python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响
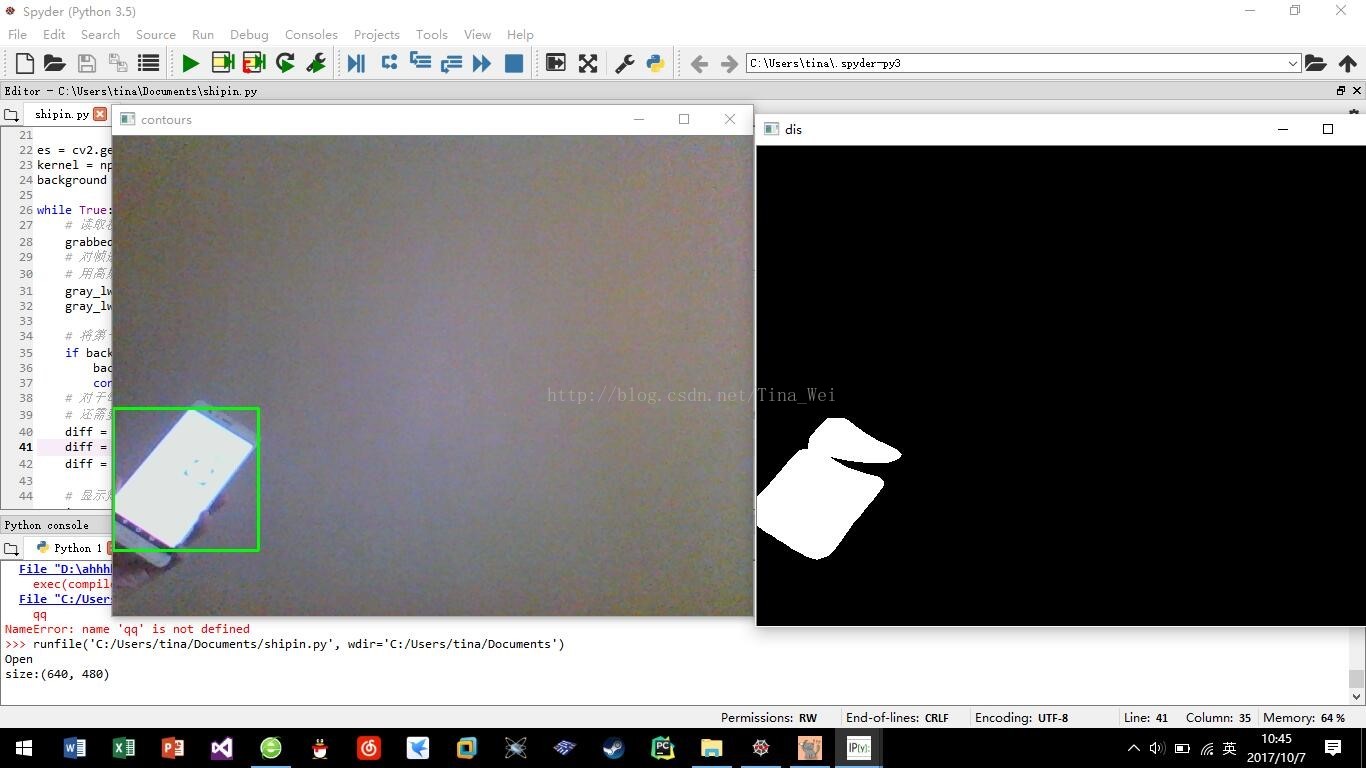
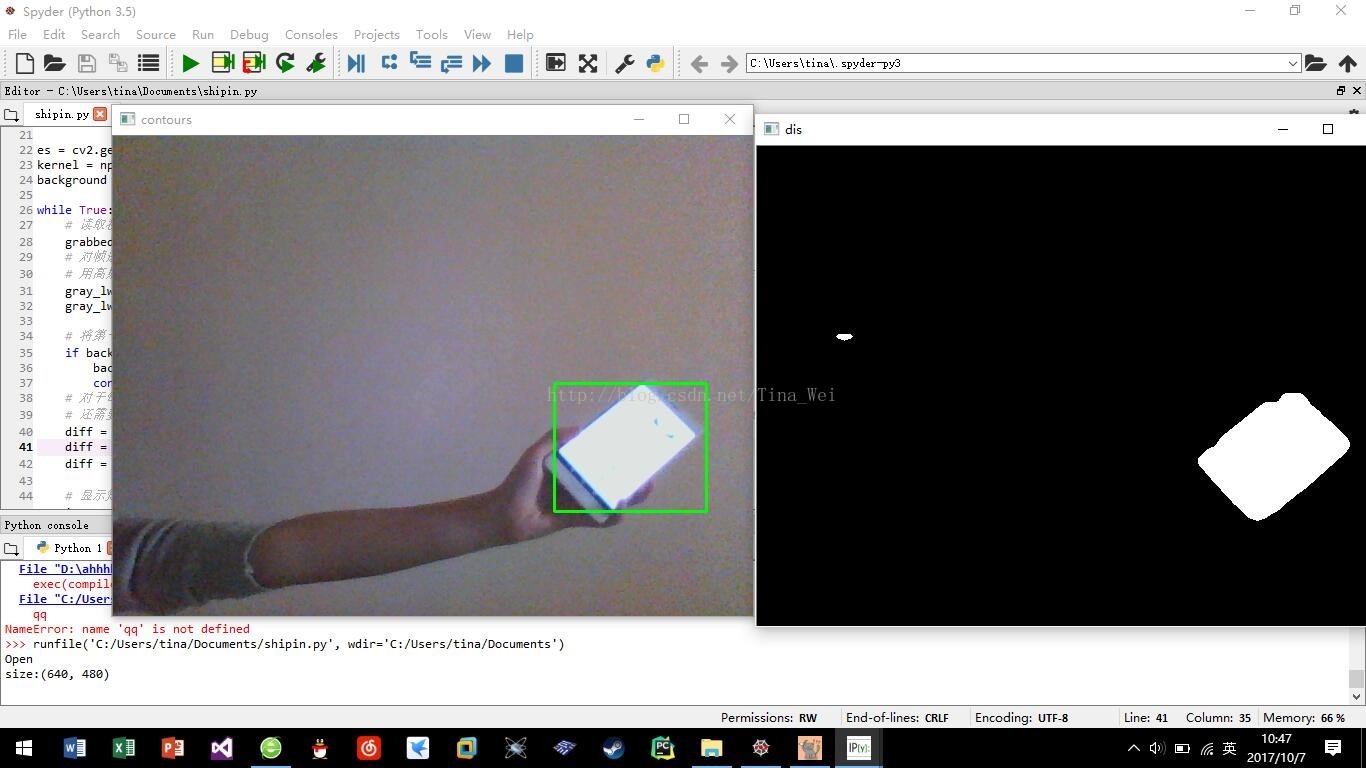
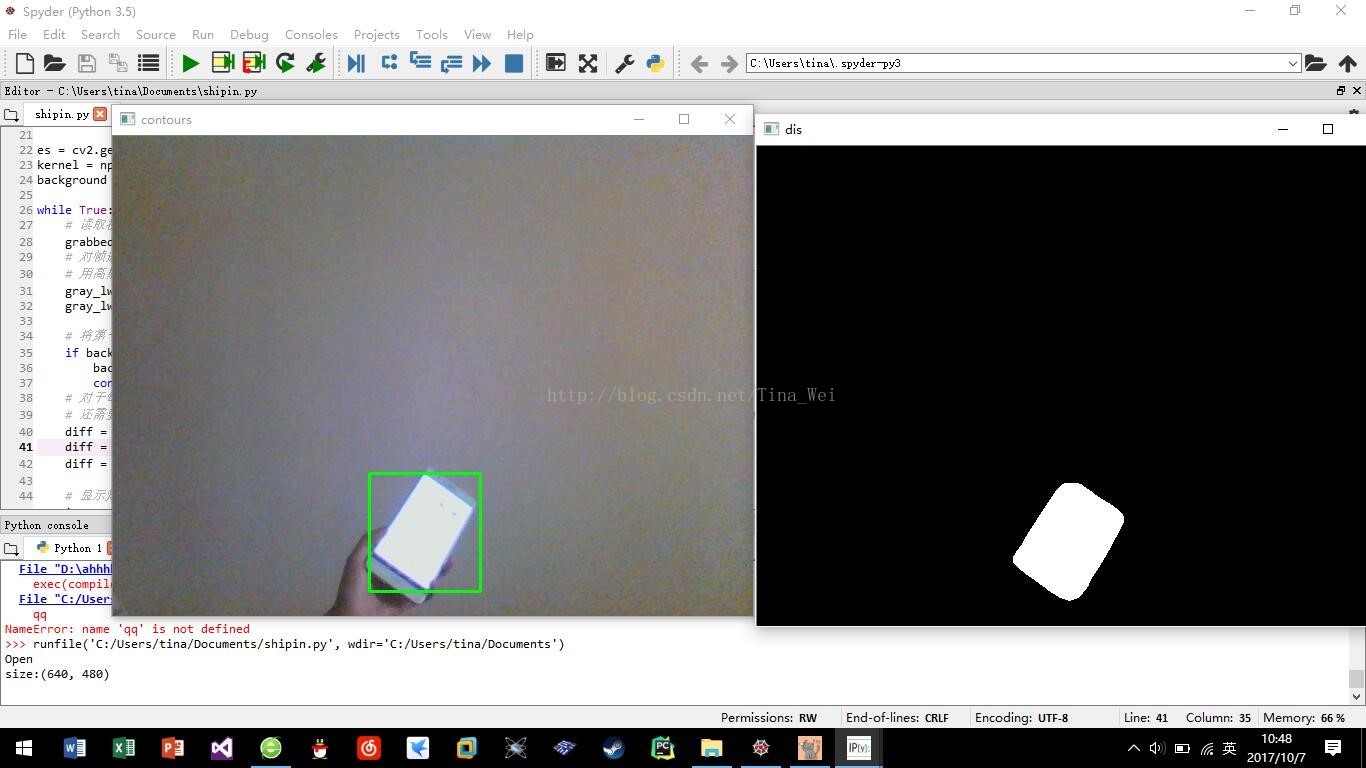
自己在家拿着手机瞎晃的成果图:

源代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 27 15:47:54 2017
@author: tina
"""
import cv2
import numpy as np
camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头
# 判断视频是否打开
if (camera.isOpened()):
print('Open')
else:
print('摄像头未打开')
# 测试用,查看视频size
size = (int(camera.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(camera.get(cv2.CAP_PROP_FRAME_HEIGHT)))
print('size:'+repr(size))
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 4))
kernel = np.ones((5, 5), np.uint8)
background = None
while True:
# 读取视频流
grabbed, frame_lwpCV = camera.read()
# 对帧进行预处理,先转灰度图,再进行高斯滤波。
# 用高斯滤波进行模糊处理,进行处理的原因:每个输入的视频都会因自然震动、光照变化或者摄像头本身等原因而产生噪声。对噪声进行平滑是为了避免在运动和跟踪时将其检测出来。
gray_lwpCV = cv2.cvtColor(frame_lwpCV, cv2.COLOR_BGR2GRAY)
gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21), 0)
# 将第一帧设置为整个输入的背景
if background is None:
background = gray_lwpCV
continue
# 对于每个从背景之后读取的帧都会计算其与北京之间的差异,并得到一个差分图(different map)。
# 还需要应用阈值来得到一幅黑白图像,并通过下面代码来膨胀(dilate)图像,从而对孔(hole)和缺陷(imperfection)进行归一化处理
diff = cv2.absdiff(background, gray_lwpCV)
diff = cv2.threshold(diff, 148, 255, cv2.THRESH_BINARY)[1] # 二值化阈值处理
diff = cv2.dilate(diff, es, iterations=2) # 形态学膨胀
