Python数据分析库pandas基本操作方法
pandas是什么?

是它吗?
。。。。很显然pandas没有这个家伙那么可爱。。。。
我们来看看pandas的官网是怎么来定义自己的:
pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language.
很显然,pandas是python的一个非常强大的数据分析库!
让我们来学习一下它吧!
1.pandas序列
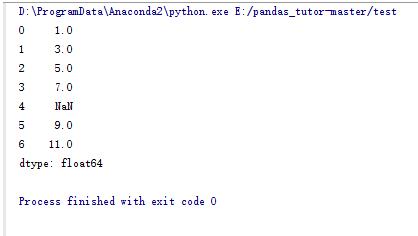
import numpy as np import pandas as pd s_data = pd.Series([1,3,5,7,np.NaN,9,11])#pandas中生产序列的函数,类似于我们平时说的数组 print s_data
2.pandas数据结构DataFrame
import numpy as np
import pandas as pd
#以20170220为基点向后生产时间点
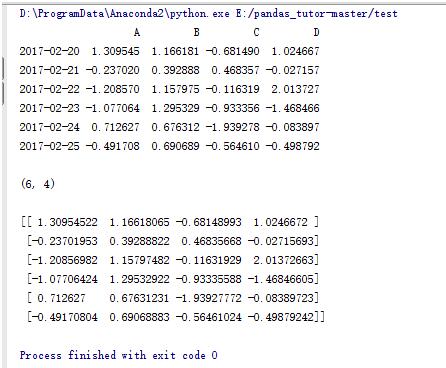
dates = pd.date_range('20170220',periods=6)
#DataFrame生成函数,行索引为时间点,列索引为ABCD
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
print data.shape
print
print data.values
3.DataFrame的一些操作(1)
import numpy as np
import pandas as pd
#设计一个字典
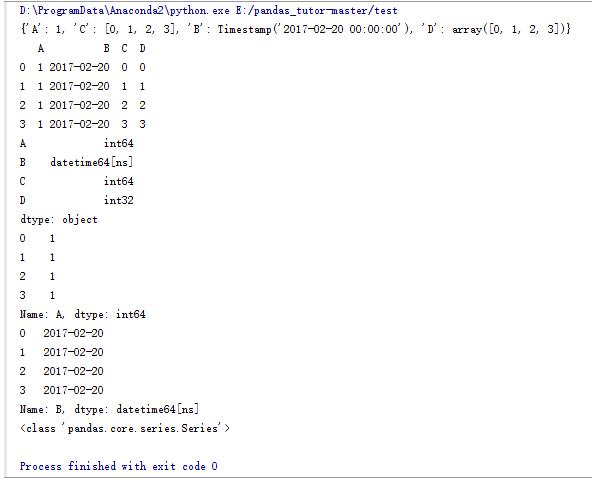
d_data = {'A':1,'B':pd.Timestamp('20170220'),'C':range(4),'D':np.arange(4)}
print d_data
#使用字典生成一个DataFrame
df_data = pd.DataFrame(d_data)
print df_data
#DataFrame中每一列的类型
print df_data.dtypes
#打印A列
print df_data.A
#打印B列
print df_data.B
#B列的类型
print type(df_data.B)
4.DataFrame的一些操作(2)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
#输出DataFrame头部数据,默认为前5行
print data.head()
#输出输出DataFrame第一行数据
print data.head(1)
#输出DataFrame尾部数据,默认为后5行
print data.tail()
#输出输出DataFrame最后一行数据
print data.tail(1)
#输出行索引
print data.index
#输出列索引
print data.columns
#输出DataFrame数据值
print data.values
#输出DataFrame详细信息
print data.describe()
5.DataFrame的一些操作(3)
import numpy as np
import pandas as pd
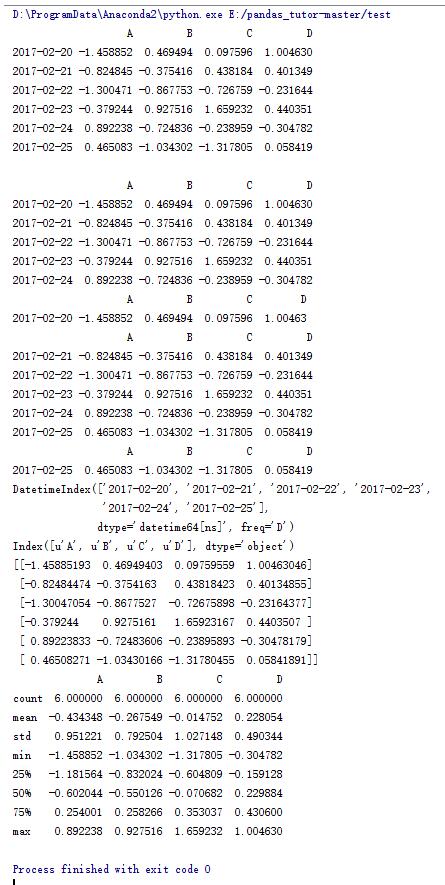
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
#转置
print data.T
#输出维度信息
print data.shape
#转置后的维度信息
print data.T.shape
#将列索引排序
print data.sort_index(axis = 1)
#将列索引排序,降序排列
print data.sort_index(axis = 1,ascending=False)
#将行索引排序,降序排列
print data.sort_index(axis = 0,ascending=False)
#按照A列的值进行升序排列
print data.sort_values(by='A')

6.DataFrame的一些操作(4)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#输出A列
print data.A
#输出A列
print data['A']
#输出3,4行
print data[2:4]
#输出3,4行
print data['20170222':'20170223']
#输出3,4行
print data.loc['20170222':'20170223']
#输出3,4行
print data.iloc[2:4]
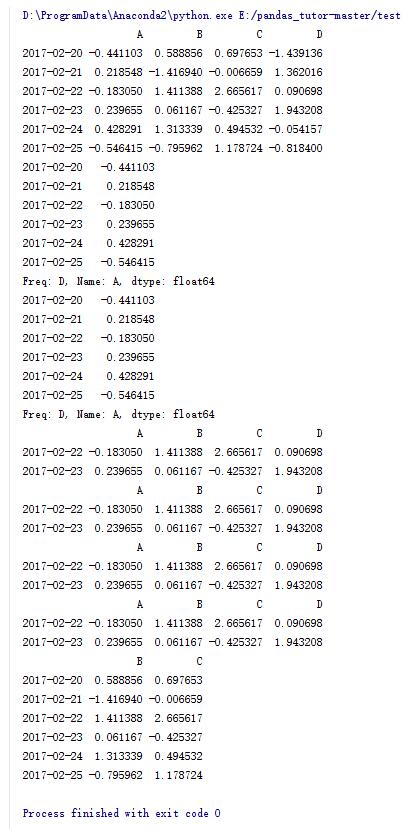
输出B,C两列
print data.loc[:,['B','C']]
7.DataFrame的一些操作(5)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#输出A列中大于0的行
print data[data.A > 0]
#输出大于0的数据,小于等于0的用NaN补位
print data[data > 0]
#拷贝data
data2 = data.copy()
print data2
tag = ['a'] * 2 + ['b'] * 2 + ['c'] * 2
#在data2中增加TAG列用tag赋值
data2['TAG'] = tag
print data2
#打印TAG列中为a,c的行
print data2[data2.TAG.isin(['a','c'])]

8.DataFrame的一些操作(6)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#将第一行第一列元素赋值为100
data.iat[0,0] = 100
print data
#将A列元素用range(6)赋值
data.A = range(6)
print data
#将B列元素赋值为200
data.B = 200
print data
#将3,4列元素赋值为1000
data.iloc[:,2:5] = 1000
print data

9.DataFrame的一些操作(7)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
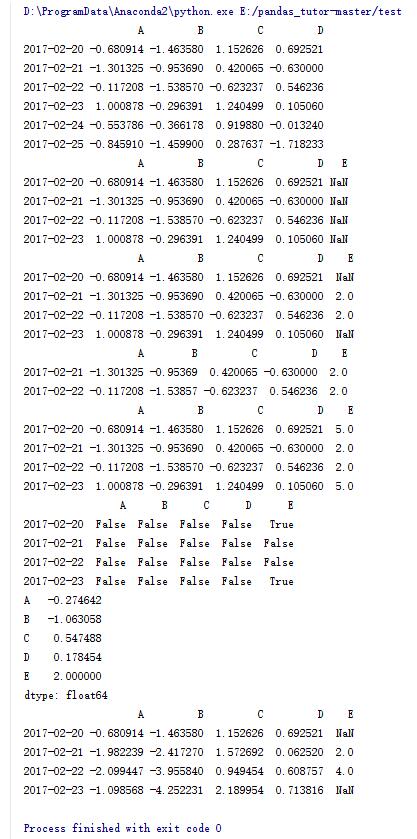
#重定义索引,并添加E列
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#将E列中的2,3行赋值为2
dfl.loc[dates[1:3],'E'] = 2
print dfl
#去掉存在NaN元素的行
print dfl.dropna()
#将NaN元素赋值为5
print dfl.fillna(5)
#判断每个元素是否为NaN
print pd.isnull(dfl)
#求列平均值
print dfl.mean()
#对每列进行累加
print dfl.cumsum()
10.DataFrame的一些操作(8)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
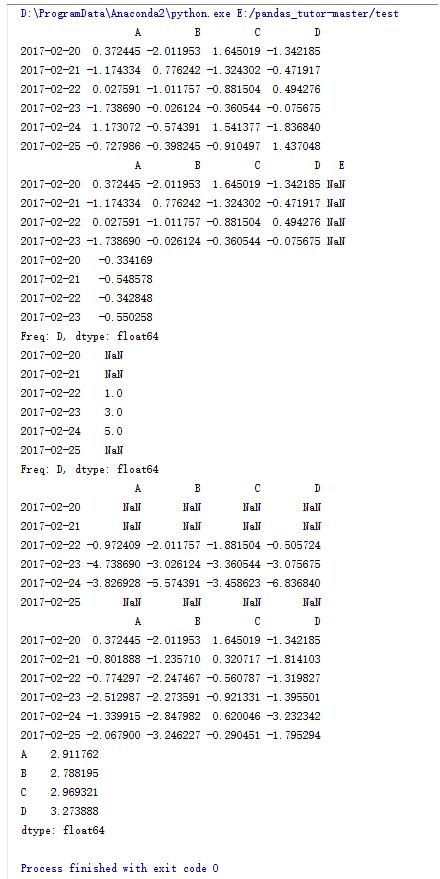
#针对行求平均值
print dfl.mean(axis=1)
#生成序列并向右平移两位
s = pd.Series([1,3,5,np.nan,6,8],index = dates).shift(2)
print s
#df与s做减法运算
print df.sub(s,axis = 'index')
#每列进行累加运算
print df.apply(np.cumsum)
#每列的最大值减去最小值
print df.apply(lambda x: x.max() - x.min())
11.DataFrame的一些操作(9)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#定义一个函数
def _sum(x):
print(type(x))
return x.sum()
#apply函数可以接受一个函数作为参数
print df.apply(_sum)
s = pd.Series(np.random.randint(10,20,size = 15))
print s
#统计序列中每个元素出现的次数
print s.value_counts()
#返回出现次数最多的元素
print s.mode()

