python机器学习库scikit-learn:SVR的基本应用
scikit-learn是python的第三方机器学习库,里面集成了大量机器学习的常用方法。例如:贝叶斯,svm,knn等。
scikit-learn的官网 : http://scikit-learn.org/stable/index.html点击打开链接
SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支。
scikit-learn中提供了基于libsvm的SVR解决方案。
PS:libsvm是台湾大学林智仁教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包。
我们自己随机产生一些值,然后使用sin函数进行映射,使用SVR对数据进行拟合
from __future__ import division
import time
import numpy as np
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
rng = np.random.RandomState(0)
#############################################################################
# 生成随机数据
X = 5 * rng.rand(10000, 1)
y = np.sin(X).ravel()
# 在标签中对每50个结果标签添加噪声
y[::50] += 2 * (0.5 - rng.rand(int(X.shape[0]/50)))
X_plot = np.linspace(0, 5, 100000)[:, None]
#############################################################################
# 训练SVR模型
#训练规模
train_size = 100
#初始化SVR
svr = GridSearchCV(SVR(kernel='rbf', gamma=0.1), cv=5,
param_grid={"C": [1e0, 1e1, 1e2, 1e3],
"gamma": np.logspace(-2, 2, 5)})
#记录训练时间
t0 = time.time()
#训练
svr.fit(X[:train_size], y[:train_size])
svr_fit = time.time() - t0
t0 = time.time()
#测试
y_svr = svr.predict(X_plot)
svr_predict = time.time() - t0
然后我们对结果进行可视化处理
#############################################################################
# 对结果进行显示
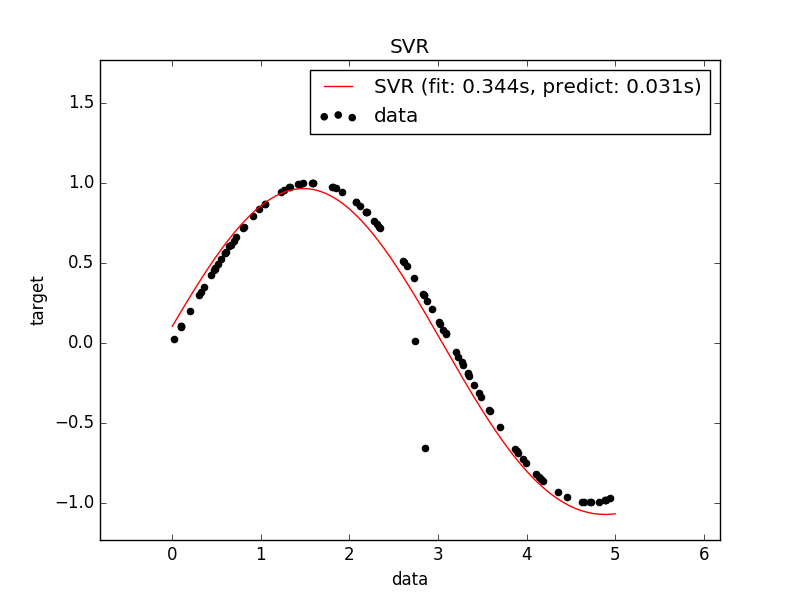
plt.scatter(X[:100], y[:100], c='k', label='data', zorder=1)
plt.hold('on')
plt.plot(X_plot, y_svr, c='r',
label='SVR (fit: %.3fs, predict: %.3fs)' % (svr_fit, svr_predict))
plt.xlabel('data')
plt.ylabel('target')
plt.title('SVR versus Kernel Ridge')
plt.legend()
plt.figure()
##############################################################################
# 对训练和测试的过程耗时进行可视化
X = 5 * rng.rand(1000000, 1)
y = np.sin(X).ravel()
y[::50] += 2 * (0.5 - rng.rand(int(X.shape[0]/50)))
sizes = np.logspace(1, 4, 7)
for name, estimator in {
"SVR": SVR(kernel='rbf', C=1e1, gamma=10)}.items():
train_time = []
test_time = []
for train_test_size in sizes:
t0 = time.time()
estimator.fit(X[:int(train_test_size)], y[:int(train_test_size)])
train_time.append(time.time() - t0)
t0 = time.time()
estimator.predict(X_plot[:1000])
test_time.append(time.time() - t0)
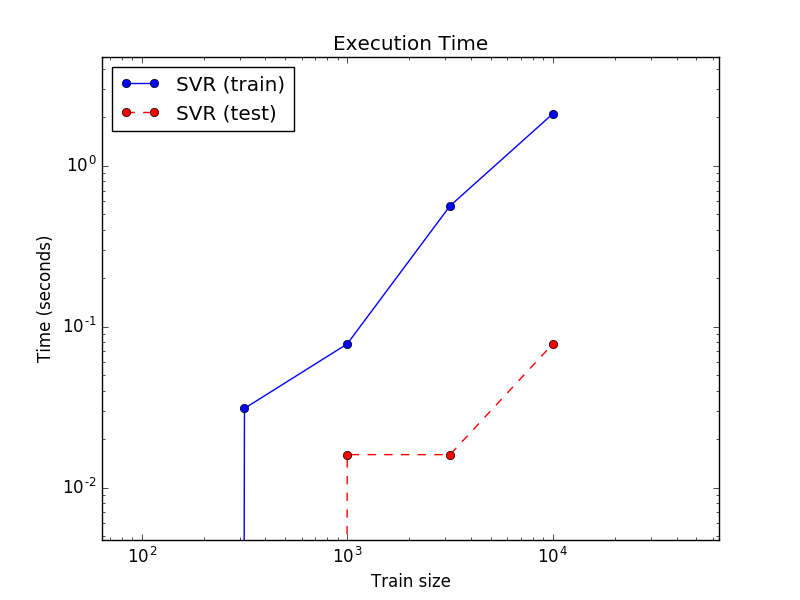
plt.plot(sizes, train_time, 'o-', color="b" if name == "SVR" else "g",
label="%s (train)" % name)
plt.plot(sizes, test_time, 'o--', color="r" if name == "SVR" else "g",
