ET.parse("country.xml")
root = tree.getroot()
country = root[0]
last_ele = country[len(list(country))-1]
last_ele.tail = '\n\t\t'
# 创建新的元素, tag为test_append
elem1 = ET.Element("test_append")
elem1.text = "elem 1"
# elem.tail = '\n\t'
country.append(elem1)
# SubElement() 其实内部调用的时append()
elem2 = ET.SubElement(country, "test_subelement")
elem2.text = "elem 2"
# extend()
elem3 = ET.Element("test_extend")
elem3.text = "elem 3"
elem4 = ET.Element("test_extend")
elem4.text = "elem 4"
country.extend([elem3, elem4])
# insert()
elem5 = ET.Element("test_insert")
elem5.text = "elem 5"
country.insert(5, elem5)
ET.dump(country)
效果:

添加子元素方法总结:
- append(subelement)
- extend(subelements)
- insert(index, element)
4.创建xml文档
想创建root Element,然后创建SubElement,最后将root element传入ElementTree(element),创建tree,调用tree.write()方法写入文件
对于创建元素的3个方法: 使用ET.Element、Element对象的makeelement()方法以及ET.SubElement
import xml.etree.ElementTree as ET
def subElement(root, tag, text):
ele = ET.SubElement(root, tag)
ele.text = text
ele.tail = '\n'
root = ET.Element("note")
to = root.makeelement("to", {})
to.text = "peter"
to.tail = '\n'
root.append(to)
subElement(root, "from", "marry")
subElement(root, "heading", "Reminder")
subElement(root, "body", "Don't forget the meeting!")
tree = ET.ElementTree(root)
tree.write("note.xml", encoding="utf-8", xml_declaration=True)
效果:
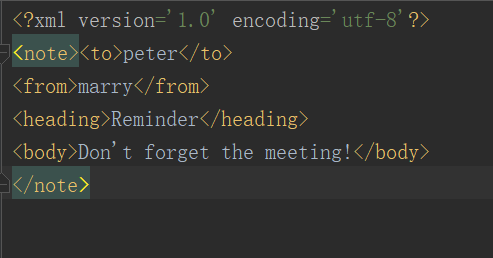
由于原生保存的XML时默认无缩进,如果想要设置缩进的话, 需要修改保存方式
代码:
import xml.etree.ElementTree as ET
from xml.dom import minidom
def subElement(root, tag, text):
ele = ET.SubElement(root, tag)
ele.text = text
def saveXML(root, filename, indent="\t", newl="\n", encoding="utf-8"):
rawText = ET.tostring(root)
dom = minidom.parseString(rawText)
with open(filename, 'w') as f:
dom.writexml(f, "", indent, newl, encoding)
root = ET.Element("note")
to = root.makeelement("to", {})
to.text = "peter"
root.append(to)
subElement(root, "from", "marry")
subElement(root, "heading", "Reminder")
subElement(root, "body", "Don't forget the meeting!")
# 保存xml文件
saveXML(root, "note.xml")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python利用ElementTree模块处理XML的方法详解
前言 最近因为工作的需要,在使用 Python 来发送 SOAP 请求以测试 Web Service 的性能,由于 SOAP 是基于 XML 的,故免不了需要使用 python 来处理 XML 数据.在对比了几种方案后,最后选定使用 xml.etree.ElementTree 模块来实现. 这篇文章记录了使用 xml.etree.ElementTree 模块常用的几个操作,也算是总结一下,免得以后忘记了.分享出来也方法需要的朋友们参考学习,下面话不多说了,来一起看看详细的介绍吧. 概述 对比其他
-
python xml.etree.ElementTree遍历xml所有节点实例详解
python xml.etree.ElementTree遍历xml所有节点 XML文件内容: <students> <student name='刘备' sex='男' age='35'/> <student name='吕布' sex='男' age='38'/> <student name='貂蝉' sex='女' age='22'/> </students> 代码: #-*- coding: UTF-8 -*- # 从文件中读取数据 imp
-
Python使用ElementTree美化XML格式的操作
Python中使用ElementTree可以很方便的处理XML,但是产生的XML文件内容会合并在一行,难以看清楚. 如下格式: <root><aa>aatext<cc>cctext</cc></aa><bb>bbtext<dd>ddtext<ee>eetext</ee></dd></bb></root> 使用minidom模块中的toprettyxml和write
-
Python3 xml.etree.ElementTree支持的XPath语法详解
xml.etree.ElementTree可以通过支持的有限的XPath表达式来定位元素. 语法 ElementTree支持的语法如下: 语法 说明 tag 查找所有具有指定名称tag的子元素.例如:country表示所有名为country的元素,country/rank表示所有名为country的元素下名为rank的元素. * 查找所有元素.如:*/rank表示所有名为rank的孙子元素. . 选择当前元素.在xpath表达式开头使用,表示相对路径. // 选择当前元素下所有级别的所有子元素.
-
python网络编程学习笔记(八):XML生成与解析(DOM、ElementTree)
xml.dom篇 DOM是Document Object Model的简称,XML 文档的高级树型表示.该模型并非只针对 Python,而是一种普通XML 模型.Python 的 DOM 包是基于 SAX 构建的,并且包括在 Python 2.0 的标准 XML 支持里. 一.xml.dom的简单介绍 1.主要方法: minidom.parse(filename):加载读取XML文件doc.documentElement:获取XML文档对象node.getAttribute(AttributeN
-
Python中使用ElementTree解析XML示例
[XML基本概念介绍] XML 指可扩展标记语言(eXtensible Markup Language). XML 被设计用来传输和存储数据. 概念一: 复制代码 代码如下: <foo> # foo元素的起始标签 </foo> # foo元素的结束标签 # note: 每一个起始标签必须有对应的结束标签来闭合, 也可以写成<foo/> 概念二: 复制代码 代码如下: <foo> # 元素可以嵌套
-
python通过ElementTree操作XML获取结点读取属性美化XML
1.引入库需要用到3个类,ElementTree,Element以及建立子类的包装类SubElement from xml.etree.ElementTree import ElementTreefrom xml.etree.ElementTree import Elementfrom xml.etree.ElementTree import SubElement as SE 2.读入并解析tree = ElementTree(file=xmlfile)root = tree.getroot()
-
利用 Python ElementTree 生成 xml的实例
Python 处理 xml 文档的方法有很多,除了经典的 sax 和 dom 之外,还有一个 ElementTree. 首先 import 之: from xml.etree import ElementTree as etree 然后开始构建 xml 树: from xml.etree.ElementTree import Element, SubElement, ElementTree # 生成根节点 root = Element('root') # 生成第一个子节点 head head =
-
Python如何使用ElementTree解析xml
以country.xml为例,内容如下: <?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name=&qu
-
Python使用sax模块解析XML文件示例
本文实例讲述了Python使用sax模块解析XML文件.分享给大家供大家参考,具体如下: XML样例: <?xml version="1.0"?> <collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format>
-
python标准库ElementTree处理xml
目录 1. 示例用法 Element对象具有如下属性和操作 遇到非法格式的xml ExpatError: no element found ExpatError: mismatched tag ExpatError: not well-formed(invalid token) 1. 示例用法 参照官方文档,创建country_data.xml测试文档,内容如下: <?xml version="1.0"?> <data> <country name=&qu
-
Python中使用SAX解析xml实例
SAX是一种基于事件驱动的API.利用SAX解析XML文档牵涉到两个部分:解析器和事件处理器.解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;而事件处理器则负责对事件作出相应,对传递的XML数据进行处理. 实例: 复制代码 代码如下: import sys, string from xml.sax import handler, make_parser class TestHandler(handler.ContentHandler):
-

深入解读Python解析XML的几种方式
在XML解析方面,Python贯彻了自己"开箱即用"(batteries included)的原则.在自带的标准库中,Python提供了大量可以用于处理XML语言的包和工具,数量之多,甚至让Python编程新手无从选择. 本文将介绍深入解读利用Python语言解析XML文件的几种方式,并以笔者推荐使用的ElementTree模块为例,演示具体使用方法和场景.文中所使用的Python版本为2.7. 一.什么是XML? XML是可扩展标记语言(Extensible Markup Langu
-
横向对比分析Python解析XML的四种方式
在最初学习PYTHON的时候,只知道有DOM和SAX两种解析方法,但是其效率都不够理想,由于需要处理的文件数量太大,这两种方式耗时太高无法接受. 在网络搜索后发现,目前应用比较广泛,且效率相对较高的ElementTree也是一个比较多人推荐的算法,于是拿这个算法来实测对比,ElementTree也包括两种实现,一个是普通ElementTree(ET),一个是ElementTree.iterparse(ET_iter). 本文将对DOM.SAX.ET.ET_iter四种方式进行横向对比,通过处理相
-
用Python解析XML的几种常见方法的介绍
一.简介 XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用.它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性. python解析XML常见的有三种方法:一是xml.dom.*模块,它是W3C DOM API的实现,若需要处理DOM API则该模块很适合,注意xml.dom包里面有许多模块
-
python解析xml文件方式(解析、更新、写入)
Overview 这篇博客内容将包括对XML文件的解析.追加新元素后写入到XML,以及更新原XML文件中某结点的值.使用的是python的xml.dom.minidom包,详情可见其官方文档:xml.dom.minidom官方文档.全文都将围绕以下的customer.xml进行操作: <?xml version="1.0" encoding="utf-8" ?> <!-- This is list of customers --> <c