详细分析Linux文件系统
本片文章针对Linux文件系统从原理到运行机制做了非常详细的理论分析,有助于读者对此深入的理解,以下是具体内容:
Linux上的文件系统一般来说就是EXT2或EXT3,但这篇文章并不准备一上来就直接讲它们,而希望结合Linux操作系统并从文件系统建立的基础——硬盘开始,一步步认识Linux的文件系统。
1.机械硬盘的物理存储机制
现代计算机大部分文件存储功能都是由机械硬盘这种设备提供的。(现在的SSD和闪存从概念和逻辑上都部分继承自机械硬盘,所以使用机械硬盘来进行理解也是没有问题的)
机械硬盘能实现信息存储的功能基于:磁性存储介质能够被磁化,且磁化后会长久保留被磁化的状态,这种被磁化状态能够被读取出来,同时这种磁化状态还能够不断被修改,磁化正好有两个方向,所以可以表示0和1。
于是硬盘就是把这种磁性存储介质做成一个个盘片,每一个盘片上都分布着数量巨大的磁性存储单位,使用磁性读写头对盘片进行写入和读取(从原理上类似黑胶唱片的播放)。
一个硬盘中的磁性存储单位数以亿计(1T硬盘就有约80亿个),所以需要一套规则来规划信息如何存取(比如一本存储信息的书我们还会分为页,每一页从上到下从左到右读取,同时还有章节目录)
于是就有了这些物理、逻辑概念:
一个硬盘有多张盘片叠成,不同盘片有编号每张盘片上的存储颗粒成环形一圈圈地排布,每一圈称为磁道,有编号每条磁道上都有一圈存储颗粒,每512*8(512字节,0.5KB)个存储颗粒作为一个扇区,扇区是硬盘上存储的最小物理单位 N个扇区可以组成簇,N取决于不同的文件系统或是文件系统的配置,簇是此文件系统中的最小存储单位所有盘面上的同一磁道构成一个圆柱,称为柱面,柱面是系统分区的最小单位
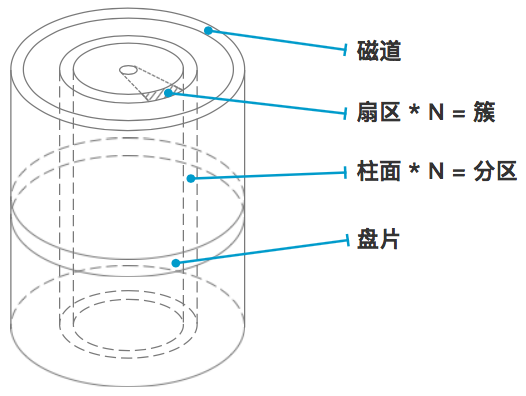
磁头读写文件的时候,首先是分区读写的,由inode编号(区内唯一的编号后面介绍)找到对应的磁道和扇区,然后一个柱面一个柱面地进行读写。机械硬盘的读写控制系统是一个令人叹为观止的精密工程(一个盘面上有几亿个存储单位,每个磁道宽度不到几十纳米,磁盘每分钟上万转),同时关于读写的逻辑也是有诸多细节(比如扇区的编号并不是连续的),非常有意思,可以自行搜索文章拓展阅读。
有了硬盘并不意味着LInux可以立刻把它用来存储,还需要组合进Linux的文件体系才能被Linux使用。
2.Linux文件体系
Linux以文件的形式对计算机中的数据和硬件资源进行管理,也就是彻底的一切皆文件,反映在Linux的文件类型上就是:普通文件、目录文件(也就是文件夹)、设备文件、链接文件、管道文件、套接字文件(数据通信的接口)等等。而这些种类繁多的文件被Linux使用目录树进行管理, 所谓的目录树就是以根目录(/)为主,向下呈现分支状的一种文件结构。不同于纯粹的ext2之类的文件系统,我把它称为文件体系,一切皆文件和文件目录树的资源管理方式一起构成了Linux的文件体系,让Linux操作系统可以方便使用系统资源。
所以文件系统比文件体系涵盖的内容少很多,Linux文件体系主要在于把操作系统相关的东西用文件这个载体实现:文件系统挂载在操作系统上,操作系统整个系统又放在文件系统里。但本文中文件体系的相关内容不是很多,大部分地方都可以用文件系统代替文件体系。
Linux中的文件类型
那就先简单说说Linux中的文件类型,主要关注普通文件、目录文件和符号连接文件。
普通文件(-) 从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件 Linux用户可以根据访问权限对普通文件进行查看、更改和删除 目录文件(d,directory file) 目录文件对于用惯Windows的用户来说不太容易理解,目录也是文件的一种目录文件包含了各自目录下的文件名和指向这些文件的指针,打开目录事实上就是打开目录文件,只要有访问权限,你就可以随意访问这些目录下的文件(普通文件的执行权限就是目录文件的访问权限),但是只有内核的进程能够修改它们虽然不能修改,但是我们能够通过vim去查看目录文件的内容 符号链接(l,symbolic link) 这种类型的文件类似Windows中的快捷方式,是指向另一个文件的间接指针,也就是我们常说的软链接 块设备文件(b,block)和字符设备文件(c,char) 这些文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到比如磁盘光驱就是块设备文件,串口设备则属于字符设备文件系统中的所有设备要么是块设备文件,要么是字符设备文件,无一例外 FIFO(p,pipe) 管道文件主要用于进程间通讯。比如使用mkfifo命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据,先进先出,随写随读。 套接字(s,socket) 用于进程间的网络通信,也可以用于本机之间的非网络通信这些文件一般隐藏在/var/run目录下,证明着相关进程的存在