12.DataFrame的一些操作(10)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
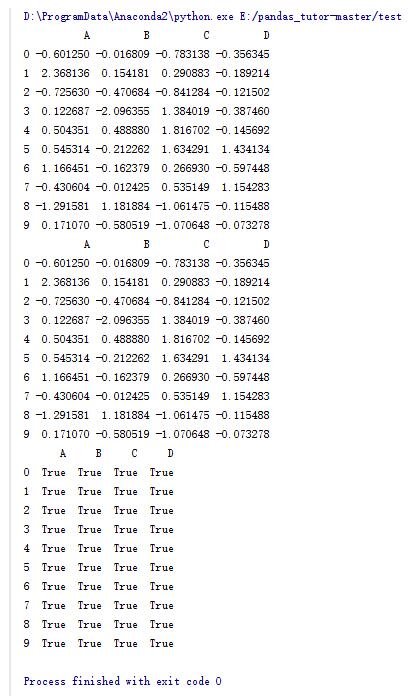
#合并函数
dfl = pd.concat([df.iloc[:3],df.iloc[3:7],df.iloc[7:]])
print dfl
#判断两个DataFrame中元素是否相等
print df == dfl
13.DataFrame的一些操作(11)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
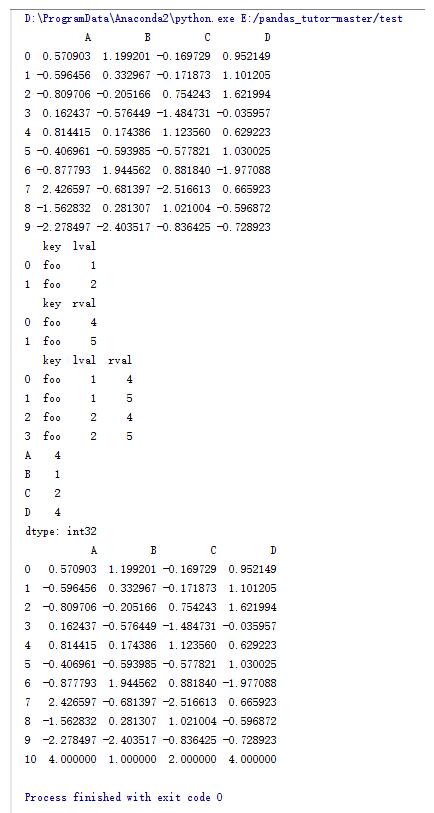
print df
left = pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})
right = pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})
print left
print right
#通过key来合并数据
print pd.merge(left,right,on='key')
s = pd.Series(np.random.randint(1,5,size = 4),index = list('ABCD'))
print s
#通过序列添加一行
print df.append(s,ignore_index = True)
14.DataFrame的一些操作(12)
import numpy as np
import pandas as pd
df = pd.DataFrame({'A': ['foo','bar','foo','bar',
'foo','bar','foo','bar'],
'B': ['one','one','two','three',
'two','two','one','three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
print df
print
#根据A列的索引求和
print df.groupby('A').sum()
print
#先根据A列的索引,在根据B列的索引求和
print df.groupby(['A','B']).sum()
print
#先根据B列的索引,在根据A列的索引求和
print df.groupby(['B','A']).sum()

15.DataFrame的一些操作(13)
import pandas as pd
import numpy as np
#zip函数可以打包成一个个tuple
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
print tuples
#生成一个多层索引
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
print index
print
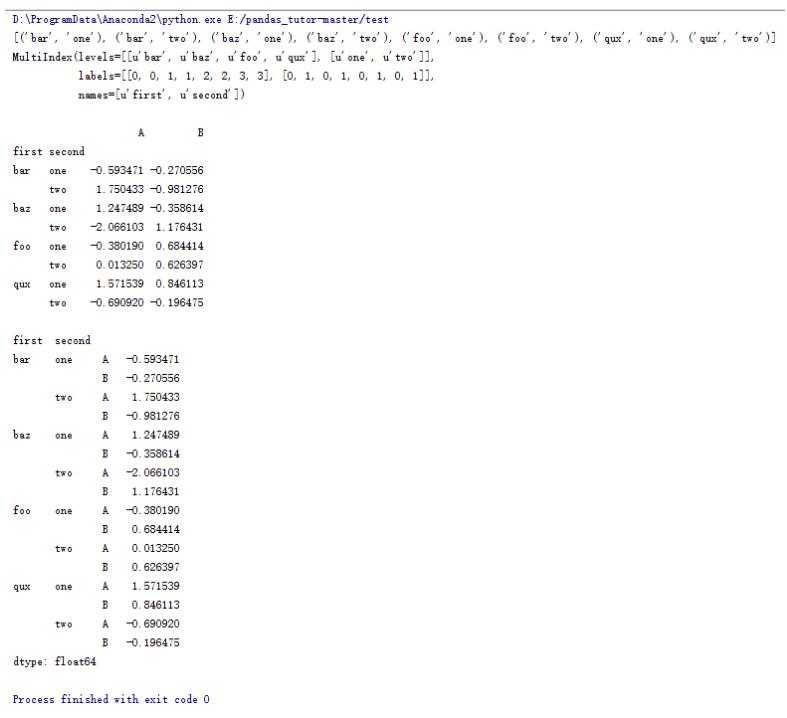
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
print
#将列索引变成行索引
print df.stack()
16.DataFrame的一些操作(14)
import pandas as pd
import numpy as np
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
print
stacked = df.stack()
print stacked
#将行索引转换为列索引
print stacked.unstack()
#转换两次
print stacked.unstack().unstack()

