Python ADF 单位根检验 如何查看结果的实现
如下所示:
from statsmodels.tsa.stattools import adfuller
print(adfuller(data))
(-8.14089819118415, 1.028868757881713e-12, 8, 442, {'1%': -3.445231637930579, '5%': -2.8681012763264233, '10%': -2.5702649212751583}, -797.2906467666614)
第一个是adt检验的结果,简称为T值,表示t统计量。
第二个简称为p值,表示t统计量对应的概率值。
第三个表示延迟。
第四个表示测试的次数。
第五个是配合第一个一起看的,是在99%,95%,90%置信区间下的临界的ADF检验的值。
第一点,1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设。本数据中,adf结果为-8, 小于三个level的统计值
第二点,p值要求小于给定的显著水平,p值要小于0.05,等于0是最好的。本数据中,P-value 为 1e-15,接近0.
ADF检验的原假设是存在单位根,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设。
对于ADF结果在1% 以上 5%以下的结果,也不能说不平稳,关键看检验要求是什么样子的。
补充知识:python 编写ADF 检验 ,代码结果参数所表示的含义
我就废话不多说了,大家还是直接看代码吧!
from statsmodels.tsa.stattools import adfuller import numpy as np import pandas as pd adf_seq = np.array([1,2,3,4,5,7,5,1,54,3,6,87,45,14,24]) dftest = adfuller(adf_seq,autolag='AIC') dfoutput = pd.Series(dftest[0:4],index=['Test Statistic','p-value','#Lags Used','Number of Observations Used']) # 第一种显示方式 for key,value in dftest[4].items(): dfoutput['Critical Value (%s)' % key] = value print(dfoutput) # 第二种显示方式 print(dftest)
(1)第一种显示方式如图所示:
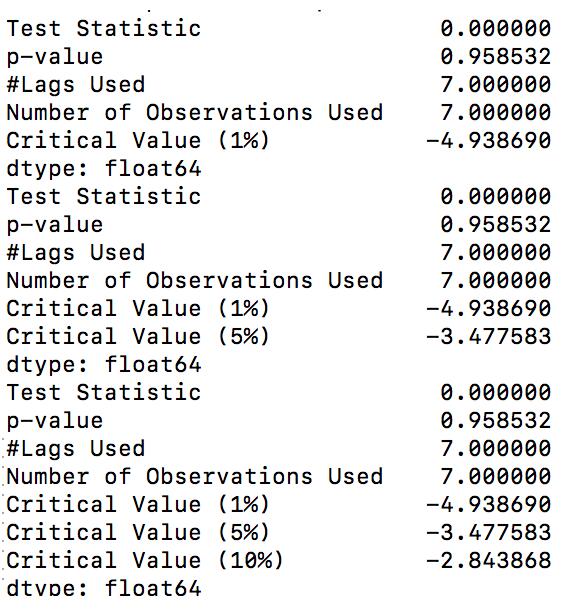
具体的参数含义如下所示:
Test Statistic : T值,表示T统计量
p-value: p值,表示T统计量对应的概率值
Lags Used:表示延迟
Number of Observations Used: 表示测试的次数
Critical Value 1% : 表示t值下小于 - 4.938690 , 则原假设发生的概率小于1%, 其它的数值以此类推。
其中t值和p值是最重要的,其实这两个值是等效的,既可以看t值也可以看p值。
p值越小越好,要求小于给定的显著水平,p值小于0.05,等于0最好。
t值,ADF值要小于t值,1%, 5%, 10% 的三个level,都是一个临界值,如果小于这个临界值,说明拒绝原假设。
其中,1% : 严格拒绝原假设; 5%: 拒绝原假设; 10% 以此类推,程度越来越低。如果,ADF小于1% level, 说明严格拒绝原假设。
(2)第二种表示方式,如下图所示:
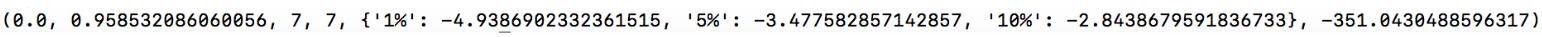
第一个值(0.0): 表示Test Statistic , 即T值,表示T统计量
第二个值(0.958532086060056):p-value,即p值,表示T统计量对应的概率值
第三个值(7):Lags Used,即表示延迟
第四个值(7):Number of Observations Used,即表示测试的次数
大括号中的值,分别表示1%, 5%, 10% 的三个level
查阅了资料,简单的做的总结经验。
以上这篇Python ADF 单位根检验 如何查看结果的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python数据正态性检验实现过程
在做数据分析或者统计的时候,经常需要进行数据正态性的检验,因为很多假设都是基于正态分布的基础之上的,例如:T检验. 在Python中,主要有以下检验正态性的方法: 1.scipy.stats.shapiro --Shapiro-Wilk test,属于专门用来做正态性检验的模块,其原假设:样本数据符合正态分布. 注:适用于小样本. 其函数定位为: def shapiro(x): """ Perform the Shapiro-Wilk test for normality.
-
python 线性回归分析模型检验标准--拟合优度详解
建立完回归模型后,还需要验证咱们建立的模型是否合适,换句话说,就是咱们建立的模型是否真的能代表现有的因变量与自变量关系,这个验证标准一般就选用拟合优度. 拟合优度是指回归方程对观测值的拟合程度.度量拟合优度的统计量是判定系数R^2.R^2的取值范围是[0,1].R^2的值越接近1,说明回归方程对观测值的拟合程度越好:反之,R^2的值越接近0,说明回归方程对观测值的拟合程度越差. 拟合优度问题目前还没有找到统一的标准说大于多少就代表模型准确,一般默认大于0.8即可 拟合优度的公式:R^2 = 1
-
Python实现K折交叉验证法的方法步骤
学习器在测试集上的误差我们通常称作"泛化误差".要想得到"泛化误差"首先得将数据集划分为训练集和测试集.那么怎么划分呢?常用的方法有两种,k折交叉验证法和自助法.介绍这两种方法的资料有很多.下面是k折交叉验证法的python实现. ##一个简单的2折交叉验证 from sklearn.model_selection import KFold import numpy as np X=np.array([[1,2],[3,4],[1,3],[3,5]]) Y=np.a
-
Python素数检测的方法
本文实例讲述了Python素数检测的方法.分享给大家供大家参考.具体如下: 因子检测: 检测因子,时间复杂度O(n^(1/2)) def is_prime(n): if n < 2: return False for i in xrange(2, int(n**0.5+1)): if n%i == 0: return False return True 费马小定理: 如果n是一个素数,a是小于n的任意正整数,那么a的n次方与a模n同余 实现方法: 选择一个底数(例如2),对于大整数p,如果2^(
-
Python ADF 单位根检验 如何查看结果的实现
如下所示: from statsmodels.tsa.stattools import adfuller print(adfuller(data)) (-8.14089819118415, 1.028868757881713e-12, 8, 442, {'1%': -3.445231637930579, '5%': -2.8681012763264233, '10%': -2.5702649212751583}, -797.2906467666614) 第一个是adt检验的结果,简称为T值,表示
-

python通过移动端访问查看电脑界面
这篇文章主要介绍了python通过移动端访问查看电脑界面,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 看上心意的小姐姐,想看她平时都浏览什么网页,如何才能看她的桌面呢,都说Python很厉害,这次我们做一个利用移动端访问电脑来查看电脑的界面的神器!不知道大家以前有没有做过这方面的东西呢?也许大家听起来还有点不太理解,没有关系,下面小编就带领大家来看一下这个炫酷的操作,程序运行的结果如下图所示. 上图是程序执行的图片,而下图是在手机端访问电脑时
-
python中的错误如何查看
python常见的错误有 1.NameError变量名错误 2.IndentationError代码缩进错误 3.AttributeError对象属性错误 4.TypeError类型错误 5.IOError输入输出错误 6.KeyError字典键值错误 具体介绍 1.NameError变量名错误 报错: >>> print a Traceback (most recent call last): File "<stdin>", line 1, in <
-
Python实现 MK检验示例代码
MK检验:时间序列进行检测,并找出突变点,本文参考网上的matlab程序改写为python代码如下: import numpy as np import pandas as pd import matplotlib.pyplot as plt #读取时间序列数据 data = pd.read_csv('') #定义时间和径流数据列 x = list(range(len(data))) y = data.to_list #获取样本数据 n = len(y) #正序计算 #定义累计量序列Sk,长度n
-
Python+PyQt5制作一个图片查看器
目录 前言 实现方式 测试 前言 在 PyQt 中可以使用很多方式实现照片查看器,最朴素的做法就是重写 QWidget 的 paintEvent().mouseMoveEvent 等事件,但是如果要在图像上多添加一些形状,那么在对图像进行缩放旋转等仿射变换时需要对这些形状也这些变换,虽然不难,但是从头实现这些变换还有形状还是挺讨厌的.好在 Qt 提供了图形视图框架,关于这个框架的基本使用可以参见 深入了解PyQt5中的图形视图框架,下面进入正题. 实现方式 一个最基本的照片查看器应该具有以下功能
-
python实现文件助手中查看微信撤回消息
利用python实现防撤回,对方撤回的消息可在自己的微信文件传输助手中查看. 如果想变成可执行文件放在电脑中运行,可用pyinstaller将此程序打包成exe文件. pyinstaller 文件名.py -F 执行程序后,消息防撤回就启动了. 程序完整代码 # -*-encoding:utf-8-*- import os import re import shutil import time import itchat from itchat.content import * # 说明:可以撤
-
help函数解决python所有文档信息查看
目录 引言 1.模块文档查看 2.模块.函数文档查看 3.公共函数文档查看 引言 在python中的交互式命令行中提供了help函数来查询各个模块,或是公共函数,或是模块下的函数接口等都可以使用help函数来查看接口文档. 不过要查看这样的文档还是得有些英文功底的,包含函数.模块.变量的介绍都是通过英文来介绍的. 1.模块文档查看 打开控制台,这里使用的控制台工具是cmder,看起来比默认的cmd命令行好看的多. 比如说需要查看pandas模块的接口文档,可以使用help("pandas&quo
-
Python如何使用type()函数查看数据的类型
目录 使用type()查看数据的类型 使用type来定义类 我们先来看一张图 仔细观察 我们上代码测试一下 使用type()查看数据的类型 在Python中, 可以使用type()类型来查看数据的类型: >>> type(3) <class 'int'> >>> type("123") <class 'str'> >>> type(True) <class 'bool'> >>>
-
使用python实现时间序列白噪声检验方式
白噪声检验也称为纯随机性检验, 当数据是纯随机数据时,再对数据进行分析就没有任何意义了, 所以拿到数据后最好对数据进行一个纯随机性检验 acorr_ljungbox(x, lags=None, boxpierce=False) # 数据的纯随机性检验函数 lags为延迟期数,如果为整数,则是包含在内的延迟期数,如果是一个列表或数组,那么所有时滞都包含在列表中最大的时滞中 boxpierce为True时表示除开返回LB统计量还会返回Box和Pierce的Q统计量 返回值: lbvalue:测试的统
-
Python如何查看两个数据库的同名表的字段名差异
目录 查看两个数据库的同名表的字段名差异 问题描述 解决方案 mysql-utilities Python数据库之间差异对比 查看两个数据库的同名表的字段名差异 问题描述 开发过程中有多个测试环境,测试环境 A 加了字段,测试环境 B 忘了加,字段名对不上,同一项目就报错了 CREATE DATABASE `a` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; CREATE DATABASE `b` CHARACTER SET 'utf8' COL