Linux 的文件是没有所谓的扩展名的,一个 Linux文件能不能被执行与它是否可执行的属性有关,只要你的权限中有 x ,比如[ -rwx-r-xr-x ] 就代表这个文件可以被执行,与文件名没有关系。跟在 Windows下能被执行的文件扩展名通常是 .com .exe .bat 等不同。
不过,可以被执行跟可以执行成功不一样。比如在 root 主目彔下的 install.log 是一个文本文件,修改权限成为 -rwxrwxrwx 后这个文件能够真的执行成功吗? 当然不行,因为它的内容根本就没有可以执行的数据。所以说,这个 x 代表这个文件具有可执行的能力, 但是能不能执行成功,当然就得要看该文件的内容了。
虽然如此,不过我们仍然希望能从扩展名来了解该文件是什么东西,所以一般我们还是会以适当的扩展名来表示该文件是什么种类的。
所以Linux 系统上的文件名真的只是让你了解该文件可能的用途而已, 真正的执行与否仍然需要权限的规范才行。比如常见的/bin/ls 这个显示文件属性的指令要是权限被修改为无法执行,那么ls 就变成不能执行了。这种问题最常发生在文件传送的过程中。例如你在网络上下载一个可执行文件,但是偏偏在你的 Linux 系统中就是无法执行,那就可能是档案的属性被改变了。而且从网络上传送到你 的 Linux 系统中,文件的属性权限确实是会被改变的
Linux目录树
对Linux系统和用户来说,所有可操作的计算机资源都存在于目录树这个逻辑结构中,对计算机资源的访问都可以认为是目录树的访问。就硬盘来说,所有对硬盘的访问都变成了对目录树中某个节点也就是文件夹的访问,访问时不需要知道它是硬盘还是硬盘中的文件夹。
目录树的逻辑结构也非常简单,就是从根目录(/)开始,不断向下展开各级子目录。
3.硬盘分区
硬盘分区是硬盘结合到文件体系的第一步,本质是「硬盘」这个物理概念转换成「区」这个逻辑概念,为下一步格式化做准备。
所以分本身并不是必须的,你完全可以把一整块硬盘作为一个区。但从数据的安全性以及系统性能角度来看,分区还是有很多用处的,所以一般都会对硬盘进行分区。
讲分区就不得不先提每块硬盘上最重要的第一扇区,这个扇区中有硬盘主引导记录(Master boot record, MBR) 及分区表(partition table), 其中 MBR 占有 446 bytes,而分区表占有 64 bytes。硬盘主引导记录放有最基本的引导加载程序,是系统开机启动的关键环节,在附录中有更详细的说明。而分区表则跟分区有关,它记录了硬盘分区的相关信息,但因分区表仅有 64bytes , 所以最多只能记彔四块分区(分区本身其实就是对分区表进行设置)。
只能分四个区实在太少了,于是就有了扩展分区的概念,既然第一个扇区所在的分区表只能记录四条数据, 那我可否利用额外的扇区来记录更多的分区信息。
把普通可以访问的分区称为主分区,扩展分区不同于主分区,它本身并没有内容,它是为进一步逻辑分区提供空间的。在某块分区指定为扩展分区后,就可以对这块扩展分区进一步分成多个逻辑分区。操作系统规定:
四块分区每块都可以是主分区或扩展分区扩展分区最多只能有一个(也没必要有多个)扩展分区可以进一步分割为多个逻辑分区扩展分区只是逻辑概念,本身不能被访问,也就是不能被格式化后作为数据访问的分区,能够作为数据访问的分区只有主分区和逻辑分区逻辑分区的数量依操作系统而不同,在 Linux 系统中,IDE 硬盘最多有 59 个逻辑分区(5 号到 63 号), SATA 硬盘则有 11 个逻辑分区(5 号到 15 号)
一般给硬盘进行分区时,一个主分区一个扩展分区,然后把扩展分区划分为N个逻辑分区是最好的
是否可以不要主分区呢?不知道,但好像不用管,你创建分区的时候会自动给你配置类型特殊的,你最好单独分一个swap区(内存置换空间),它独为一类,功能是:当有数据被存放在物理内存里面,但是这些数据又不是常被 CPU 所取用时,那么这些不常被使用的程序将会被丢到硬盘的 swap 置换空间当中, 而将速度较快的物理内存空间释放出来给真正需要的程序使用
4.格式化
我们知道Linux操作系统支持很多不同的文件系统,比如ext2、ext3、XFS、FAT等等,而Linux把对不同文件系统的访问交给了VFS(虚拟文件系统),VFS能访问和管理各种不同的文件系统。所以有了区之后就需要把它格式化成具体的文件系统以便VFS访问。
标准的Linux文件系统Ext2是使用「基于inode的文件系统」
我们知道一般操作系统的文件数据除了文件实际内容外, 还带有很多属性,例如 Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、 时间参数等),文件系统通常会将属性和实际内容这两部分数据分别存放在不同的区块在基于inode的文件系统中,权限与属性放置到 inode 中,实际数据放到 data block 区块中,而且inode和data block都有编号