# 显示矩形框
image, contours, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 该函数计算一幅图像中目标的轮廓
for c in contours:
if cv2.contourArea(c) < 1500: # 对于矩形区域,只显示大于给定阈值的轮廓,所以一些微小的变化不会显示。对于光照不变和噪声低的摄像头可不设定轮廓最小尺寸的阈值
continue
(x, y, w, h) = cv2.boundingRect(c) # 该函数计算矩形的边界框
cv2.rectangle(frame_lwpCV, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow('contours', frame_lwpCV)
cv2.imshow('dis', diff)
key = cv2.waitKey(1) & 0xFF
# 按'q'健退出循环
if key == ord('q'):
break
# When everything done, release the capture
camera.release()
cv2.destroyAllWindows()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python+opencv实现的简单人脸识别代码示例
- 详解如何用OpenCV + Python 实现人脸识别
- python使用opencv进行人脸识别
- Python+Opencv识别两张相似图片
相关推荐
-

Python+Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
详解如何用OpenCV + Python 实现人脸识别
下午的时候,配好了OpenCV的Python环境,OpenCV的Python环境搭建.于是迫不及待的想体验一下opencv的人脸识别,如下文. 必备知识 Haar-like 通俗的来讲,就是作为人脸特征即可. Haar特征值反映了图像的灰度变化情况.例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等. opencv api 要想使用opencv,就必须先知道其能干什么,怎么做.于是API的重要性便体现出来了.就本例而言,使用到的函数
-
python使用opencv进行人脸识别
环境 ubuntu 12.04 LTS python 2.7.3 opencv 2.3.1-7 安装依赖 sudo apt-get install libopencv-* sudo apt-get install python-opencv sudo apt-get install python-numpy 示例代码 #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv d
-
python+opencv实现的简单人脸识别代码示例
# 源码如下: #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv def detect_object(image): '''检测图片,获取人脸在图片中的坐标''' grayscale = cv.CreateImage((image.width, image.height), 8, 1) cv.CvtColor(image, grayscale, cv.CV_BGR2GR
-
