pandas DataFrame 交集并集补集的实现
1.场景,对于colums都相同的dataframe做过滤的时候
例如:
df1 = DataFrame([['a', 10, '男'],
['b', 11, '男'],
['c', 11, '女'],
['a', 10, '女'],
['c', 11, '男']],
columns=['name', 'age', 'sex'])
df2 = DataFrame([['a', 10, '男'],
['b', 11, '女']],
columns=['name', 'age', 'sex'])
取交集:print(pd.merge(df1,df2,on=['name', 'age', 'sex']))
取并集:print(pd.merge(df1,df2,on=['name', 'age', 'sex'], how='outer'))
取差集(从df1中过滤df1在df2中存在的行):
df1 = df1.append(df2) df1 = df1.append(df2) df1 = df1.drop_duplicates(subset=['name', 'age', 'sex'],keep=False) print(df1)
代码:
# -*- coding:utf-8 -*-
__version__ = '1.0.0.0'
"""
@brief : 简介
@details: 详细信息
@author : zhphuang
@date : 2018-10-29
"""
import pandas as pd
from pandas import *
df1 = DataFrame([['a', 10, '男'],
['b', 11, '男'],
['c', 11, '女'],
['a', 10, '女'],
['c', 11, '男']],
columns=['name', 'age', 'sex'])
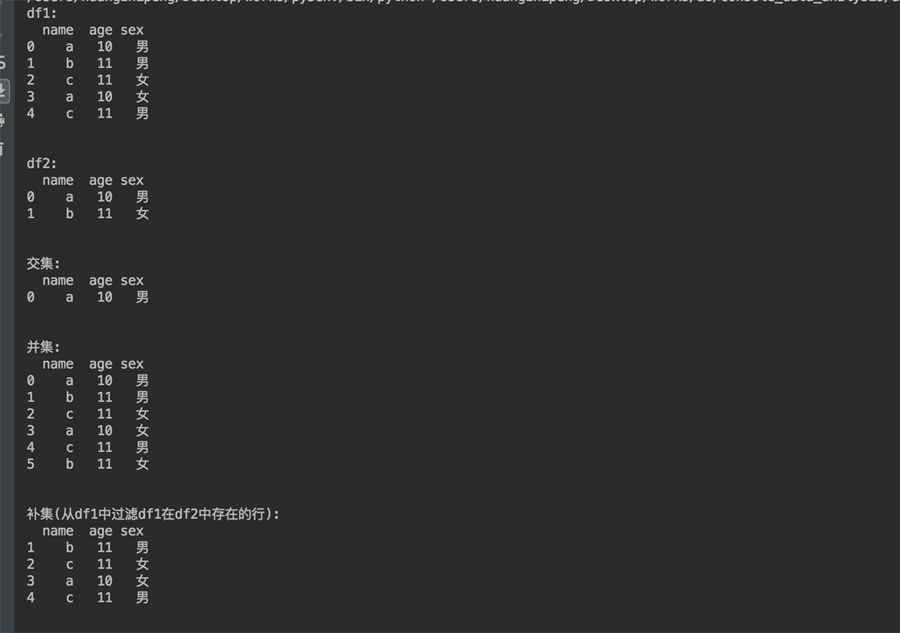
print("df1:\n%s\n\n" % df1)
df2 = DataFrame([['a', 10, '男'],
['b', 11, '女']],
columns=['name', 'age', 'sex'])
print("df2:\n%s\n\n" % df2)
# 取交集
print("交集:\n%s\n\n" % pd.merge(df1,df2,on=['name', 'age', 'sex']))
# 取并集
print("并集:\n%s\n\n" % pd.merge(df1,df2,on=['name', 'age', 'sex'], how='outer'))
# 从df1中过滤df1在df2中存在的行,也就是取补集
df1 = df1.append(df2)
df1 = df1.append(df2)
print("补集(从df1中过滤df1在df2中存在的行):\n%s\n\n" % df1.drop_duplicates(subset=['name', 'age', 'sex'],keep=False))
截图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Pandas 合并多个Dataframe(merge,concat)的方法
在数据处理的时候,尤其在搞大数据竞赛的时候经常会遇到一个问题就是,多个表单的合并问题,比如一个表单有user_id和age这两个字段,另一个表单有user_id和sex这两个字段,要把这两个表合并成只有user_id.age.sex三个字段的表怎么办的,普通的拼接是做不到的,因为user_id每一行之间不是对应的,像拼积木似的横向拼接肯定是不行的. pandas中有个merge函数可以做到这个实用的功能,merge这个词会点SQL语言的应该都不陌生. 下面说说merge函数怎么用: df = p
-
pandas dataframe的合并实现(append, merge, concat)
创建2个DataFrame: >>> df1 = pd.DataFrame(np.ones((4, 4))*1, columns=list('DCBA'), index=list('4321')) >>> df2 = pd.DataFrame(np.ones((4, 4))*2, columns=list('FEDC'), index=list('6543')) >>> df3 = pd.DataFrame(np.ones((4, 4))*3, col
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind
-
pandas DataFrame实现几列数据合并成为新的一列方法
问题描述 我有一个用于模型训练的DataFrame如下图所示: 其中的country.province.city.county四列其实是位置信息的不同层级,应该合成一列用于模型训练 方法: parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county'] 就
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
pandas DataFrame 交集并集补集的实现
1.场景,对于colums都相同的dataframe做过滤的时候 例如: df1 = DataFrame([['a', 10, '男'], ['b', 11, '男'], ['c', 11, '女'], ['a', 10, '女'], ['c', 11, '男']], columns=['name', 'age', 'sex']) df2 = DataFrame([['a', 10, '男'], ['b', 11, '女']], columns=['name', 'age', 'sex']) 取
-

Pandas的DataFrame如何做交集,并集,差集与对称差集
目录 一.简介 二.交集 三.并集 四.差集 五.对称差集 一.简介 Python的数据类型集合:由不同元素组成的集合,集合中是一组无序排列的可 Hash 的值(不可变类型),可以作为字典的Key Pandas中的DataFrame:DataFrame是一个表格型的数据结构,可以理解为带有标签的二维数组. 常用的集合操作如下图所示: 二.交集 pandas的 merge 功能默认为 inner 连接,可以实现取交集 集合 set 可以直接用 & 取交集 import pandas as pd p
-
详解利用Pandas求解两个DataFrame的差集,交集,并集
目录 模拟数据 差集 方法1:concat + drop_duplicates 方法2:append + drop_duplicates 交集 方法1:merge 方法2:concat + duplicated + loc 方法3:concat + groupby + query 并集 方法1:concat + drop_duplicates 方法2:append + drop_duplicates 方法3:merge 大家好,我是Peter~ 本文讲解的是如何利用Pandas函数求解两个Dat
-
Pandas:DataFrame对象的基础操作方法
DataFrame对象的创建,修改,合并 import pandas as pd import numpy as np 创建DataFrame对象 # 创建DataFrame对象 df = pd.DataFrame([1, 2, 3, 4, 5], columns=['cols'], index=['a','b','c','d','e']) print df cols a 1 b 2 c 3 d 4 e 5 df2 = pd.DataFrame([[1, 2, 3],[4, 5, 6]], co
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
JS实现集合的交集、补集、差集、去重运算示例【ES5与ES6写法】
本文实例讲述了JS实现集合的交集.补集.差集.去重运算.分享给大家供大家参考,具体如下: ES5写法: ///集合取交集 Array.intersect = function () { var result = new Array(); var obj = {}; for (var i = 0; i < arguments.length; i++) { for (var j = 0; j < arguments[i].length; j++) { var str = arguments[i][
-
python中pandas.DataFrame排除特定行方法示例
前言 大家在使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,关于python中pandas.DataFrame的基本操作,大家可以查看这篇文章. pandas.DataFrame排除特定行 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. 但是如果我们只想要所有内容中不包含特定行的内容,却并没有一个isnotin()方法.我今天的工作就遇到了这样的需
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=