C语言超详细讲解排序算法上篇
目录
- 1、直接插入排序
- 2、希尔排序(缩小增量排序)
- 3、直接选择排序
- 4、堆排序
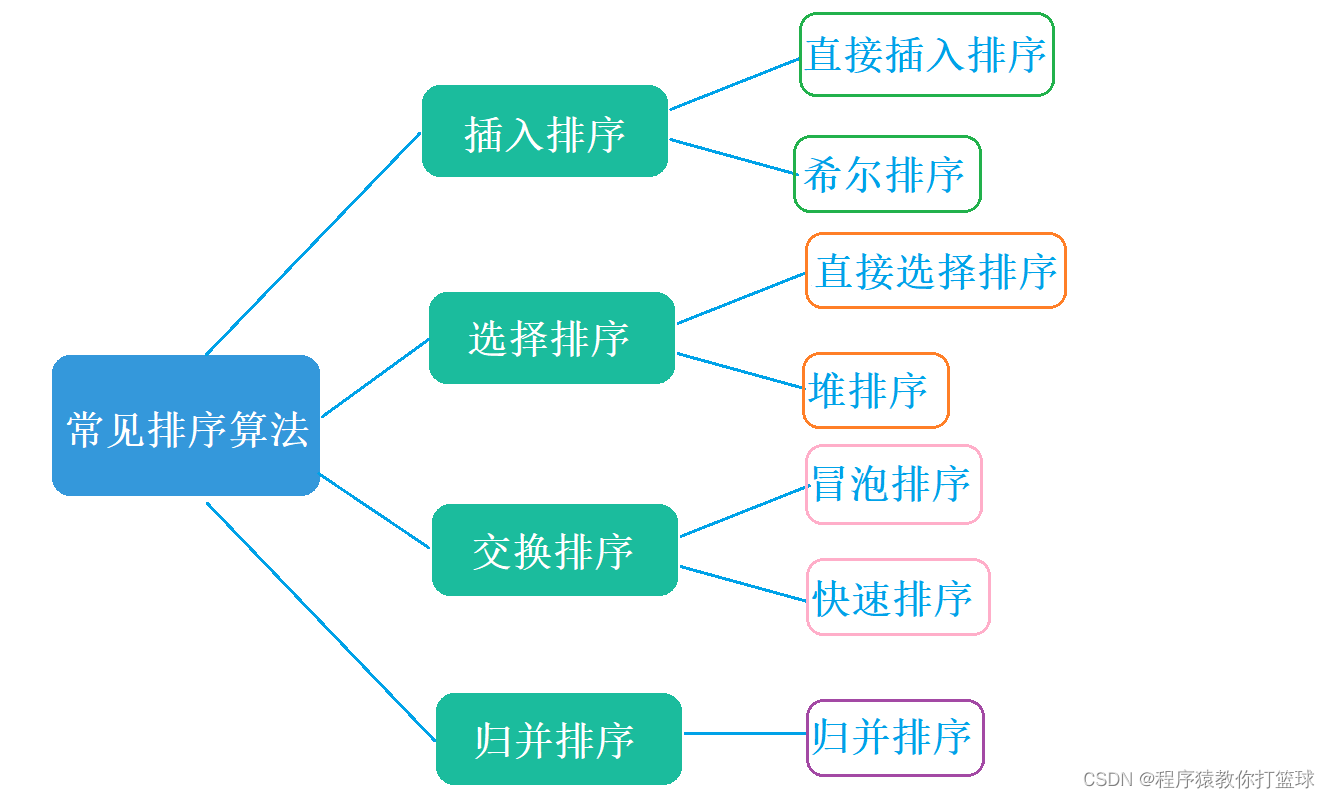
进入正式内容之前,我们先了解下初阶常见的排序分类 :我们今天讲前四个!
1、直接插入排序
基本思想:当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排 序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移!
直接插入排序的特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2) 、空间复杂度:O(1)
3. 稳定性:稳定

void InsertSort(int* a, int n)
{
//直接插入排序 ———— 升序
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (a[i] > tmp) //如果比tmp大的话就往后移
{
a[end + 1] = a[end];
--end;
}
else //如果tmp比当前元素大的话就不需要交换位置了,直接跳出循环!
{
break;
}
}
a[end + 1] = tmp; // 最后把tmp放到比他小的元素后面!