17.DataFrame的一些操作(15)
import pandas as pd
import numpy as np
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
print df
#根据A,B索引为行,C的索引为列处理D的值
print pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
#感觉A列等于one为索引,根据C列组合的平均值
print df[df.A=='one'].groupby('C').mean()

18.时间序列(1)
import pandas as pd
import numpy as np
#创建一个以20170220为基准的以秒为单位的向前推进600个的时间序列
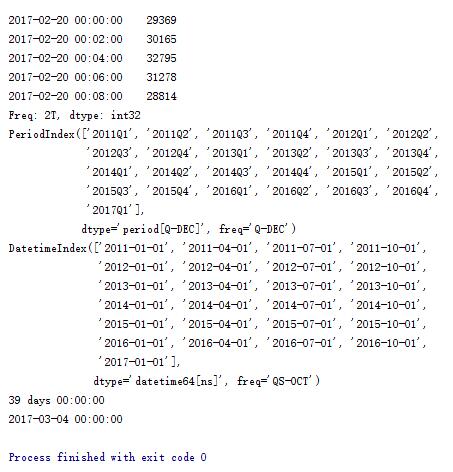
rng = pd.date_range('20170220', periods=600, freq='s')
print rng
#以时间序列为索引的序列
print pd.Series(np.random.randint(0, 500, len(rng)), index=rng)

19.时间序列(2)
import pandas as pd
import numpy as np
rng = pd.date_range('20170220', periods=600, freq='s')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
#重采样,以2分钟为单位进行加和采样
print ts.resample('2Min', how='sum')
#列出2011年1季度到2017年1季度
rng1 = pd.period_range('2011Q1','2017Q1',freq='Q')
print rng1
#转换成时间戳形式
print rng1.to_timestamp()
#时间加减法
print pd.Timestamp('20170220') - pd.Timestamp('20170112')
print pd.Timestamp('20170220') + pd.Timedelta(days=12)
20.数据类别
import pandas as pd
import numpy as np
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
print df
#添加类别数据,以raw_grade的值为类别基础
df["grade"] = df["raw_grade"].astype("category")
print df
#打印类别
print df["grade"].cat.categories
#更改类别
df["grade"].cat.categories = ["very good", "good", "very bad"]
print df
#根据grade的值排序
print df.sort_values(by='grade', ascending=True)
#根据grade排序显示数量
print df.groupby("grade").size()

21.数据可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
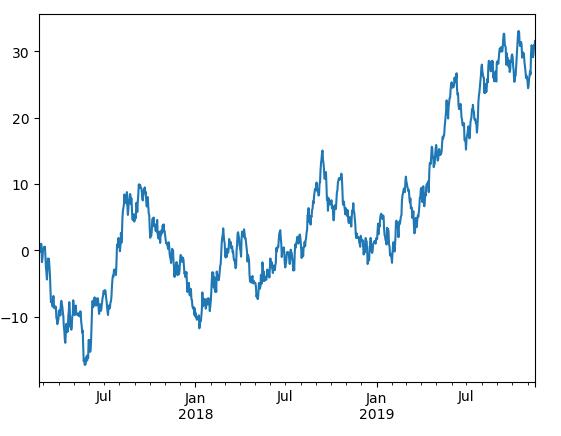
ts = pd.Series(np.random.randn(1000), index=pd.date_range('20170220', periods=1000))
ts = ts.cumsum()
print ts
ts.plot()
plt.show()
22.数据读写
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD'))
#数据保存,相对路径
df.to_csv('data.csv')
#数据读取
print pd.read_csv('data.csv', index_col=0)
数据被保存到这个文件中:

