python使用ddt过程中遇到的问题及解决方案【推荐】
前言:
在使用DDT数据驱动+HTMLTestRunner输出测试报告时遇到过2个问题:
1、生成的测试报告中,用例名称后有dict() -> new empty dictionary
2、使用ddt生成的用例名称无法更改
1、用例名称后有dict() -> new empty dictionary
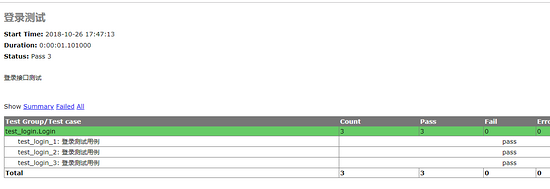
报告中用例名称后有dict() -> new empty dictionary,如图所示:

解决方案:这是ddt高版本1.2.0的bug
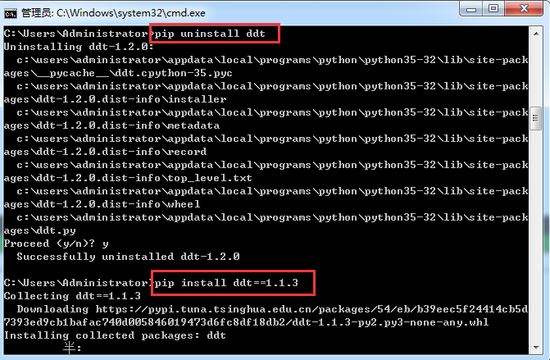
1、cmd先通过pip uninstall ddt 卸载ddt,
2、然后再安装一个低版本的ddt,命令pip install ddt==1.1.3
安装后再运行程序,结果如下
2、使用ddt生成的用例名称无法更改
如上图所示测试用例名称都是test_api_index,运行结果无法看出用例执行的是哪条数据,翻阅网上的资料找到一个比较好的方法,讲解比较详细,这段内容来自链接https://www.cnblogs.com/Simple-Small/p/9230382.html
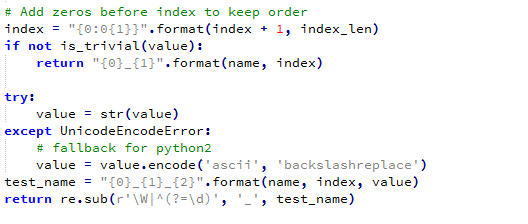
ddt源码中有个函数用来生成用例名称, mk_test_name
它接收两个参数:name 和 value.
name:为测试用例的名字。即test_api.
value:为测试数据,ddt是处理一组测试数据。而这个value就是这一组数据中的每一个测试数据。
对value的值是有限制的:要么就是单值变量,要么就是元组或者列表并且要求元组和列表中的数据都是单值变量。如("name","port") 、["name","port"]
如果传进来的测试数据,不符合value的要求,那么测试用例名字为:name_index。
如果传进来的测试数据,符合value的要求,那么测试用例名字为:name_index_value。如果value为列表或者元组,那么将列表/元组的每个数据依次追加在末尾。
比如传进来的name值为test_login,value值为["name","port"]。那最终的测试用例名字是:test_login_01_name_port。
如果传进来的name值为test_login,value值为{"userName":"18500384561", "password":"123456"},那最终的测试用例名字为:test_login_1。 因为它不支持对字典类型的数据处理 。
而我的接口自动化框架中,ddt处理的数据是一列表:列表当中每个数据都为字典。ddt一遍历整个列表,那传给value的值刚好是字典。。
所以我得到的测试用例名称就是:test_login_1,test_login_2,test_login_3
为了让我的测试报告,呈现的更好。那就改改ddt源码,让它能够适应我的框架。
考虑两个问题:
1、不同接口的测试用例名字如何来??
2、如何让ddt支持对字典的处理??
解决方案:
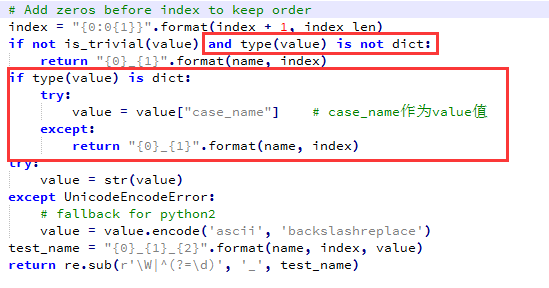
第一个问题:每一个测试用例主动提供一个用例名字,说明你是什么接口的什么场景用例。比如:接口名_场景名。login_success、login_noPasswd、login_wrongPasswd等。
在我的框架当中,每一个测试用例是一个字典。那么我就在字典中添加一个键值对,case_name=用例名称
第二个问题:在ddt中添加对字典的处理,如果字典中有case_name字段,则将字典中键名为case_name的值作为测试用例名称中的value值。
修改后的ddt源码为(红色粗体部分为修改的内容):
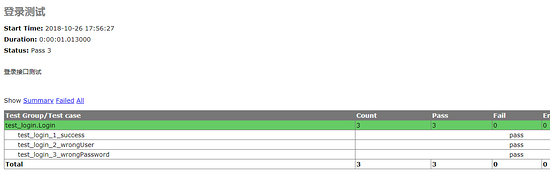
更改代码后再执行,结果如下:
总结
以上所述是小编给大家介绍的python使用ddt过程中遇到的问题及解决方案,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
python ddt实现数据驱动
ddt 是第三方模块,需安装, pip install ddt DDT包含类的装饰器ddt和两个方法装饰器data(直接输入测试数据) 通常情况下,data中的数据按照一个参数传递给测试用例,如果data中含有多个数据,以元组,列表,字典等数据,需要自行在脚本中对数据进行分解或者使用unpack分解数据. @data(a,b) 那么a和b各运行一次用例 @data([a,d],[c,d]) 如果没有@unpack,那么[a,b]当成一个参数传入用例运行 如果有@unpack,那么[a,b]被分解
-

python使用ddt过程中遇到的问题及解决方案【推荐】
前言: 在使用DDT数据驱动+HTMLTestRunner输出测试报告时遇到过2个问题: 1.生成的测试报告中,用例名称后有dict() -> new empty dictionary 2.使用ddt生成的用例名称无法更改 1.用例名称后有dict() -> new empty dictionary 报告中用例名称后有dict() -> new empty dictionary,如图所示: 解决方案:这是ddt高版本1.2.0的bug 1.cmd先通过pip uninstall ddt
-
解决Python httpx 运行过程中无限阻塞的问题