Ext2 文件系统在此基础上
文件系统最前面有一个启动扇区(boot sector) 这个启动扇区可以安装开机管理程序, 这个设计让我们能将不同的引导装载程序安装到个别的文件系统前端,而不用覆盖整个硬盘唯一的MBR, 也就是这样才能实现多重引导的功能 把每个区进一步分为多个块组 (block group),每个块组有独立的inode/block体系 如果文件系统高达数百 GB 时,把所有的 inode 和block 通通放在一起会因为 inode 和 block的数量太庞大,不容易管理这其实很好理解,因为分区是用户的分区,实际计算机管理时还有个最适合的大小,于是计算机会进一步的在分区中分块(但这样岂不是可能出现大文件放不了的问题?有什么机制善后吗?) 每个块组实际还会分为分为6个部分,除了inode table 和 data block外还有4个附属模块,起到优化和完善系统性能的作用
所以整个分区大概会这样划分:

inode table 主要记录文件的属性以及该文件实际数据是放置在哪些block中,它记录的信息至少有这些: 大小、真正内容的block号码(一个或多个)访问模式(read/write/excute) 拥有者与群组(owner/group) 各种时间:建立或状态改变的时间、最近一次的读取时间、最近修改的时间没有文件名!文件名在目录的block中! 一个文件占用一个 inode,每个inode有编号 Linux 系统存在 inode 号被用完但磁盘空间还有剩余的情况注意,这里的文件不单单是普通文件,目录文件也就是文件夹其实也是一个文件,还有其他的也是 inode 的数量与大小在格式化时就已经固定了,每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes) 文件系统能够建立的文件数量与inode 的数量有关,存在空间还够但inode不够的情况系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容 inode 要记录的资料非常多,但偏偏又只有128bytes , 而inode 记录一个block 号码要花掉4byte ,假设我一个文件有400MB 且每个block 为4K 时, 那么至少也要十万条block 号码的记录!inode 哪有这么多空间来存储?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区(详细见附录) data block 放置文件内容数据的地方在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化) 在Ext2文件系统中所支持的block大小有1K, 2K及4K三种,由于block大小的区别,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量各不相同: Block 大小 1KB 2KB 4KB 最大单一档案限制 16GB 256GB 2TB 最大档案系统总容量 2TB 8TB 16TB 每个block 内最多只能够放置一个文件的资料,但一个文件可以放在多个block中(大的话)若文件小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费) 所以如果你的档案都非常小,但是你的block 在格式化时却选用最大的4K 时,可能会产生容量的浪费既然大的block 可能会产生较严重的磁碟容量浪费,那么我们是否就将block 大小定为1K ?这也不妥,因为如果block 较小的话,那么大型档案将会占用数量更多的block ,而inode 也要记录更多的block 号码,此时将可能导致档案系统不良的读写效能事实上现在的磁盘容量都太大了,所以一般都会选择4K 的block 大小 superblock 记录整个文件系统相关信息的地方,一般大小为1024bytes,记录的信息主要有: block 与inode 的总量未使用与已使用的inode / block 数量一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1 block 与inode 的大小 (block 为1, 2, 4K,inode 为128bytes 或256bytes);其他各种文件系统相关信息:filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁碟(fsck) 的时间 Superblock是非常重要的, 没有Superblock ,就没有这个文件系统了,因此如果superblock死掉了,你的文件系统可能就需要花费很多时间去挽救每个块都可能含有superblock,但是我们也说一个文件系统应该仅有一个superblock 而已,那是怎么回事?