pytorch实现MNIST手写体识别
本文实例为大家分享了pytorch实现MNIST手写体识别的具体代码,供大家参考,具体内容如下
实验环境
pytorch 1.4
Windows 10
python 3.7
cuda 10.1(我笔记本上没有可以使用cuda的显卡)
实验过程
1. 确定我们要加载的库
import torch import torch.nn as nn import torchvision #这里面直接加载MNIST数据的方法 import torchvision.transforms as transforms # 将数据转为Tensor import torch.optim as optim import torch.utils.data.dataloader as dataloader
2. 加载数据
这里使用所有数据进行训练,再使用所有数据进行测试
train_set = torchvision.datasets.MNIST( root='./data', # 文件存储位置 train=True, transform=transforms.ToTensor(), download=True ) train_dataloader = dataloader.DataLoader(dataset=train_set,shuffle=False,batch_size=100)# dataset可以省 ''' dataloader返回(images,labels) 其中, images维度:[batch_size,1,28,28] labels:[batch_size],即图片对应的 ''' test_set = torchvision.datasets.MNIST( root='./data', train=False, transform=transforms.ToTensor(), download=True ) test_dataloader = dataloader.DataLoader(test_set,batch_size=100,shuffle=False) # dataset可以省
3. 定义神经网络模型
这里使用全神经网络作为模型
class NeuralNet(nn.Module): def __init__(self,in_num,h_num,out_num): super(NeuralNet,self).__init__() self.ln1 = nn.Linear(in_num,h_num) self.ln2 = nn.Linear(h_num,out_num) self.relu = nn.ReLU() def forward(self,x): return self.ln2(self.relu(self.ln1(x)))
4. 模型训练
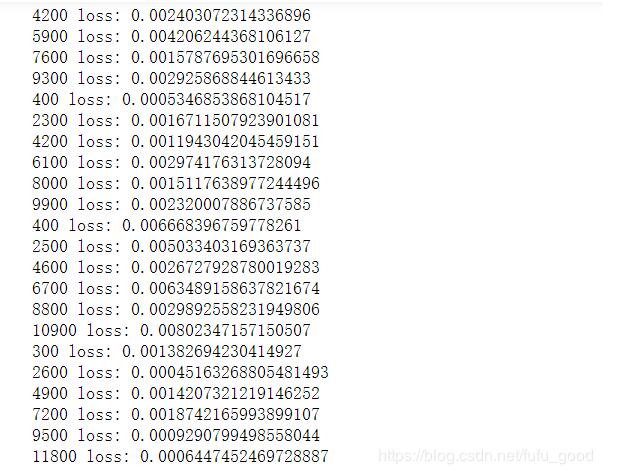
in_num = 784 # 输入维度 h_num = 500 # 隐藏层维度 out_num = 10 # 输出维度 epochs = 30 # 迭代次数 learning_rate = 0.001 USE_CUDA = torch.cuda.is_available() # 定义是否可以使用cuda model = NeuralNet(in_num,h_num,out_num) # 初始化模型 optimizer = optim.Adam(model.parameters(),lr=learning_rate) # 使用Adam loss_fn = nn.CrossEntropyLoss() # 损失函数 for e in range(epochs): for i,data in enumerate(train_dataloader): (images,labels) = data images = images.reshape(-1,28*28) # [batch_size,784] if USE_CUDA: images = images.cuda() # 使用cuda labels = labels.cuda() # 使用cuda y_pred = model(images) # 预测 loss = loss_fn(y_pred,labels) # 计算损失 optimizer.zero_grad() loss.backward() optimizer.step() n = e * i +1 if n % 100 == 0: print(n,'loss:',loss.item())
训练模型的loss部分截图如下:
5. 测试模型
with torch.no_grad():
total = 0
correct = 0
for (images,labels) in test_dataloader:
images = images.reshape(-1,28*28)
if USE_CUDA:
images = images.cuda()
labels = labels.cuda()
result = model(images)
prediction = torch.max(result, 1)[1] # 这里需要有[1],因为它返回了概率还有标签
total += labels.size(0)
correct += (prediction == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct/total))
实验结果
最终实验的正确率达到:98.22%
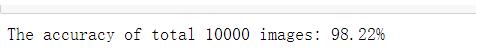
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

手把手教你实现PyTorch的MNIST数据集
概述 MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道 28*28 的灰度图. 获取数据 def get_data(): """获取数据""" # 获取测试集 train = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=torchvision.tran
-
Pytorch实现的手写数字mnist识别功能完整示例
本文实例讲述了Pytorch实现的手写数字mnist识别功能.分享给大家供大家参考,具体如下: import torch import torchvision as tv import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim import argparse # 定义是否使用GPU device = torch.device("cuda" if torch
-
PyTorch CNN实战之MNIST手写数字识别示例
简介 卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的. 卷积神经网络CNN的结构一般包含这几个层: 输入层:用于数据的输入 卷积层:使用卷积核进行特征提取和特征映射 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射 池化层:进行下采样,对特征图稀疏处理,减少数据运算量. 全连接层:通常在CNN的尾部进行重新拟合,减
-
pytorch教程实现mnist手写数字识别代码示例