打开看看:
以上这篇Python数据分析库pandas基本操作方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法.分享给大家供大家参考,具体如下: 1.DataFrame的创建 (1)通过二维数组方式创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu import numpy as np import pandas as pd from pandas import Series,DataFrame #1.DataFrame通过二维数组创建 pr
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-

Windows下Python使用Pandas模块操作Excel文件的教程
安装Python环境 ANACONDA是一个Python的发行版本,包含了400多个Python最常用的库,其中就包括了数据分析中需要经常使用到的Numpy和Pandas等.更重要的是,不论在哪个平台上,都可以一键安装,自动配置好环境,不需要用户任何的额外操作,非常方便.因此,安装Python环境就只需要到ANACONDA网站上下载安装文件,双击安装即可. ANACONDA官方下载地址:https://www.continuum.io/downloads 安装完成之后,使用windows + r
-
Python数据分析之真实IP请求Pandas详解
前言 pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的 .Series 和 DataFrame 分别对应于一维的序列和二维的表结构.pandas 约定俗成的导入方法如下: from pandas import Series,DataFrame import pandas as pd 1.1. Pandas分析步骤 1.载入日志数据 2.载
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
浅析Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧. #!/usr/bin/python # -*- coding: UTF-8 -*- import numpy as np import pandas as pd import MySQLdb df = pd.read_csv('C:\\Users\\Administrato
-
Python数据分析模块pandas用法详解
本文实例讲述了Python数据分析模块pandas用法.分享给大家供大家参考,具体如下: 一 介绍 pandas(Python Data Analysis Library)是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一. pandas主要提供了3种数据结构: 1)Series,带标签的一维数组. 2)DataFrame,带标签且大小可变的二维表格结构. 3)Panel,带标
-
Python中pandas模块DataFrame创建方法示例
本文实例讲述了Python中pandas模块DataFrame创建方法.分享给大家供大家参考,具体如下: DataFrame创建 1. 通过列表创建DataFrame 2. 通过字典创建DataFrame 3. 通过Numpy数组创建DataFrame DataFrame这种列表式的数据结构和Excel工作表非常类似,其设计初衷是讲Series的使用场景由一维扩展到多维. DataFrame由按一定顺序的多列数据组成,各列的数据类型可以有所不同(数值.字符串.布尔值). Series对象的Ind
-
Python3.5 Pandas模块之Series用法实例分析
本文实例讲述了Python3.5 Pandas模块之Series用法.分享给大家供大家参考,具体如下: 1.Pandas模块引入与基本数据结构 2.Series的创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #模块引入 import numpy as np import pandas as pd from pandas import Series,DataFrame #1.Series通过numpy一
-
python pandas模块基础学习详解
Pandas类似R语言中的数据框(DataFrame),Pandas基于Numpy,但是对于数据框结构的处理比Numpy要来的容易. 1. Pandas的基本数据结构和使用 Pandas有两个主要的数据结构:Series和DataFrame.Series类似Numpy中的一维数组,DataFrame则是使用较多的多维表格数据结构. Series的创建 >>>import numpy as np >>>import pandas as pd >>>s=p
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python数据分析之如何利用pandas查询数据示例代码
前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例代码 这里的查询数据相当于R语言里的subset功能,可以通过布尔索引有针对的选取原数据的子集.指定行.指定列等.我们先导入一个student数据集: student = pd.io.parsers.read_csv('C:\\Users\\admin\\Desktop\\student.csv')