}
}
2、希尔排序(缩小增量排序)
基本思想:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后重复分组和排序的工作。当到达gap=1时,所有记录在统一组内排好序。
希尔排序的特性总结:
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的 了,这样就会很快。这样整体而言,可以达到优化的效果。
3. 希尔排序的时间复杂度不好计算,需要进行推导,推导出来平均时间复杂度: O(N^1.3— N^2)
4. 稳定性:不稳定

void ShellSort(int* a, int n)
{
//希尔排序————升序
int gap = n;
while (gap > 1)
{
gap = gap / 2;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end = end - gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
}
}
}
3、直接选择排序
基本思想:
在元素集合array[i]--array[n-1]中选择关键码最大(小)的数据元素 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换 在剩余的array[i]--array[n-2](array[i+1]--array[n-1])集合中,重复上述步骤,直到集合剩余1个元素。
直接选择排序的特性总结:(因为特别简单就不画图了直接上代码)
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2. 时间复杂度:O(N^2) 、空间复杂度:O(1)
3. 稳定性:不稳定
这里我们用一个优化版本,每次确定两个数的最终位置:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int min = begin;
int max = begin;
for (int i = begin; i <= end; ++i)
{
if (a[i] < a[min])
{
min = i;
}
if (a[i] > a[max])
{
max = i;
}
}
Swap(&a[min], &a[begin]);
if (max == begin) //如果max等于begin的话就证明最大值是begin的位置
//需要修正max的位置
{
max = min;
}
Swap(&a[max], &a[end]);
++begin;
--end;
}
}
4、堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的 一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
堆排序的特性总结:
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN) 、空间复杂度:O(1)
3. 稳定性:不稳定
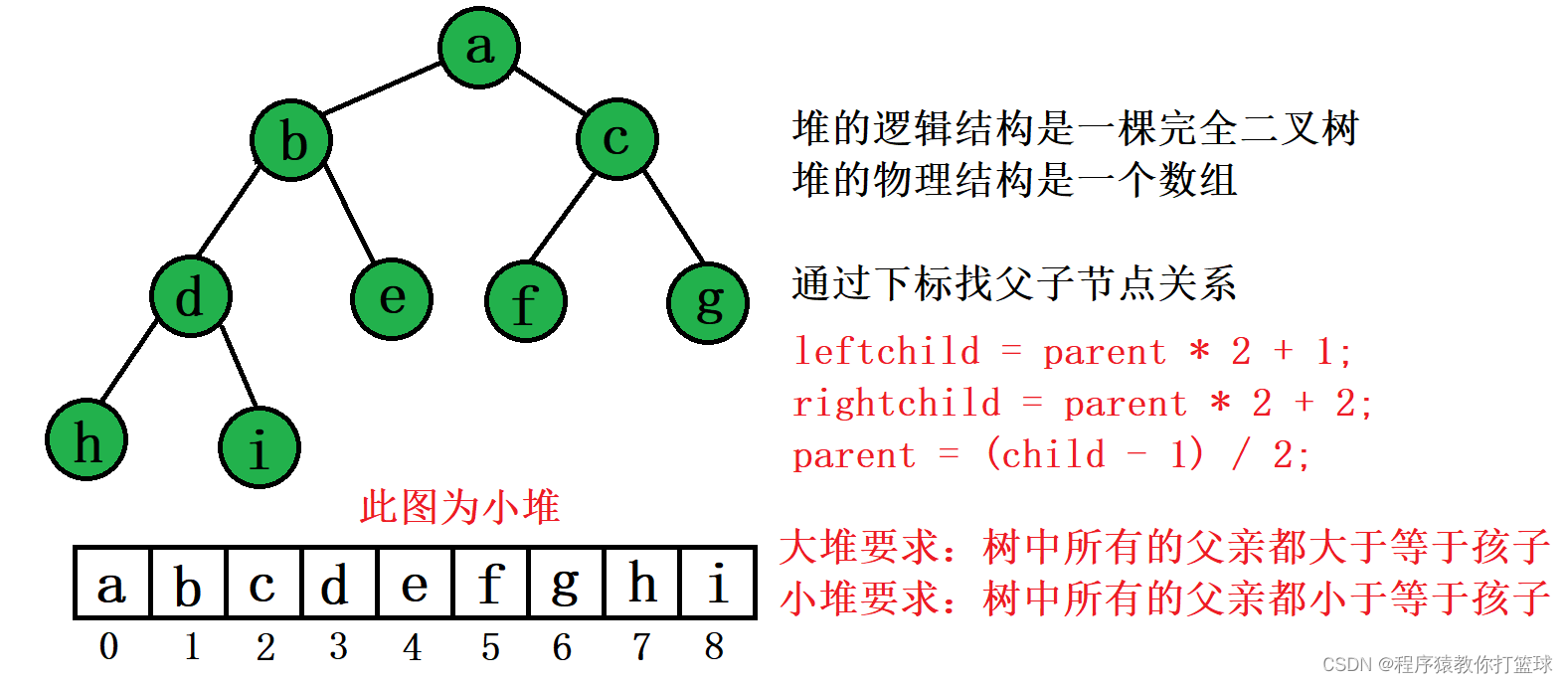

void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child = child + 1;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
建议小伙伴们看完之后一定要自己尝试画图,以及代码练习!如果前面C语言代码量不多的话,写起来也会很吃力的!里面也涉及到了二叉树的相关知识,如果有疑问可以直接联系我!