python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: # -*- coding: utf-8 -*- """ Created on Wed Sep 27 15:47:54 2017 @author: tina """ import cv2 import numpy as np camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头 # 判断视频是否打开 if (camera.isOpened()
-
python+opencv实现动态物体追踪
简单几行就可以实现对动态物体的追踪,足见opencv在图像处理上的强大. python代码: import cv2 import numpy as np camera=cv2.VideoCapture(0) firstframe=None while True: ret,frame = camera.read() if not ret: break gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) gray=cv2.GaussianBlur(gray,(21
-
python opencv 检测移动物体并截图保存实例
最近在老家找工作,无奈老家工作真心太少,也没什么面试机会,不过之前面试一家公司,提了一个有意思的需求,检测河面没有有什么船只之类的物体,我当时第一反应是用opencv做识别,不过回家想想,河面相对的东西比较少,画面比较单一,只需要检测有没有移动的物体不就简单很多嘛,如果做街道垃圾检测的话可能就很复杂了,毕竟街道上行人,车辆,动物,很多干扰物,于是就花了一个小时写了一个小的demo,只需在程序同级目录创建一个img目录就可以了 # -*-coding:utf-8 -*- __author__ =
-
Python+OpenCV手势检测与识别Mediapipe基础篇
目录 前言 项目效果图 认识Mediapipe 项目环境 代码 核心代码 视频帧率计算 完整代码 项目输出 结语 前言 本篇文章适合刚入门OpenCV的同学们.文章将介绍如何使用Python利用OpenCV图像捕捉,配合强大的Mediapipe库来实现手势检测与识别:本系列后续还会继续更新Mediapipe手势的各种衍生项目,还请多多关注! 项目效果图 视频捕捉帧数稳定在(25-30) 认识Mediapipe 项目的实现,核心是强大的Mediapipe ,它是google的一个开源项目: 功能
-
python+OpenCV实现车牌号码识别
基于python+OpenCV的车牌号码识别,供大家参考,具体内容如下 车牌识别行业已具备一定的市场规模,在电子警察.公路卡口.停车场.商业管理.汽修服务等领域已取得了部分应用.一个典型的车辆牌照识别系统一般包括以下4个部分:车辆图像获取.车牌定位.车牌字符分割和车牌字符识别 1.车牌定位的主要工作是从获取的车辆图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来 这里所采用的是利用车牌的颜色(黄色.蓝色.绿色) 来进行定位 #定位车牌 def color_position(img,ou
-
python OpenCV实现答题卡识别判卷
本文实例为大家分享了python OpenCV实现答题卡识别判卷的具体代码,供大家参考,具体内容如下 完整代码: #导入工具包 import numpy as np import argparse import imutils import cv2 # 设置参数 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", default="./images/test_03.png"
-
opencv检测动态物体的实现
之前我在超市看到当有物体经过时,监控的屏幕边缘会出现绿框.感觉蛮有意思的.来用opencv试试能不能实现类似的效果. 我采用的检测动态物体的方法是,比较前后两帧图像,即当前画面与上一帧的画面出现了不同.我们把两帧画面进行比较.然后框选出运动的物体.我们还希望程序可以判断当前窗口到底有没有物体在运动.那么我们就需要添加一个状态.为了方便我们找到什么时间有物体移动,我打印出时间. 当我们的程序检测到移动的物体时,会捕捉到它的轮廓,添加一个外接整矩形框,返回x,y的坐标.当不返回坐标时,则意味
-
python+opencv实现文字颜色识别与标定功能
最近接了一个比较简单的图像处理的单子,花了一点时间随便写了一下: 数据集客户没有是自己随便创建的: 程序如下: """ Code creation time:September 11, 2021 Author:PanBo Realize function:It mainly realizes the recognition and calibration of fonts with different colors """ import nump
-
Python+OpenCV进行人脸面部表情识别
目录 前言 一.图片预处理 二.数据集划分 三.识别笑脸 四.Dlib提取人脸特征识别笑脸和非笑脸 前言 环境搭建可查看Python人脸识别微笑检测 数据集可在https://inc.ucsd.edu/mplab/wordpress/index.html%3Fp=398.html获取 数据如下: 一.图片预处理 import dlib # 人脸识别的库dlib import numpy as np # 数据处理的库numpy import cv2 # 图像处理的库OpenCv import os
-
Python Opencv使用ann神经网络识别手写数字功能
opencv中也提供了一种类似于Keras的神经网络,即为ann,这种神经网络的使用方法与Keras的很接近.关于mnist数据的解析,读者可以自己从网上下载相应压缩文件,用python自己编写解析代码,由于这里主要研究knn算法,为了图简单,直接使用Keras的mnist手写数字解析模块.本次代码运行环境为:python 3.6.8opencv-python 4.4.0.46opencv-contrib-python 4.4.0.46 下面的代码为使用ann进行模型的训练: from kera