事实上除了第一个块内会含有superblock 之外,后续的块不一定含有superblock,而若含有superblock则该superblock主要是做为第一个块内superblock的备份,这样可以进行superblock的救援 Filesystem Description 文件系统描述这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间 block bitmap 块对照表如果你想要新增文件时要使用哪个block 来记录呢?当然是选择「空的block」来记录。那你怎么知道哪个block 是空的?这就得要通过block bitmap了,它会记录哪些block是空的,因此我们的系统就能够很快速的找到可使用的空间来记录同样在你删除某些文件时,那些文件原本占用的block号码就得要释放出来, 此时在block bitmap 中对应该block号码的标志位就得要修改成为「未使用中」 inode bitmap 与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码
5.挂载
在一个区被格式化为一个文件系统之后,它就可以被Linux操作系统使用了,只是这个时候Linux操作系统还找不到它,所以我们还需要把这个文件系统「注册」进Linux操作系统的文件体系里,这个操作就叫「挂载」 (mount)。
挂载是利用一个目录当成进入点(类似选一个现成的目录作为代理),将文件系统放置在该目录下,也就是说,进入该目录就可以读取该文件系统的内容,类似整个文件系统只是目录树的一个文件夹(目录)。
这个进入点的目录我们称为「挂载点」。
由于整个 Linux 系统最重要的是根目录,因此根目录一定需要挂载到某个分区。 而其他的目录则可依用户自己的需求来给予挂载到不同的分去。
到这里Linux的文件体系的构建过程其实已经大体讲完了,总结一下就是:硬盘经过分区和格式化,每个区都成为了一个文件系统,挂载这个文件系统后就可以让Linux操作系统通过VFS访问硬盘时跟访问一个普通文件夹一样。这里通过一个在目录树中读取文件的实际例子来细讲一下目录文件和普通文件。
6.目录树的读取过程
首先我们要知道
每个文件(不管是一般文件还是目录文件)都会占用一个inode 依据文件内容的大小来分配一个或多个block给该文件使用创建一个文件后,文件完整信息分布在3处地方,生成2个新文件: 文件名记录在该文件所在目录的目录文件的block中,没有新文件生成文件属性、权限信息、记录具体内容的block编号记录在inode中,inode是新生成文件文件具体内存记录在block中,block是新生成文件 因为文件名的记录是在目录的block当中,「新增/删除/更名文件名」与目录的w权限有关
所以在Linux/Unix中,文件名称只是文件的一个属性,叫别名也好,叫绰号也罢,仅为了方便用户记忆和使用,但系统内部并不需要用文件名来定为文件位置,这样处理最直观的好处就是,你可以对正在使用的文件改名,换目录,甚至放到废纸篓,都不会影响当前文件的使用,这在Windows里是无法想象的。比如你打开个Word文件,然后对其进行重命名操作,Windows会告诉你门儿都没有,关闭文件先!但在Mac里就毫无压力,因为Mac的操作系统同样采用了inode的设计。
创建文件过程
当在ext2下建立一个一般文件时, ext2 会分配一个inode 与相对于该文件大小的block 数量给该文件
例如:假设我的一个block 为4 Kbytes ,而我要建立一个100 KBytes 的文件,那么linux 将分配一个inode 与25 个block 来储存该文件但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录 创建目录过程
当在ext2文件系统建立一个目录时(就是新建了一个目录文件),文件系统会分配一个inode与至少一块block给该目录
inode记录该目录的相关权限与属性,并记录分配到的那块block号码而block则是记录在这个目录下的文件名与该文件对应的inode号 block中还会自动生成两条记录,一条是.文件夹记录,inode指向自身,另一条是..文件夹记录,inode指向父文件夹 从目录树中读取某个文件过程 因为文件名是记录在目录的block当中,因此当我们要读取某个文件时,就一定会经过目录的inode与block ,然后才能够找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的资料。由于目录树是由根目录开始,因此操作系统先通过挂载信息找到挂载点的inode号,由此得到根目录的inode内容,并依据该inode读取根目录的block信息,再一层一层的往下读到正确的文件。
举例来说,如果我想要读取/etc/passwd 这个文件时,系统是如何读取的呢?
先看一下这个文件以及有关路径文件夹的信息:
$ ll -di / /etc /etc/passwd 128 dr-xr-x r-x . 17 root root 4096 May 4 17:56 / 33595521 drwxr-x r-x . 131 root root 8192 Jun 17 00:20 /etc 36628004 -rw-r-- r-- . 1 root root 2092 Jun 17 00:20 /etc/passwd
于是该文件的读取流程为:
/的inode: 通过挂载点的信息找到inode号码为128的根目录inode,且inode规定的权限让我们可以读取该block的内容(有r与x) /的block: 经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521) etc/的inode: 读取33595521号inode得知具有r与x的权限,因此可以读取etc/的block内容 etc/的block: 经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码(36628004) passwd的inode: 读取36628004号inode得知具有r的权限,因此可以读取passwd的block内容 passwd的block: 最后将该block内容的资料读出来
附录:开机流程和硬盘主引导记录
可以稍微讲下开机流程和硬盘主引导记录(MBR,或者叫主引导分区)
一台可正常运行的计算机会在BIOS上设置一块启动硬盘,其实每块硬盘都可以作为启动盘,硬盘本身的设计提供的这种可能,这就要从硬盘上的第一个扇区说起,这个扇区中有硬盘主引导记录(Master boot record, MBR)及分区表(partition table), 其中 MBR 占有 446 bytes,而分区表则占有 64 bytes。
计算机主板上有一段写入到主板的程序BIOS,BIOS是开机之后计算机系统会主动执行的第一个程序。BIOS 会去分析计算机里面有哪些储存设备,我们以硬盘为例,BIOS 会依据使用者的设定去取得能够开机的硬盘, 并且到该硬盘里面去读取第一个扇区的MBR位置。
MBR 这个仅有 446 bytes 的硬盘容量里面会放置最基本的引导加载程序(Boot loader),它的目的是加载操作系统内核文件,由于引导加载程序是操作系统在安装的时候所提供的,所以它会认识硬盘内的文件系统格式,因此就能够读取操作系统内核文件。接下来就是内核文件的工作,也就是大家所知道癿操作系统的任务了。
所以简单说开机流程就是:
BIOS:开机主动运行的程序,会识别第一个可开机的设备 MBR-引导加载程序:第一个可开机设备的第一个扇区内的主引导分区中的引导加载程序,可读取操作系统内核文件操作系统内核文件:不同的操作系统中关于开启自己的程序
由上面的说明我们会知道,BIOS和MBR 都是硬件本身会支持的功能,到MBR中的Boot loader 则是操作系统写在 MBR 上面的一段程序了。由于 MBR 仅有 446 bytes,因此这个引导加载程序是非常小而美的,它的主要任务有:
提供菜单:用户可以选择不同的开机项目,这也是多重引导的重要功能载入操作系统内核:直接指向可开机的程序区段来启动操作系统转交其他 loader:将引导加载功能转交给其他 loader 负责 这点很有趣,表示你的计算机系统里面可能具有两个以上的引导加载程序有可能吗?我们的硬盘不是只有一个 MBR 而已?是这样,但是引导加载程序除了可以安 装在 MBR 之外, 还可以安装在每个分区的引导扇区(boot sector)内分区的引导扇区这个特色造就了『多重引导』的功能(具体可以看鸟哥的书第三章第四节) 机械硬盘物理存储结构拓展阅读 蒋致诚. 硬盘驱动器巨磁电阻 (GMR) 磁头: 从微米到纳米[J]. 物理, 2004, 33(07): 0-0. 近年来电脑硬盘存储密度的飞速增长最关键的因素是自旋阀纳米多层膜结构,即巨磁电阻(GMR)读传感器磁头的应用。巨磁电阻磁头读传感器已经实现由微电子器件向纳米电子器件转化,这一过程包含了自旋电子学、材料科学、微电子工程学、化学、微机械力学和工程学等诸学科和相关微加工技术综合性挑战极限。 磁盘工作原理揭秘大多数永久性或半永久性电脑数据都是将磁盘上的一小片金属物质磁化来实现。然后再将这些磁性图可被转换成原始数据。 机械硬盘内部硬件结构和工作原理详解给扇区编号的最简单方法是l,2,3,4,5,6等顺序编号。如果扇区按顺序绕着磁道依次编号,那么,控制器在处理一个扇区的数据期间,磁盘旋转太远,超过扇区间的间隔(这个间隔很小),控制器要读出或写入的下一扇区已经通过磁头,也许是相当大的一段距离。在这种情况下,磁盘控制器就只能等待磁盘再次旋转几乎一周,才能使得需要的扇区到达磁头下面。这就很浪费时间了。许多年前,IBM的一位杰出工程师想出了一个绝妙的办法,即对扇区不使用顺序编号,而是使用一个交叉因子(interleave)进行编号。 格式化的其他细节 每种操作系统能够使用的文件系统并不相同。举例来说,windows 98 以前的微 软操作系统主要利用的文件系统是 FAT (或 FAT16),windows 2000 以后的版本有所谓的 NTFS 文件系统,至于 Linux 的正统文件系统则为Ext2 (Linux second extended file system, ext2fs) 这一个。而且在默认的情况下,windows 操作系统是不会认识 Linux的Ext2的。传统的磁盘与文件系统的应用中,一个分区只能够被格式化成为一个文件系统,所以我们可以说 一个 文件系统 就是一个分区。但是由于新技术的利用,例如我们常听到的 LVM 与软件磁盘阵列(software raid), 这些技术可以将一个分区格式化为多个文件系统,也能够将多个分区合成一个文件系统,所以说,目前我们在格式化时已经不再说成针对分区来格式化了, 通常我们可以称呼一个可被挂载的数据为一个文件系统而不是一个分区。 inode/block 与文件大小的关系(有趣)
我们简单分析一下EXT2 的inode / block 与文件大小的关系。inode 要记录的资料非常多,但偏偏又只有128bytes , 而inode 记录一个block 号码要花掉4byte ,假设我一个文件有400MB 且每个block 为4K 时, 那么至少也要十万条block 号码的记录!inode 哪有这么多空间来存储?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。这是啥?我们将inode 的结构画一下好了。
上图最左边为inode本身(128 bytes),里面有12个直接指向block号码的对照,这12条记录就能够直接取得block号码啦!至于所谓的间接就是再拿一个block来当作记录block号码的记录区,如果文件太大时,就会使用间接的block来记录号码。如上图中间接只是拿一个block来记录额外的号码而已。同理,如果文件持续长大,那么就会利用所谓的双间接,第一个block仅再指出下一个记录号码的block在哪里,实际记录的在第二个block当中。依此类推,三间接就是利用第三层block来记录号码啦!