label="%s (test)" % name)
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Train size")
plt.ylabel("Time (seconds)")
plt.title('Execution Time')
plt.legend(loc="best")
################################################################################
# 对学习过程进行可视化
plt.figure()
svr = SVR(kernel='rbf', C=1e1, gamma=0.1)
train_sizes, train_scores_svr, test_scores_svr = \
learning_curve(svr, X[:100], y[:100], train_sizes=np.linspace(0.1, 1, 10),
scoring="neg_mean_squared_error", cv=10)
plt.plot(train_sizes, -test_scores_svr.mean(1), 'o-', color="r",
label="SVR")
plt.xlabel("Train size")
plt.ylabel("Mean Squared Error")
plt.title('Learning curves')
plt.legend(loc="best")
plt.show()

看见了熟悉的LOSS下降图,我仿佛又回到了学生时代。。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python机器学习之scikit-learn库中KNN算法的封装与使用方法
本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法.分享给大家供大家参考,具体如下: 1.工具准备,python环境,pycharm 2.在机器学习中,KNN是不需要训练过程的算法,也就是说,输入样例可以直接调用predict预测结果,训练数据集就是模型.当然这里必须将训练数据和训练标签进行拟合才能形成模型. 3.在pycharm中创建新的项目工程,并在项目下新建KNN.py文件. import numpy as np from math import s
-
Python scikit-learn 做线性回归的示例代码
一.概述 机器学习算法在近几年大数据点燃的热火熏陶下已经变得被人所"熟知",就算不懂得其中各算法理论,叫你喊上一两个著名算法的名字,你也能昂首挺胸脱口而出.当然了,算法之林虽大,但能者还是有限,能适应某些环境并取得较好效果的算法会脱颖而出,而表现平平者则被历史所淡忘.随着机器学习社区的发展和实践验证,这群脱颖而出者也逐渐被人所认可和青睐,同时获得了更多社区力量的支持.改进和推广. 以最广泛的分类算法为例,大致可以分为线性和非线性两大派别.线性算法有著名的逻辑回归.朴素贝叶斯.最大熵等,
-
python中scikit-learn机器代码实例
我们给大家带来了关于学习python中scikit-learn机器代码的相关具体实例,以下就是全部代码内容: # -*- coding: utf-8 -*- import numpy from sklearn import metrics from sklearn.svm import LinearSVC from sklearn.naive_bayes import MultinomialNB from sklearn import linear_model from sklearn.data
-
基于Python和Scikit-Learn的机器学习探索
你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎.我同时在为一家俄罗斯移动运营商开发大数据产品.这是我第一次在网上写文章,不喜勿喷. 现在,很多人想开发高效的算法以及参加机器学习的竞赛.所以他们过来问我:"该如何开始?".一段时间以前,我在一个俄罗斯联邦政府的下属机构中领导了媒体和社交网络大数据分析工具的开发.我仍然有一些我团队使用过的文档,我乐意与你们分享.前提是读者已经有很好的数学和机器学习方面的知识(我的团队主要由MIPT(莫斯科物理与技术大学)和
-
Python机器学习库scikit-learn安装与基本使用教程
本文实例讲述了Python机器学习库scikit-learn安装与基本使用.分享给大家供大家参考,具体如下: 引言 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口,可以让用户简单.高效地进行数据挖掘和数据分析. scikit-learn安装 python 中安装许多模板库之前都有依赖关系,安装 scikit-learn 之前需要以下先决条件: Python(>= 2.6 or >= 3
-
python的scikit-learn将特征转成one-hot特征的方法
如下所示: enc = OneHotEncoder(categorical_features=np.array([0,1,2]),n_values=[5,4,2]) enc.fit(train_data) train_data = enc.transform(train_data).toarray() test_data = enc.transform(test_data).toarray() 以上这篇python的scikit-learn将特征转成one-hot特征的方法就是小编分享给大家的全