目录 1.构建网络 2.编写训练代码 3.编写测试代码 4.指导程序train和test 5.完整代码 1.构建网络 nn.Moudle是pytorch官方指定的编写Net模块,在init函数中添加需要使用的层,在foeword中定义网络流向. 下面详细解释各层: conv1层:输入channel = 1 ,输出chanael = 10,滤波器5*5 maxpooling = 2*2 conv2层:输入channel = 10 ,输出chanael = 20,滤波器5*5, dropout ma
-
详解PyTorch手写数字识别(MNIST数据集)
MNIST 手写数字识别是一个比较简单的入门项目,相当于深度学习中的 Hello World,可以让我们快速了解构建神经网络的大致过程.虽然网上的案例比较多,但还是要自己实现一遍.代码采用 PyTorch 1.0 编写并运行. 导入相关库 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, t
-
使用PyTorch实现MNIST手写体识别代码
实验环境 win10 + anaconda + jupyter notebook Pytorch1.1.0 Python3.7 gpu环境(可选) MNIST数据集介绍 MNIST 包括6万张28x28的训练样本,1万张测试样本,可以说是CV里的"Hello Word".本文使用的CNN网络将MNIST数据的识别率提高到了99%.下面我们就开始进行实战. 导入包 import torch import torch.nn as nn import torch.nn.functional
-
pytorch实现MNIST手写体识别
本文实例为大家分享了pytorch实现MNIST手写体识别的具体代码,供大家参考,具体内容如下 实验环境 pytorch 1.4 Windows 10 python 3.7 cuda 10.1(我笔记本上没有可以使用cuda的显卡) 实验过程 1. 确定我们要加载的库 import torch import torch.nn as nn import torchvision #这里面直接加载MNIST数据的方法 import torchvision.transforms as transform
-
Python MNIST手写体识别详解与试练
[人工智能项目]MNIST手写体识别实验及分析 1.实验内容简述 1.1 实验环境 本实验采用的软硬件实验环境如表所示: 在Windows操作系统下,采用基于Tensorflow的Keras的深度学习框架,对MNIST进行训练和测试. 采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络.短期和长期的网络以及更广泛的一般网络.使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层
-
pytorch GAN伪造手写体mnist数据集方式
一,mnist数据集 形如上图的数字手写体就是mnist数据集. 二,GAN原理(生成对抗网络) GAN网络一共由两部分组成:一个是伪造器(Generator,简称G),一个是判别器(Discrimniator,简称D) 一开始,G由服从某几个分布(如高斯分布)的噪音组成,生成的图片不断送给D判断是否正确,直到G生成的图片连D都判断以为是真的.D每一轮除了看过G生成的假图片以外,还要见数据集中的真图片,以前者和后者得到的损失函数值为依据更新D网络中的权值.因此G和D都在不停地更新权值.以下图为例
-
PyTorch实现MNIST数据集手写数字识别详情
目录 一.PyTorch是什么? 二.程序示例 1.引入必要库 2.下载数据集 3.加载数据集 4.搭建CNN模型并实例化 5.交叉熵损失函数损失函数及SGD算法优化器 6.训练函数 7.测试函数 8.运行 三.总结 前言: 本篇文章基于卷积神经网络CNN,使用PyTorch实现MNIST数据集手写数字识别. 一.PyTorch是什么? PyTorch 是一个 Torch7 团队开源的 Python 优先的深度学习框架,提供两个高级功能: 强大的 GPU 加速 Tensor 计算(类似 nump
-
关于Pytorch的MNIST数据集的预处理详解
关于Pytorch的MNIST数据集的预处理详解 MNIST的准确率达到99.7% 用于MNIST的卷积神经网络(CNN)的实现,具有各种技术,例如数据增强,丢失,伪随机化等. 操作系统:ubuntu18.04 显卡:GTX1080ti python版本:2.7(3.7) 网络架构 具有4层的CNN具有以下架构. 输入层:784个节点(MNIST图像大小) 第一卷积层:5x5x32 第一个最大池层 第二卷积层:5x5x64 第二个最大池层 第三个完全连接层:1024个节点 输出层:10个节点(M
-
Python3实现简单可学习的手写体识别(实例讲解)
1.前言 版本:Python3.6.1 + PyQt5 + SQL Server 2012 以前一直觉得,机器学习.手写体识别这种程序都是很高大上很难的,直到偶然看到了这个视频,听了老师讲的思路后,瞬间觉得原来这个并不是那么的难,原来我还是有可能做到的. 于是我开始顺着思路打算用Python.PyQt.SQLServer做一个出来,看看能不能行.然而中间遇到了太多的问题,数据库方面的问题有十几个,PyQt方面的问题有接近一百个,还有数十个Python基础语法的问题.但好在,通过不断的Google
-
python使用KNN算法手写体识别
本文实例为大家分享了用KNN算法手写体识别的具体代码,供大家参考,具体内容如下 #!/usr/bin/python #coding:utf-8 import numpy as np import operator import matplotlib import matplotlib.pyplot as plt import os ''''' KNN算法 1. 计算已知类别数据集中的每个点依次执行与当前点的距离. 2. 按照距离递增排序. 3. 选取与当前点距离最小的k个点 4. 确定前k个点所
-
pytorch 把MNIST数据集转换成图片和txt的方法
本文介绍了pytorch 把MNIST数据集转换成图片和txt的方法,分享给大家,具体如下: 1.下载Mnist 数据集 import os # third-party library import torch import torch.nn as nn from torch.autograd import Variable import torch.utils.data as Data import torchvision import matplotlib.pyplot as plt # t
-
Pytorch使用MNIST数据集实现基础GAN和DCGAN详解
原始生成对抗网络Generative Adversarial Networks GAN包含生成器Generator和判别器Discriminator,数据有真实数据groundtruth,还有需要网络生成的"fake"数据,目的是网络生成的fake数据可以"骗过"判别器,让判别器认不出来,就是让判别器分不清进入的数据是真实数据还是fake数据.总的来说是:判别器区分真实数据和fake数据的能力越强越好:生成器生成的数据骗过判别器的能力越强越好,这个是矛盾的,所以只能