C# 实现抓取网站页面内容的实例方法
抓取新浪网的新闻栏目,如图所示:
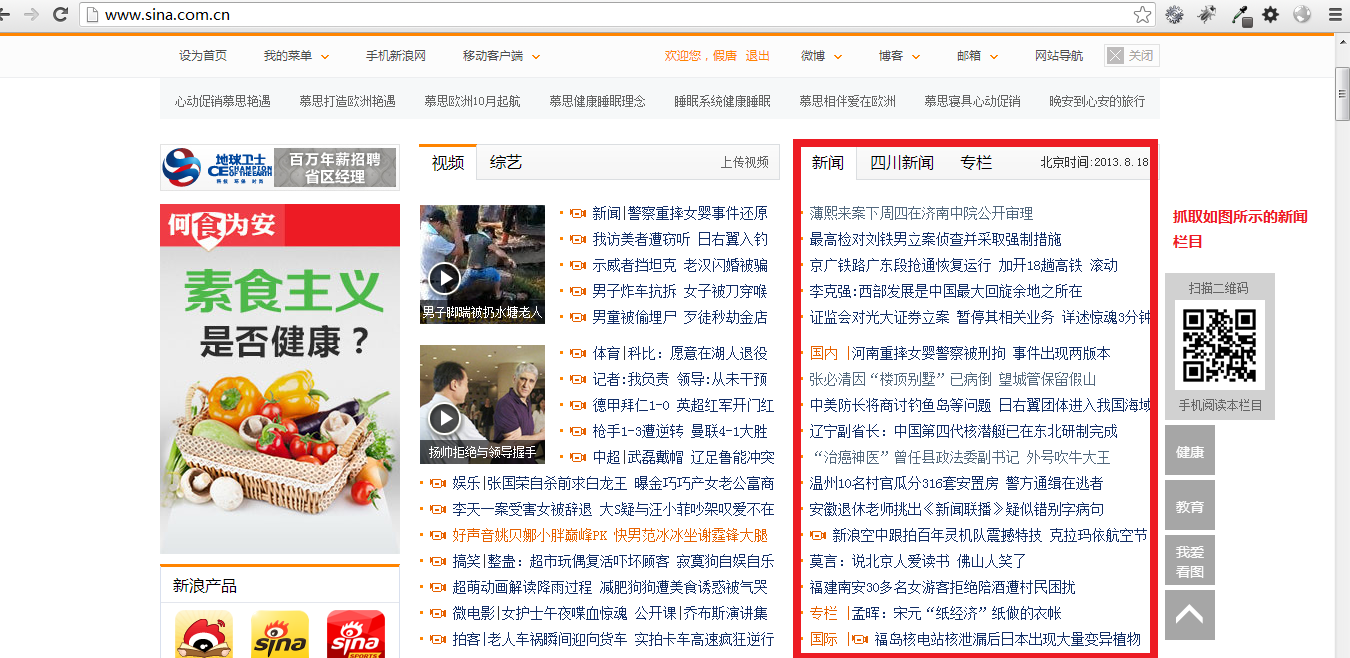
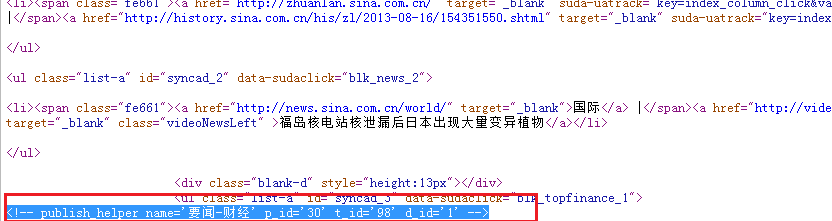
使用 谷歌浏览器的查看源代码: 通过分析得知,我们所要找的内容在以下两个标签之间:
代码如下:
<!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' -->
内容。。。。
<!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' -->
如图所示:

内容。。。。
使用VS建立一个如图所示的网站:
我们下载网络数据主要通过 WebClient 类来实现。
protected void Enter_Click(object sender, EventArgs e)
{
WebClient we = new WebClient(); //主要使用WebClient类
byte[] myDataBuffer;
myDataBuffer = we.DownloadData(txtURL.Text); //该方法返回的是 字节数组,所以需要定义一个byte[]
string download = Encoding.Default.GetString(myDataBuffer); //对下载的数据进行编码
//通过查询源代码,获取某两个值之间的新闻内容
int startIndex = download.IndexOf("<!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' -->");
int endIndex = download.IndexOf("<!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' -->");
string temp = download.Substring(startIndex, endIndex - startIndex + 1); //截取新闻内容
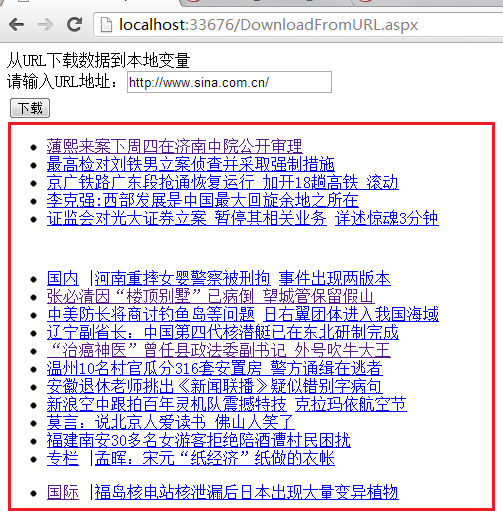
lblMessage.Text = temp;//显示所截取的新闻内容
}
效果如图:
最后: 除了把下载的数据保存为文本以外,还可以保存为 文件类型 和 流 类型。
代码如下:
WebClient wc = new WebClient();
wc.DownloadFile(TextBox1.Text, @"F:\test.txt");
Label1.Text = "文件下载完成";
WebClient wc = new WebClient();
Stream s = wc.OpenRead(TextBox1.Text);
StreamReader sr = new StreamReader(s);
Label1.Text = sr.ReadToEnd();
相关推荐
-
C#实现通过程序自动抓取远程Web网页信息的代码
通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在根据得到的数据进行数据分析.为业务提供参考数据. 为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库.那么我们的思路就是: 1.发送HttpRequest请求. 2.接收HttpResponse返回的结果.得到特定页面的html源文件. 3.取出包含数据的那一部分源码. 4.根据html源码生成HtmlD
-
C#实现抓取和分析网页类实例
本文实例讲述了C#实现抓取和分析网页类.分享给大家供大家参考.具体分析如下: 这里介绍了抓取和分析网页的类. 其主要功能有: 1.提取网页的纯文本,去所有html标签和javascript代码 2.提取网页的链接,包括href和frame及iframe 3.提取网页的title等(其它的标签可依此类推,正则是一样的) 4.可以实现简单的表单提交及cookie保存 /* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
-
c#使用htmlagilitypack解析html格式字符串