-
python机器学习库scikit-learn:SVR的基本应用
scikit-learn是python的第三方机器学习库,里面集成了大量机器学习的常用方法.例如:贝叶斯,svm,knn等. scikit-learn的官网 : http://scikit-learn.org/stable/index.html点击打开链接 SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支. scikit-learn中提供了基于libsvm的SVR解决方案. PS:libsvm是台湾大学林智仁教授等开发设
-
python机器学习库常用汇总
汇总整理一套Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘的兵器谱. 1. Python网页爬虫工具集 一个真实的项目,一定是从获取数据开始的.无论文本处理,机器学习和数据挖掘,都需要数据,除了通过一些渠道购买或者下载的专业数据外,常常需要大家自己动手爬数据,这个时候,爬虫就显得格外重要了,幸好,Python提供了一批很不错的网页爬虫工具框架,既能爬取数据,也能获取和清洗数据,也就从这里开始了: 1.1 Scrapy 鼎鼎大名的Scrapy,相信不少同学都有耳闻,课程图谱中的很多课
-
Python 机器学习库 NumPy入门教程
NumPy是一个Python语言的软件包,它非常适合于科学计算.在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础库. 本文是对它的一个入门教程. 介绍 NumPy是一个用于科技计算的基础软件包,它是Python语言实现的.它包含了: 强大的N维数组结构 精密复杂的函数 可集成到C/C++和Fortran代码的工具 线性代数,傅里叶变换以及随机数能力 除了科学计算的用途以外,NumPy也可被用作高效的通用数据的多维容器.由于它适用于任意类型的数据,这使得NumPy可以无缝和
-
Python机器学习库scikit-learn入门开发示例
目录 1.数据采集和标记 2.特征选择 3.数据清洗 4.模型选择 5.模型训练 6.模型测试 7.模型保存与加载 8.实例 数据采集和标记 特征选择 模型训练 模型测试 模型保存与加载 1.数据采集和标记 先采集数据,再对数据进行标记.其中采集数据要就有代表性,以确保最终训练出来模型的准确性. 2.特征选择 选择特征的直观方法:直接使用图片的每个像素点作为一个特征. 数据保存为样本个数×特征个数格式的array对象.scikit-learn使用Numpy的array对象来表示数据,所有的图片数
-
python 机器学习之支持向量机非线性回归SVR模型
本文介绍了python 支持向量机非线性回归SVR模型,废话不多说,具体如下: import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm from sklearn.model_selection import train_test_split def load_data_regression(): ''' 加载用于回归问题的数据集 ''' diabetes =
-
python机器学习库xgboost的使用
1.数据读取 利用原生xgboost库读取libsvm数据 import xgboost as xgb data = xgb.DMatrix(libsvm文件) 使用sklearn读取libsvm数据 from sklearn.datasets import load_svmlight_file X_train,y_train = load_svmlight_file(libsvm文件) 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库
-
Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python 数据处理库 pandas进阶教程
前言 本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识.建议读者在阅读本文之前先看完pandas入门教程. 同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial. 数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. 基础方法:[]和. 这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解.下面是一个代码示例: # select_da
-
Python常用库大全及简要说明
环境管理 管理 Python 版本和环境的工具 p:非常简单的交互式 python 版本管理工具.官网 pyenv:简单的 Python 版本管理工具.官网 Vex:可以在虚拟环境中执行命令.官网 virtualenv:创建独立 Python 环境的工具.官网 virtualenvwrapper:virtualenv 的一组扩展.官网 buildout:在隔离环境初始化后使用声明性配置管理.官网 包管理 管理包和依赖的工具. pip:Python 包和依赖关系管理工具.官网 pip-tools: