创建SparkSession和sparkSQL的详细过程
目录
- 一、概述
- 二、创建SparkSession
- 三、 SQLContext
- 四、 HiveContext
一、概述
spark 有三大引擎,spark core、sparkSQL、sparkStreaming,
spark core 的关键抽象是 SparkContext、RDD;
SparkSQL 的关键抽象是 SparkSession、DataFrame;
sparkStreaming 的关键抽象是 StreamingContext、DStream
SparkSession 是 spark2.0 引入的概念,主要用在 sparkSQL 中,当然也可以用在其他场合,他可以代替 SparkContext;
SparkSession 其实是封装了 SQLContext 和 HiveContext
(1) 在Spark1.6 中我们使用的叫Hive on spark,主要是依赖hive生成spark程序,有两个核心组件SQLcontext和HiveContext。
这是Spark 1.x 版本的语法
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
(2)Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6 中的SQLcontext和HiveContext 来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。
在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
二、创建SparkSession
SparkSession 是 Spark SQL 的入口。使用 Dataset 或者 Dataframe 编写 Spark SQL 应用的时候,第一个要创建的对象就是 SparkSession。Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置,并通过 stop 函数来停止 SparkSession。
Builder 的方法如下:
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder
.appName("My Spark Application") //设置 application 的名字
.master("local[*]")
.enableHiveSupport() //增加支持 hive Support
.config("spark.sql.warehouse.dir", "target/spark-warehouse") //设置各种配置
.getOrCreate //获取或者新建一个 sparkSession
(1)设置参数
创建SparkSession之后可以通过 spark.conf.set 来设置运行参数
//配置设置
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//获取配置,可以使用Scala的迭代器来读取configMap中的数据。
val configMap:Map[String, String] = spark.conf.getAll()
(2)读取元数据
如果需要读取元数据(catalog),可以通过SparkSession来获取。
spark.catalog.listTables.show(false) spark.catalog.listDatabases.show(false)
这里返回的都是Dataset,所以可以根据需要再使用Dataset API来读取
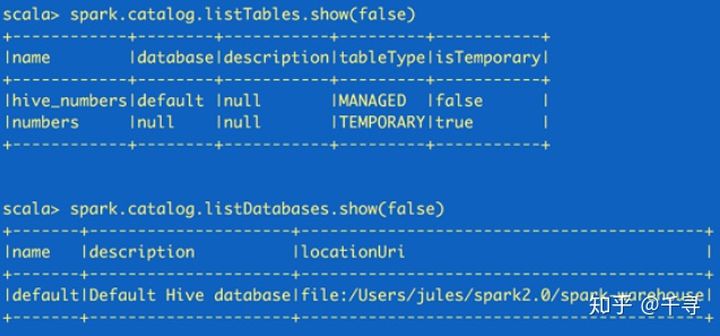
catalog 和 schema 是两个不同的概念
Catalog是目录的意思,从数据库方向说,相当于就是所有数据库的集合;
Schema是模式的意思, 从数据库方向说, 类似Catelog下的某一个数据库;
(3)创建Dataset和Dataframe
通过SparkSession来创建Dataset和Dataframe有多种方法。
通过range()方法来创建dataset
通过createDataFrame()来创建dataframe。
// create a Dataset using spark.range starting from 5 to 100,
// with increments of 5
val numDS = spark.range(5, 100, 5)//创建dataset
// reverse the order and display first 5 items
numDS.orderBy(desc("id")).show(5)
//compute descriptive stats and display them
numDs.describe().show()
// create a DataFrame using spark.createDataFrame from a List or Seq
val langPercentDF = spark.createDataFrame( List( ("Scala", 35),
("Python", 30), ("R", 15), ("Java", 20)) )//创建dataframe
//rename the columns
val lpDF = langPercentDF.withColumnRenamed("_1", "language").