小伙伴们,咱们软件这一行,实力才是硬道理,爱打篮球的程序猿想送你们一句话:虽然过去不能改变,但未来可以!加油,趁现在!
gitee(码云):Mercury. (zzwlwp) - Gitee.com
到此这篇关于C语言超详细讲解排序算法上篇的文章就介绍到这了,更多相关C语言 排序算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言数据结构与算法之排序总结(一)
目录 一.前言 二.基本概念 1.排序 2.排序方法的稳定性 3.内部和外部排序 三.插入类排序 1.直接插入排序 2.折半插入排序 3.希尔排序 四.交换类排序 1.冒泡排序 2.快速排序 五.总结比较 一.前言 学习目标: 排序和查找密不可分,将待处理的数据按关键值大小有序排列后,查找更加快速准确 理解各种排序算法的定义和特点,并能将代码灵活运用 掌握各种排序方法时间复杂度与空间复杂度 理解排序稳定和不稳定的概念 重点和难点: 希尔.快速.堆.归并排序这几种快
-
C语言中冒泡排序算法详解
目录 一.算法描述 二.算法分析 三.完整代码 总结 一.算法描述 比较相邻两个元素,如果第一个比第二个大则交换两个值.遍历所有的元素,每一次都会将未排序序列中最大的元素放在后面.假设数组有 n 个元素,那么需要遍历 n - 1 次,因为剩下的一个元素一定是最小的,无需再遍历一次.因此需要两层循环,第一层是遍历次数,第二层是遍历未排序数组. 动图如下: 黄色部分表示已排好序的数组,蓝色部分表示未排序数组 核心代码如下: /** * @brief 冒泡排序 * * @param arr 待排序的数
-
C语言数据结构经典10大排序算法刨析
1.冒泡排序 // 冒泡排序 #include <stdlib.h> #include <stdio.h> // 采用两层循环实现的方法. // 参数arr是待排序数组的首地址,len是数组元素的个数. void bubblesort1(int *arr,unsigned int len) { if (len<2) return; // 数组小于2个元素不需要排序. int ii; // 排序的趟数的计数器. int jj; // 每趟排序的元素位置计数器. int itmp
-
C语言之直接插入排序算法的方法
目录 一.什么是直接插入排序 二.代码讲解 总结 直接 插入排序 (Straight Insertion Sort)是一种最简单的排序方法,其基本操作是将一条记录插入到已排好的有序表中,从而得到一个新的.记录数量增1的有序表.. 废话不多说先看看代码 #define _CRT_SECURE_NO_WARNINGS 1 //直接插入排序法 #include <stdio.h> void Compare(int arr[], int len) { int i = 0; for (i = 0; i
-
C语言实现单链表的快速排序算法
目录 背景 设计思路 算法主要步骤 快速排序算法实现 整个程序源代码 测试案例 总结 背景 传统QuickSort算法最大不足之处在于,由于其基于可索引存储结构设计(一般为数组或索引表),因而无法用于链式存储结构,而链式存储结构的实际应用非常广泛,例如动态存储管理.动态优先级调度等等,故本文针对于单向链表,以QuickSort的分治策略为基础,提出一种可用于单向链表的快速排序算法. 设计思路 将单向链表的首节点作为枢轴节点,然后从单向链表首部的第二个节点开始,逐一遍历所有后续节点,并将这些已遍历
-
C语言直接插入排序算法介绍
目录 前言 一.什么是直接插入排序 二.代码讲解 总结 前言 直接 插入排序 (Straight Insertion Sort)是一种最简单的排序方法,其基本操作是将一条记录插入到已排好的有序表中,从而得到一个新的.记录数量增1的有序表.. 废话不多说先看看代码 #define _CRT_SECURE_NO_WARNINGS 1 //直接插入排序法 #include <stdio.h> void Compare(int arr[], int len) { int i = 0; for (i =
-
C语言直接插入排序算法
目录 1.算法模板 2.算法介绍 3.实例 总结 1.算法模板 void InsertSort(SqList *L) { int j; for (int i = 2; i <= L->length; i ++ ) { if (L->arr[i] < L->arr[i-1]) { L->arr[0] = L->arr[i]; // 设置哨兵 for (j = i - 1; L->arr[j] > L->arr[0]; j -- ) L->ar
-
C语言超详细讲解排序算法上篇
目录 1.直接插入排序 2.希尔排序(缩小增量排序) 3.直接选择排序 4.堆排序 进入正式内容之前,我们先了解下初阶常见的排序分类 :我们今天讲前四个! 1.直接插入排序 基本思想:当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排 序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移! 直接插入排序的特性总结: 1. 元素集
