Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程:
使用Python3.6.4环境(对中文支持比较好),安装Pandas包
pip install pandas
基本使用:
import pandas as pd
import numpy as np #进行具体的sum,count等计算时候要用到的
df=pd.read_csv('d:/snp/nh23.csv') #这里绝对路径一定要用/,windows下也是如此,不加参数默认csv文件首行为标题行
df.head() #查看引入的csv文件前5行数据
df[“播种面积”] #查看指定列,后面跟[:5]查看前5行数据
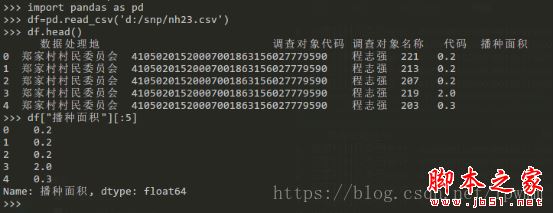
df[“调查对象代码”].str[:6] #获取指定列前6位字符串
df["ADDR"]=df["调查对象代码"].str[:6] #将上一行处理后的6位地址码作为新列ADDR插入

gp=df.groupby(["ADDR","代码"])["播种面积"].sum() #根据ADDR和代码进行分组后对播种面积列进行sum求和计算

pv=df.pivot_table(["播种面积"],index="ADDR",columns="代码",margins=True,aggfunc=np.sum,fill_value=0) #数据透视图,对播种面积列进行汇总计算,index为行,columns为列,margins=True增加一个全部行汇总,aggfunc=np.sum透视图中对播种面积值进行sum计算,这里np是开头import的numpy as np,fill_value=0对空值进行0替换,否则没有数据会显示NaN

pv.to_csv("d:/snp/test.csv") #写入csv文件
总结
以上所述是小编给大家介绍的Python使用Pandas对csv文件进行数据处理的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
Python使用pandas处理CSV文件的实例讲解
Python中有许多方便的库可以用来进行数据处理,尤其是Numpy和Pandas,再搭配matplot画图专用模块,功能十分强大. CSV(Comma-Separated Values)格式的文件是指以纯文本形式存储的表格数据,这意味着不能简单的使用Excel表格工具进行处理,而且Excel表格处理的数据量十分有限,而使用Pandas来处理数据量巨大的CSV文件就容易的多了. 我用到的是自己用其他硬件工具抓取得数据,硬件环境是在Linux平台上搭建的,当时数据是在运行脚本后直接输出在termin
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
python使用pandas处理excel文件转为csv文件的方法示例
由于客户提供的是excel文件,在使用时期望使用csv文件格式,且对某些字段内容需要做一些处理,如从某个字段中固定的几位抽取出来,独立作为一个字段等,下面记录下使用acaconda处理的过程: import pandas df = pandas.read_excel("/***/***.xlsx") df.columns = [内部为你给你的excel每一列自定义的名称](比如我给我的excel自定义列表为: ["url","productName&quo
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
python的pandas工具包,保存.csv文件时不要表头的实例
用pandas处理.csv文件时,有时我们希望保存的.csv文件没有表头,于是我去看了DataFrame.to_csv的document. 发现只需要再添加header=None这个参数就行了(默认是True), 下面贴上document: DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=Non
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-

python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
python 使用pandas读取csv文件的方法
目录 pandas读取csv文件的操作 1. 读取csv文件 在这里记录一下,python使用pandas读取文件的方法用到pandas库的read_csv函数 # -*- coding: utf-8 -*- """ Created on Mon Jan 24 16:48:32 2022 @author: zxy """ # 导入包 import numpy as np import pandas as pd import matplotlib.
-
Python使用pandas导入csv文件内容的示例代码
目录 使用pandas导入csv文件内容 1. 默认导入 2. 指定分隔符 3. 指定读取行数 4. 指定编码格式 5. 列标题与数据对齐 使用pandas导入csv文件内容 1. 默认导入 在Python中导入.csv文件用的方法是read_csv(). 使用read_csv()进行导入时,指定文件名即可 import pandas as pd df = pd.read_csv(r'G:\test.csv') print(df) 2. 指定分隔符 read_csv()默认文件中的数据都是以逗号
-
利用numpy和pandas处理csv文件中的时间方法
环境:numpy,pandas,python3 在机器学习和深度学习的过程中,对于处理预测,回归问题,有时候变量是时间,需要进行合适的转换处理后才能进行学习分析,关于时间的变量如下所示,利用pandas和numpy对csv文件中时间进行处理. date (UTC) Price 01/01/2015 0:00 48.1 01/01/2015 1:00 47.33 01/01/2015 2:00 42.27 #coding:utf-8 import datetime import pandas as
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
对Python 多线程统计所有csv文件的行数方法详解
如下所示: #统计某文件夹下的所有csv文件的行数(多线程) import threading import csv import os class MyThreadLine(threading.Thread): #用于统计csv文件的行数的线程类 def __init__(self,path): threading.Thread.__init__(self) #父类初始化 self.path=path #路径 self.line=-1 #统计行数 def run(self): reader =
-
Python 3.x读写csv文件中数字的方法示例
前言 本文主要给大家介绍了关于Python3.x读写csv文件中数字的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 读写csv文件 读文件时先产生str的列表,把最后的换行符删掉:然后一个个str转换成int ## 读写csv文件 csv_file = 'datas.csv' csv = open(csv_file,'w') for i in range(1,20): csv.write(str(i) + ',') if i % 10 == 0: csv.write