这样子inode 能够指定多少个block 呢?我们以较小的1K block 来说明好了,可以指定的情况如下:
12个直接指向: 12*1K=12K 由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示 间接: 256*1K=256K 每笔block号码的记录会花去4bytes,因此1K的大小能够记录256笔记录,因此一个间接可以记录的文件大小如上; 双间接: 2562561K=256 2 K 第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上; 三间接: 256256256*1K=256 3 K 第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上; 总额:将直接、间接、双间接、三间接加总,得到12 + 256 + 256256 + 256256*256 (K) = 16GB 此时我们知道当文件系统将block格式化为1K大小时,能够容纳的最大文件为16GB,比较一下文件系统限制表的结果可发现是一致的!但这个方法不能用在2K及4K block大小的计算中,因为大于2K的block将会受到Ext2文件系统本身的限制,所以计算的结果会不太符合 文件系统大小与磁盘读取性能
关于文件系统的使用效率,当你的一个文件系统规划的很大时,例如100GB这么大时,由于磁盘上的资料总是来来去去的,所以,整个文件系统上面的文件通常无法连续写在一起(block号码不连续),而是填入式的将资料填入没有被使用的block当中。如果文件写入的block真的分的很散,此时就会有所谓的文件资料离散的问题发生了。
如前所述,虽然我们的ext2 在inode 处已经将该文件所记录的block 号码都记上了, 所以资料可以一次性读取,但是如果文件真的太过离散,确实还是会发生读取效率低的问题。因为磁盘读取头还是得要在整个文件系统中来来去去的频繁读取!果真如此,那么可以将整个文件系统内的资料全部复制出来,将该文件系统重新格式化, 再将资料给他复制回去即可解决这个问题。
此外,如果文件系统真的太大了,那么当一个文件分别记录在这个文件系统的最前面与最后面的block 号码中, 此时会造成磁碟的机械手臂移动幅度过大(不是还会分块吗?),也会造成资料读取效能的低落。而且读取头在搜寻整个文件系统时, 也会花费比较多的时间去搜寻。因此分区的规划并不是越大越好, 而是真的要针对你的主机用途来进行规划才行。
Linux的一切皆文件
Linux 中的各种事物比如像文档、目录(Mac OS X 和 Windows 系统下称之为文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都是定义在文件系统空间下的字节流。
一切都可看作是文件,其最显著的好处是对于上面所列出的输入/输出资源,只需要相同的一套 Linux 工具、实用程序和 API。你可以使用同一套api(read, write)和工具(cat , 重定向, 管道)来处理unix中大多数的资源.
设计一个系统的终极目标往往就是要找到原子操作,一旦锁定了原子操作,设计工作就会变得简单而有序。“文件”作为一个抽象概念,其原子操作非常简单,只有读和写,这无疑是一个非常好的模型。通过这个模型,API的设计可以化繁为简,用户可以使用通用的方式去访问任何资源,自有相应的中间件做好对底层的适配。
现代操作系统为解决信息能独立于进程之外被长期存储引入了文件,文件作为进程创建信息的逻辑单元可被多个进程并发使用。在 UNIX 系统中,操作系统为磁盘上的文本与图像、鼠标与键盘等输入设备及网络交互等 I/O 操作设计了一组通用 API,使他们被处理时均可统一使用字节流方式。换言之,UNIX 系统中除进程之外的一切皆是文件,而 Linux 保持了这一特性。为了便于文件的管理,Linux 还引入了目录(有时亦被称为文件夹)这一概念。目录使文件可被分类管理,且目录的引入使 Linux 的文件系统形成一个层级结构的目录树。
您可能感兴趣的文章:
- Linux基础学习之文件查找find的常见用法
- Xshell实现Windows上传文件到Linux主机的方法
- Linux如何实现断点续传文件功能
- 主机和VMware中的Linux实现共享文件夹的图文教程
- Linux查找处理文件名后包含空格的文件(两种方法)
- Linux中利用grep命令如何检索文件内容详解
- 解决linux下openoffice word文件转PDF中文乱码的问题
- Linux下将源文件编译成目标文件的过程解析
相关推荐
-
解决linux下openoffice word文件转PDF中文乱码的问题
网上很多介绍是由于jdk中的没有字体导致乱码,而我遇到的是转换过程并未报错,但转换后的PDF中是乱码,尝试在jre/lib/fonts/中增加字体,还是不能解决问题,因此可以判断非jre字体问题,是linux系统字体问题. 用vim /etc/fonts/fonts.conf,可以看到系统字体文件在/usr/share/fonts,将windows系统字体文件连接到此目录下 ln -s /usr/local/fonts fonts 然后更新缓存:fc-cache 重启openoffice: /o
-
Linux基础学习之文件查找find的常见用法
前言 在linux的日常管理中,find的使用频率很高,熟练掌握对提高工作效率很有帮助. find的语法比较简单,常用参数的就那么几个,比如-name.-type.-ctime等.初学的同学直接看第二部分的例子,如需进一步了解参数说明,可以参考find的帮助文档. find语法如下: find(选项)(参数) 常用例子 根据文件名查找 列出当前目录以及子目录下的所有文件 find . 找到当前目录下名字为11.png的文件 find . -name "11.png" 找到当前目录下所有
-
Linux下将源文件编译成目标文件的过程解析
简介 请讲一下linux如何源文件逐步编译成可执行文件. 解答 首先先上图对编译的整个过程有个感性的认识,然后再逐步分析各个过程. 以hello.c 程序为例 # include <stdio.h> main{ printf("hello\n"); } 一个.c源程序需要经过预处理器生成.i文件,再经过编译器生成.s文件,再经过汇编器生成可重定位目标文件.o文件,再与其他.o文件经过链接器生成最终的可执行目标程序. 预处理阶段.主要是处理源文件中以"#"
-
Linux中利用grep命令如何检索文件内容详解
前言 Linux系统中搜索.查找文件中的内容,一般最常用的是grep命令,另外还有egrep命令,同时vi命令也支持文件内容检索.下面来一起看看Linux利用grep命令检索文件内容的详细介绍. 方法如下: 1.搜索某个文件里面是否包含字符串 命令格式:grep "被查找的字符串" filename1 例如: grep "0101034175" /data/transaction.20170118.log 2.在多个文件中检索某个字符串 命令格式: grep &qu
-

Linux如何实现断点续传文件功能
什么是断点续传? 在网络状况不好的情况下,对于文件的传输,我们希望能够支持可以每次传部分数据.断点续传其实正如字面意思,就是在下载的断开点继续开始传输,不用再从头开始.所以理解断点续传的核心后,发现其实和很简单,关键就在于对传输中断点的把握,我就自己的理解画了一个简单的示意图: Linux断点续传文件 在Linux系统上传与下载文件的时候,很容易断开,或者是大文件传输,如何在断开后继续传输不用重新开始,这里我们可以用到Linux的rsync 使用说明 文件断点下载 rsync -P --rsh=
-
Linux查找处理文件名后包含空格的文件(两种方法)
当Linux下文件名中出现空格这类特殊情况话,如何查找或确认那些文件名后有空格呢? 又怎么批量替换处理掉这些空格呢? 方法1: 输入文件名后使用Tab键,如果使用Tab键后面出现\ \ \这样的可见字符,那么该文件名包含空格.当然,这个方法弊端很大,例如,效率低下,不能批量查找,只有当你怀疑某个文件名后有空格,这个方法才比较凑效.另外,不能查找文件中间包含空格的文件名.如下测试所示: [root@DB-Server kerry]# cat >"test.txt " it is o
-
主机和VMware中的Linux实现共享文件夹的图文教程
当我在网上查了几小时的挂载文件夹方法后发现,VMware中的Linux的挂载和双系统的挂载不同 最终目的就是在/mnt目录下有个hgfs的文件夹 效果图: 首先打开VMware中的Linux系统 具体步骤如下: 然后 这时候虚拟机的光驱会自动加载VWware安装目录下的linux.iso镜像,Linux系统也会自动挂载VMware Tools的虚拟光驱,并显示在桌面 然后 然后 然后进入存放vmware安装包的目录 然后拷贝到你想放的地方 然后解压 然后进入解压后的vmware-tools-di
-
Xshell实现Windows上传文件到Linux主机的方法
写在前面,博主本身并没有开始做接口自动化测试,目前刚刚学完postman的教程,了解工具,现在脑海中基本上的框架是已经有了,因为我们知道postman的collection是可以命令行执行(nodejs+newman)的,那么就为我们做Jenkins持续集成提供了良好的基础,之前博主让开发分配了一个linux虚拟机,可以用来跑接口测试脚本,想来会比我的另一台win7性能要好,因为是centos,搞linux的对gui并不感冒,那么涉及到一个问题,我windows下面的collection jso
-
详细分析Linux文件系统
本片文章针对Linux文件系统从原理到运行机制做了非常详细的理论分析,有助于读者对此深入的理解,以下是具体内容: Linux上的文件系统一般来说就是EXT2或EXT3,但这篇文章并不准备一上来就直接讲它们,而希望结合Linux操作系统并从文件系统建立的基础--硬盘开始,一步步认识Linux的文件系统. 1.机械硬盘的物理存储机制 现代计算机大部分文件存储功能都是由机械硬盘这种设备提供的.(现在的SSD和闪存从概念和逻辑上都部分继承自机械硬盘,所以使用机械硬盘来进行理解也是没有问题的) 机械硬盘能
-
Linux文件系统的桌面应用
本文中要介绍一个所谓的"Linux 文件系统的守护神",这是指一个能实时地观察 Linux 文件系统的变化情况的程序模块.能够实时的观察文件系统的变化情况,并做出及时的适当的反应,这对于应用 Linux 做桌面计算机系统来说,是十分的有趣,也是十分的重要的.本文还要介绍 Linux 文件系统的异步 I/O 的扩展.同样,这对于 Linux 系统的桌面应用也是关键的. 1.Linux 文件系统的守护神 传统的 Linux 文件系统呈现给用户程序的界面,确实是十分的干净利落.用户程序可以打
-
查看linux文件系统块大小的实现方法
在linux系统上,可以用命令tune2fs ,测试如下 [root@localhost test10g]# tune2fs -help tune2fs 1.35 (28-Feb-2004) tune2fs: invalid option -- h Usage: tune2fs [-c max-mounts-count] [-e errors-behavior] [-g group] [-i interval[d|m|w]] [-j] [-J journal-options] [-l] [-s
-
详细解读linux下swap分区的作用
本文研究的主要是linux下swap分区的相关内容,具体介绍如下. swap分区介绍 嵌入式Linux中文站消息,Linux系统的Swap分区,即交换区,Swap空间的作用可简单描述为:当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用.那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap空间中,等到那些程序要运行时,再从Swap中恢复保存的数据到内存中.这样,系统总是在物理内存不够时,才进行Swap交换.其实,S
-
详细分析c# 客户端内存优化
背景概述 C# 开发客户端系统的时候,.net 框架本身就比较消耗内存资源,特别是xp 这种老爷机内存配置不是很高的电脑上运行,所以就需要进行内存上的优化,才能流畅的在哪些低端电脑上运行. 想要对C# 开发的客户端内存优化需要了解以下几个概念. 虚拟内存 这里引用百度百科的概念:虚拟内存是计算机系统内存管理的一种技术.它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换.目前,大多
-
详细分析C++ 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序.在 UNIX.LINUX.Mac OS X 或 Windows 系统上,可以通过按 Ctrl+C 产生中断. 有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作.这些信号是定义在 C++ 头文件 <csignal> 中. 信号 描述 SIGABRT 程序的异常终止,如调用 abort. SIGFPE 错误的算术运算,比如除以零或导致溢出的操作. SIGILL 检测非法指令. SIGINT 程序终止(inte
-
详细分析Node.js 模块系统
为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统. 模块是Node.js 应用程序的基本组成部分,文件和模块是一一对应的.换言之,一个 Node.js 文件就是一个模块,这个文件可能是JavaScript 代码.JSON 或者编译过的C/C++ 扩展. 创建模块 在 Node.js 中,创建一个模块非常简单,如下我们创建一个 main.js 文件,代码如下: var hello = require('./hello'); hello.world(); 以上实例中,代
-
分析Linux内核调度器源码之初始化
一.导语 调度器(Scheduler)子系统是内核的核心子系统之一,负责系统内 CPU 资源的合理分配,需要能处理纷繁复杂的不同类型任务的调度需求,还需要能处理各种复杂的并发竞争环境,同时还需要兼顾整体吞吐性能和实时性要求(本身是一对矛盾体),其设计与实现都极具挑战. 为了能够理解 Linux 调度器的设计与实现,我们将以 Linux kernel 5.4 版本(TencentOS Server3 默认内核版本)为对象,从调度器子系统的初始化代码开始,分析 Linux 内核调度器的设计与实现.
-
超详细讲解Linux C++多线程同步的方式
目录 一.互斥锁 1.互斥锁的初始化 2.互斥锁的相关属性及分类 3,测试加锁函数 二.条件变量 1.条件变量的相关函数 1)初始化的销毁读写锁 2)以写的方式获取锁,以读的方式获取锁,释放读写锁 四.信号量 1)信号量初始化 2)信号量值的加减 3)对信号量进行清理 背景问题:在特定的应用场景下,多线程不进行同步会造成什么问题? 通过多线程模拟多窗口售票为例: #include <iostream> #include<pthread.h> #include<stdio.h&
-
C++详细分析线程间的同步通信
目录 1.多线程编程两个问题 1.1.线程间的互斥 1.2.线程间的同步通信 2.生产者-消费者线程模型 3.lock_gard和unique_lock 4.流程分析 1.多线程编程两个问题 1.1.线程间的互斥 竞态条件: 多线程执行的结果是一致的,不会随着CPU对线程不同的调用顺序,而产生不同的运行结果. 发生竞态条件的代码段,称为临界区代码段(只有一个线程可以进来),保证临界区代码段原子操作,通过线程互斥锁mutex,也可以使用轻量级的无锁实现CAS. C++11的mutex底层实现: 使