-
C语言超详细讲解排序算法下篇
上期学习完了前四个排序,这期我们来学习剩下的三个排序:
-
C语言超详细梳理排序算法的使用
目录 排序的概念及其运用 排序的概念 排序运用 插入排序 直接插入排序 希尔排序 选择排序 直接选择排序 堆排序 交换排序之冒泡排序 总结 排序的概念及其运用 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作. 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法
-
C语言 超详细讲解算法的时间复杂度和空间复杂度
目录 1.前言 1.1 什么是数据结构? 1.2 什么是算法? 2.算法效率 2.1 如何衡量一个算法的好坏 2.2 算法的复杂度 2.3 复杂度在校招中的考察 3.时间复杂度 3.1 时间复杂度的概念 3.2 大O的渐进表示法 3.3 常见时间复杂度计算举例 4.空间复杂度 5. 常见复杂度对比 1.前言 1.1 什么是数据结构? 数据结构(Data Structure)是计算机存储.组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合. 1.2 什么是算法? 算法(Algorit
-
C语言超详细讲解数据结构中双向带头循环链表
目录 一.概念 二.必备工作 2.1.创建双向链表结构 2.2.初始化链表 2.3.动态申请节点 2.4.打印链表 2.5.销毁链表 三.主要功能 3.1.在pos节点前插入数据 尾插 头插 3.2.删除pos处节点数据 尾删 头删 3.3.查找数据 四.总代码 List.h 文件 List.c 文件 Test.c 文件 五.拓展 一.概念 前文我们已经学习了单向链表,并通过oj题目深入了解了带头节点的链表以及带环链表,来画张图总体回顾下: 在我们学习的链表中,其实总共有8种,都是单双向和带不带
-
C语言超详细讲解字符串相乘
目录 前言 一. 分析思路 二.使用步骤 1.代码如下 2.memset函数 三.总结 前言 我们已经知道,正常的两位整形数据通过*相乘,C语言中int为4字节,32bit(字节),其机器码第一位为符号位,余下31位表示数字,表示范围:-2^31(-2147483648)~2^31-1(2147483647),但超过了这个范围我们该如何做呢? 提示:将数字以字符串的形式进行操作 一. 分析思路 示例: 我们把每一个数都看成是一个字符串,每一个元素为十进制数字所对应的字 符,由于是后面的元素先进行
-
C语言超详细讲解轮转数组
目录 题目描述 实例 解题思路 1. 先整体逆转 2.逆转子数组[0, k - 1] 3.逆转子数组[k, numsSize - 1] 易错点 代码 题目描述 给你一个数组,将数组中的元素向右轮转 k 个位置,其中 k 是非负数.OJ链接 实例 1.实例1 输入: nums = [1,2,3,4,5,6,7], k = 3输出: [5,6,7,1,2,3,4]解释:向右轮转 1 步: [7,1,2,3,4,5,6]向右轮转 2 步: [6,7,1,2,3,4,5]向右轮转 3 步: [5,6,7
-
C语言超详细文件操作基础上篇
目录 一.为什么使用文件 二.什么是文件 1.什么是数据文件 2.什么是程序文件 3.文件名 三.文件的打开和关闭 1文件指针: 2.打开和关闭文件函数 (1)打开文件函数: (2)关闭文件函数 四.文件的顺序读写 1.写文件(fputc,操作一个字符) 2.读文件(fgetc,操作一个字符) 3.写文件(fputs,操作字符串) 4.读文件(fgets,操作字符串) 一.为什么使用文件 为了更好的把信息记录下来,对数据进行持久化的保存,这个时候我们就可以把数据写到文件里面去,使用文件我们可以将
-
C语言 超详细讲解链接器
目录 1 什么是链接器 2 声明与定义 3 命名冲突 3.1 命名冲突 3.2 static修饰符 4 形参.实参.返回值 5 检查外部类型 6 头文件 1 什么是链接器 典型的链接器把由编译器或汇编器生成的若干个目标模块,整合成一个被称为载入模块或可执行文件的实体–该实体能够被操作系统直接执行. 链接器通常把目标模块看成是由一组外部对象组成的.每个外部对象代表着机器内存中的某个部分,并通过一个外部名称来识别.因此,==程序中的每个函数和每个外部变量,如果没有被声明为static,就都是一个外部
-
C语言 超详细讲解库函数
目录 1 返回整数的getchar函数 2 更新顺序文件 3 缓冲输出与内存分配 4 库函数 练习 1 返回整数的getchar函数 代码: #include<stdio.h> int main() { char c; while((c = getchar())!=EOF)//getchar函数的返回值为整型 putchar(c); return 0; } 上述代码有三种可能: 某些合法的输入字符在被"截断"后使得c的取值与EOF相同,程序将在复制的中途停止. c根本不可能