使用方法: 1.引用HtmlAgilityPack.dll文件 2.引用命名空间: 复制代码 代码如下: using HtmlAgilityPack; 3.调用 复制代码 代码如下: static void Main(string[] args) { string html = GetHtml("http://www.jb51.net"); HtmlDocument doc = new HtmlDocument();
-
c#根据网址抓取网页截屏生成图片的示例
复制代码 代码如下: using System.Drawing;using System.Drawing.Imaging;using System.IO;using System.Threading;using System.Windows.Forms; public class WebsiteToImage{private Bitmap m_Bitmap;private string m_Url;private string m_FileName = string.Empty; public
-
c#远程html数据抓取实例分享
复制代码 代码如下: /// <summary> /// 获取远程html /// </summary> /// <param name="url"></param> /// <param name="methed"></param> /// <param name="param"></p
-
C# 抓取网页内容的方法
1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: view plaincopy to clipboardprint? 复制代码 代码如下: WebRequest request = WebRequest.Create("http://www.jb51.net/"); WebResponse response = request.GetResponse(); S
-
C#抓取当前屏幕并保存为图片的方法
本文实例讲述了C#抓取当前屏幕并保存为图片的方法.分享给大家供大家参考.具体分析如下: 这是一个C#实现的屏幕抓取程序,可以抓取整个屏幕保存为指定格式的图片,并且保存当前控制台缓存到文本 using System; using System.Collections.Generic; using System.ComponentModel; using System.Diagnostics; using System.Drawing; using System.Drawing.Imaging; u
-

C#使用HtmlAgilityPack抓取糗事百科内容实例
本文实例讲述了C#使用HtmlAgilityPack抓取糗事百科内容的方法.分享给大家供大家参考.具体实现方法如下: Console.WriteLine("*****************糗事百科24小时热门*******************"); Console.WriteLine("请输入页码,输入0退出"); string page = Console.ReadLine(); while (page!="0") { HtmlWeb h
-
c#实现抓取高清美女妹纸图片
c#实现抓取高清美女妹纸图片 复制代码 代码如下: private void DoFetch(int pageNum) { ThreadPool.QueueUserWorkItem(_ => { HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://me2-sex.lofter.com/tag/美女摄影?page=&
-
C# 实现抓取网站页面内容的实例方法
抓取新浪网的新闻栏目,如图所示: 使用 谷歌浏览器的查看源代码: 通过分析得知,我们所要找的内容在以下两个标签之间: 复制代码 代码如下: <!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' --> 内容.... <!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' --> 如图所示: 内容.... 使用VS建立一个如图所示的网站: 我们下载
-
Nodejs抓取html页面内容(推荐)
废话不多说,直接给大家贴node.js抓取html页面内容的核心代码了. 具体代码如下所示: var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option,
-
thinkphp 抓取网站的内容并且保存到本地的实例详解
thinkphp 抓取网站的内容并且保存到本地的实例详解 我需要写这么一个例子,到电子课本网下载一本电子书. 电子课本网的电子书,是把书的每一页当成一个图片,然后一本书就是有很多张图片,我需要批量的进行下载图片操作. 下面是代码部分: public function download() { $http = new \Org\Net\Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl =
-
Winform实现抓取web页面内容的方法
本文以一个非常简单的实例讲述了Winform实现抓取web页面内容的方法,代码简洁易懂,非常实用!分享给大家供大家参考. 具体实现代码如下: WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl); WebResponse response = request.GetResponse(); Stream resStream = response.GetRespo
-
利用curl抓取远程页面内容的示例代码
最基本的操作如下 复制代码 代码如下: $curlPost = 'a=1&b=2';//模拟POST数据$ch = curl_init();curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:0.0.0.0', 'CLIENT-IP:0.0.0.0')); //构造IPcurl_setopt($ch, CURLOPT_REFERER, "http://www.jb51.net/"); //构造来路 cur
-
利用NodeJS和PhantomJS抓取网站页面信息以及网站截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了.例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的.所以这里需要另一个语言来支撑服务,这里选用NodeJS来完成. 安装PhantomJS 首先,去PhantomJS官网下载对应平台的版本,或者下载源代码自行编译.然后将PhantomJS配置进环境变量,输入 $ phantomjs 如果有反应,那么就可以进行下一步了. 利用PhantomJS进行简
-
python通过链接抓取网站详解
在本篇文章里,你将会学习把这些基本方法融合到一个更灵活的网站 爬虫中,该爬虫可以跟踪任意遵循特定 URL 模式的链接. 这种爬虫非常适用于从一个网站抓取所有数据的项目,而不适用于从特 定搜索结果或页面列表抓取数据的项目.它还非常适用于网站页面组织 得很糟糕或者非常分散的情况. 这些类型的爬虫并不需要像上一节通过搜索页面进行抓取中采用的定位 链接的结构化方法,因此在 Website 对象中不需要包含描述搜索页面 的属性.但是由于爬虫并不知道待寻找的链接的位置,所以你需要一些 规则来告诉它选择哪种页
-
PHP封装的远程抓取网站图片并保存功能类
本文实例讲述了PHP封装的远程抓取网站图片并保存功能类.分享给大家供大家参考,具体如下: <?php /** * 一个用于抓取图片的类 * * @package default * @author WuJunwei */ class download_image { public $save_path; //抓取图片的保存地址 //抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片 public $img_size=0; //定义一个静态数组,用于记录曾经抓取过的的超链接地址,避
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
C#使用正则表达式抓取网站信息示例
本文实例讲述了C#使用正则表达式抓取网站信息的方法.分享给大家供大家参考,具体如下: 这里以抓取京东商城商品详情为例. 1.创建JdRobber.cs程序类 public class JdRobber { /// <summary> /// 判断是否京东链接 /// </summary> /// <param name="param"></param> /// <returns></returns> public