目录 Python httpx 运行过程中无限阻塞 1.通过 pm2 部署脚本 2.通过装饰器给函数设置一个最大执行超时时间 python爬虫httpx的用法 请求方式 Python httpx 运行过程中无限阻塞 requests 模块只支持 http1,在遇到 http2 的数据接口的时候(某乎的搜索接口),需要采用支持http2 请求的模块(如 httpx.hyper). 本文是针对 httpx 在请求数据时,出现无限阻塞问题的一些处理方法. httpx 的 timeout 有 bug,会
-
SQL Server成功与服务器建立连接但是在登录过程中发生错误的快速解决方案
最近在VS2013上连接远程数据库时,突然连接不上,在跑MSTest下跑的时候,QTAgent32 crash.换成IIS下运行的时候,IIS crash.之前的连接是没问题的,后网上找了资料,根据牛人所说的方案解决了. 1. Exception message 已成功与服务器建立连接,但是在登录过程中发生错误. (provider: SSL Provider, error: 0 - 接收到的消息异常,或格式不正确.) ---> System.ComponentModel.Win32Except
-
总结Nginx 的使用过程中遇到的问题及解决方案
在启动 Nginx 的时候,有时候会遇到这样的一个错误: 复制代码 代码如下: [emerg]: could not build the proxy_headers_hash, you should increase either proxy_headers_hash_max_size: 512 or proxy_headers_hash_bucket_size: 64 解决办法就是在配置文件中新增以下配置项: 复制代码 代码如下: proxy_headers_hash_max_size 512
-
idea 与 maven 使用过程中遇到的问题及解决方案
目录 1. maven项目导入idea报ComponentLookupException异常 1.1. 问题描述 1.2.解决方案 2. IDEA无法加载maven本地仓库的文件 2.1.问题描述 2.2.解决方案 3.删除maven下载失败的jar包 3.1. 问题描述 3.2.解决方案 4. 删除_maven.repositories文件 4.1.问题描述 4.2.解决方案 1. maven项目导入idea报ComponentLookupException异常 1.1. 问题描述 最近将ID
-
对Python新手编程过程中如何规避一些常见问题的建议
这篇文章收集了我在Python新手开发者写的代码中所见到的不规范但偶尔又很微妙的问题.本文的目的是为了帮助那些新手开发者渡过写出丑陋的Python代码的阶段.为了照顾目标读者,本文做了一些简化(例如:在讨论迭代器的时候忽略了生成器和强大的迭代工具itertools). 对于那些新手开发者,总有一些使用反模式的理由,我已经尝试在可能的地方给出了这些理由.但通常这些反模式会造成代码缺乏可读性.更容易出bug且不符合Python的代码风格.如果你想要寻找更多的相关介绍资料,我极力推荐The Pytho
-
Python结巴中文分词工具使用过程中遇到的问题及解决方法
本文实例讲述了Python结巴中文分词工具使用过程中遇到的问题及解决方法.分享给大家供大家参考,具体如下: 结巴分词是Python语言中效果最好的分词工具,其功能包括:分词.词性标注.关键词抽取.支持用户词表等.这几天一直在研究这个工具,在安装与使用过程中遇到一些问题,现在把自己的一些方法帖出来分享一下. 官网地址:https://github.com/fxsjy/jieba 1.安装. 按照官网上的说法,有三种安装方式, 第一种是全自动安装:easy_install jieba 或者 pip
-
jupyter notebook 使用过程中python莫名崩溃的原因及解决方式
最近在使用 Python notebook时老是出现python崩溃的现象,如下图,诱发的原因是"KERNELBASE.dll",异常代码报"40000015". 折腾半天,发现我启动notebook时是用自定义startup.bat方式方式启动的,bat文件的内容为 start C:\Anaconda3\python.exe "C:/Anaconda3/Scripts/jupyter-notebook-script.py" 平时双击这个bat文
-
总结Python使用过程中的bug
Python使用过程中的bug 问题: 在vscode中, 使用 Windows PowerShell 运行 conda activate xxx (某个环境)切换环境时报错: If using 'conda activate' from a batch script, change your invocation to 'CALL conda.bat activate'. 原因: PowerShell 有时不好使 解决方法: 改为用 cmd 运行 问题: conda install xxxx
-
Python中遍历字典过程中更改元素导致异常的解决方法
先来回顾一下Python中遍历字典的一些基本方法: 脚本: #!/usr/bin/python dict={"a":"apple","b":"banana","o":"orange"} print "##########dict######################" for i in dict: print "dict[%s]=" % i,