pandas按若干个列的组合条件筛选数据的方法
还是用图说话
A文件:

比如,我想筛选出“设计井别”、“投产井别”、“目前井别”三列数据都为11的数据,结果如下:

当然,这里的筛选条件可以根据用户需要自由调整,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 29 10:46:31 2017
@author: wq
"""
import pandas as pd
#input.csv是那个大文件,有很多很多行
df1 = pd.read_csv(u'input.csv', encoding='gbk')
#加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码
#这里的筛选条件可以根据用户需要进行修改
outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')]
outfile.to_csv('outfile.csv', index=False, encoding='gbk')
有时我们也会有相反的一个需求,需要删除“设计井别”、“投产井别”、“目前井别”三列数据都为11的那些行,效果如下:
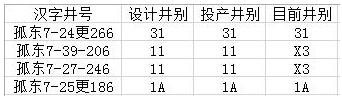
代码如下:
#input.csv是那个大文件,有很多很多行
df1 = pd.read_csv(u'input.csv', encoding='gbk')
df2 = pd.read_csv(u'outfile.csv', encoding='gbk')
#加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码
index = ~df1[u'汉字井号'].isin(df2[u'汉字井号'])
df4 = df1[index]
df4.to_csv('outfile1.csv', index=False, encoding='gbk')
以上这篇pandas按若干个列的组合条件筛选数据的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- 使用DataFrame删除行和列的实例讲解
- python pandas中DataFrame类型数据操作函数的方法
- pandas.DataFrame 根据条件新建列并赋值的方法
- python pandas dataframe 按列或者按行合并的方法
- pandas系列之DataFrame 行列数据筛选实例
相关推荐
-
pandas.DataFrame 根据条件新建列并赋值的方法
实例如下所示: import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2016,2015,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(
-
pandas系列之DataFrame 行列数据筛选实例
一.对DataFrame的认知 DataFrame的本质是行(index)列(column)索引+多列数据. 为了简化理解,我们不妨换个思路- 现实中,为了简化对一件事物的描述,我们会选择几个特征. 例如,从(性别.身高.学历.职业.爱好..)等角度去刻画一个人,这些"角度"即为"特征". 其中,不同的行表示不同的记录:列代表特征,不同记录因各个特征之间的差异而不同. DataFrame默认索引是序号(0,1,2-),可以理解成位置索引.一般我们用id标识不同记录,
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
使用DataFrame删除行和列的实例讲解
本文通过一个csv实例文件来展示如何删除Pandas.DataFrame的行和列 数据文件名为:example.csv 内容为: date spring summer autumn winter 2000 12.2338809 16.90730113 15.69238313 14.08596223 2001 12.84748057 16.75046873 14.51406637 13.5037456 2002 13.558175 17.2033926 15.6999475 13.23365247
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-

pandas按条件筛选数据的实现
pandas中对DataFrame筛选数据的方法有很多的,以后会后续进行补充,这里只整理遇到错误的情况. 1.使用布尔型DataFrame对数据进行筛选 使用一个条件对数据进行筛选,代码类似如下: num_red=flags[flags['red']==1] 使用多个条件对数据进行筛选,代码类似如下: stripes_or_bars=flags[(flags['stripes']>=1) | (flags['bars']>=1)] 常见的错误代码如下: 代码一: stripes_or_bars
-
Python实用技巧之列表、字典、集合中根据条件筛选数据详解
通用做法:迭代 以列表为例: 筛选出下列数字大于等于0的数 data = [2, 7, -4, -1, 3, 0, 8] res = [] for i in data: if i >= 0: res.append(i) print(res) 运行结果: [2, 7, 3, 0, 8] 奇淫巧技--列表筛选 使用filter函数 随机生成一组正负数皆有的数,筛选出大于等于0的数 flilter(function or None, iterable) from random import randi
-
Sql Server数据把列根据指定内容拆分数据的方法实例
今天由于工作需要,需要把数据把列根据指定的内容拆分数据 其中一条数据实例 select id , XXXX FROM BIZ_PAPER where id ='4af210ec675927fa016772bf7dd025b0' 拆分方法: select t3.id ,t3.XXXX as XXXX from ( select A.id , B.XXXX from ( SELECT id, XXXX = CONVERT(xml,'<root><v>' + REPLACE(XXXX
-
Pandas条件筛选与组合筛选的使用
目录 条件筛选 组合筛选 在使用pandas进行数据分析时,经常需要根据逻辑条件来筛选数据. 如果使用 for循环语句 遍历的方式来查找,将十分耗时. 推荐使用pandas自身的功能函数进行筛选,效率更高. 以下列出笔者常用的筛选方法. 条件筛选 根据具体值筛选 df[df['Num'] == 10] df[df['Name'] == 'Tom'] 找出df中值在具体列表中的数据 val_list = [100, 200, 300] df[df['Num'].isin(val_list)] 筛选
-
pandas 选取行和列数据的方法详解
前言 本文介绍在 pandas 中如何读取数据行列的方法.数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field).回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取.比如获取 student_id 和 studnent_name 两个字段:记录筛选,比如 sales_amount 大于 10000 的所有记录.对于熟悉 SQL 语句的人来说,就是下面的语句: select student_id, student_name
-
pandas实现将dataframe满足某一条件的值选出
在读取数据的时候发现,想把数据中第六列含问号的数据挑出来 import pandas as pd data = pd.read_table('breast-cancer-wisconsin.data.txt',header=None,encoding='gb2312',sep=',') data = data.drop(0, axis=1) data = data[data[6] != '?'] 以上这篇pandas实现将dataframe满足某一条件的值选出就是小编分享给大家的全部内容了,希望
-
对pandas中iloc,loc取数据差别及按条件取值的方法详解
Dataframe使用loc取某几行几列的数据: print(df.loc[0:4,['item_price_level','item_sales_level','item_collected_level','item_pv_level']]) 结果如下,取了index为0到4的五行四列数据. item_price_level item_sales_level item_collected_level item_pv_level 0 3 3 4 14 1 3 3 4 14 2 3 3 4 14
-
pandas如何优雅的列转行及行转列详解
目录 一.列转行 1.背景描述 2.方法描述 2.1 方法1 2.2 方法2 2.3 方法3 2.4 方法4 3 思考与总结 4 思维延伸 4.1 例子1 4.2 例子2 二.行转列 1.准备数据 2.行转列实现 2.1 方法1 2.2 方法2 2.3 方法3 3.思考与总结 三.行列转换(长宽互换) 总结 一.列转行 1.背景描述 在日常处理数据过程中,你们可能会经常遇到这种类型的数据: 而我们用pandas进行统计分析时,往往需要将结果转换成以下类型的数据: 2.方法描述 准备数据 df =
-
Python pandas删除指定行/列数据的方法实例
目录 1.滤除缺失数据dropna() 1)滤除含有NaN值的所有行 2)滤除含有NaN值的所有列 3)滤除元素都是NaN值的行 4)滤除元素都是NaN值的列 5)滤除指定列中含有缺失的行 2.删除重复值 drop_duplicates() 1)keep=“first” 2)keep=“last” 3)keep=False 4)删除指定列中重复项对应的行 3.根据指定条件删除行列drop() 1).删除指定列 2).删除指定行 总结 1.滤除缺失数据dropna() import pandas