withColumnRenamed("_2", "percent")
//order the DataFrame in descending order of percentage
lpDF.orderBy(desc("percent")).show(false)

(4)读取数据
可以用SparkSession读取JSON、CSV、TXT 和 parquet表。
import spark.implicits //使RDD转化为DataFrame以及后续SQL操作 //读取JSON文件,生成DataFrame val jsonFile = args(0) val zipsDF = spark.read.json(jsonFile)
(5)使用SparkSQL
借助SparkSession用户可以像SQLContext一样使用Spark SQL的全部功能。
zipsDF.createOrReplaceTempView("zips_table")//对上面的dataframe创建一个表
zipsDF.cache()//缓存表
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table")
//对表调用SQL语句
resultsDF.show(10)//展示结果
(6)存储/读取Hive表
下面的代码演示了通过SparkSession来创建Hive表并进行查询的方法。
//drop the table if exists to get around existing table error
spark.sql("DROP TABLE IF EXISTS zips_hive_table")
//save as a hive table
spark.table("zips_table").write.saveAsTable("zips_hive_table")
//make a similar query against the hive table
val resultsHiveDF = spark.sql("SELECT city, pop, state,
zip FROM zips_hive_table WHERE pop > 40000")
resultsHiveDF.show(10)
三、 SQLContext
它是 sparkSQL 的入口点,sparkSQL 的应用必须创建一个 SQLContext 或者 HiveContext 的类实例
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, SQLContext, HiveContext
conf = SparkConf().setAppName('test').setMaster('yarn')
sc = SparkContext(conf=conf)
sqlc = SQLContext(sc)
print(dir(sqlc))
# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream',
# 'registerDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable'
### sqlcontext 读取数据也自动生成 df
data = sqlc.read.text('/usr/yanshw/test.txt')
print(type(data))
四、 HiveContext
它是 sparkSQL 的另一个入口点,它继承自 SQLContext,用于处理 hive 中的数据
HiveContext 对 SQLContext 进行了扩展,功能要强大的多
1. 它可以执行 HiveSQL 和 SQL 查询
2. 它可以操作 hive 数据,并且可以访问 HiveUDF
3. 它不一定需要 hive,在没有 hive 环境时也可以使用 HiveContext
注意,如果要处理 hive 数据,需要把 hive 的 hive-site.xml 文件放到 spark/conf 下,HiveContext 将从 hive-site.xml 中获取 hive 配置信息;
如果 HiveContext 没有找到 hive-site.xml,他会在当前目录下创建 spark-warehouse 和 metastore_db 两个文件夹
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, SQLContext, HiveContext
conf = SparkConf().setAppName('test').setMaster('yarn')
sc = SparkContext(conf=conf)
## 需要把 hive/conf/hive-site.xml 复制到 spark/conf 下
hivec = HiveContext(sc)
print(dir(hivec))
# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream','refreshTable',
# 'registerDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable'
data = hivec.sql('''select * from hive1101.person limit 2''')
print(type(data))
SparkSession 创建
from pyspark.sql import SparkSession
### method 1
sess = SparkSession.builder \
.appName("aaa") \
.config("spark.driver.extraClassPath", sparkClassPath) \
.master("local") \
.enableHiveSupport() \ # sparkSQL 连接 hive 时需要这句
.getOrCreate() # builder 方式必须有这句
### method 2
conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 master
sess = SparkSession.builder.config(conf=conf).getOrCreate() # builder 方式必须有这句
### method 3
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 master
sc = SparkContext(conf=conf)
sess = SparkSession(sc)
1)文件数据源
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, SQLContext, HiveContext
conf = SparkConf().setAppName('test').setMaster('yarn')
sc = SparkContext(conf=conf)
#### 替代了 SQLContext 和 HiveContext,其实只是简单的封装,提供了统一的接口
spark = SparkSession(sc)
print(dir(spark))
# 很多属性,我把私有属性删了
# 'Builder','builder', 'catalog', 'conf', 'createDataFrame', 'newSession', 'range', 'read', 'readStream','sparkContext', 'sql', 'stop', 'streams', 'table', 'udf', 'version'
### sess 读取数据自动生成 df
data = spark.read.text('/usr/yanshw/test.txt') #read 可读类型 [ 'csv', 'format', 'jdbc', 'json', 'load', 'option', 'options', 'orc', 'parquet', 'schema', 'table', 'text']
print(type(data)) # <class 'pyspark.sql.dataframe.DataFrame'>
2) Hive 数据源
## 也需要把 hive/conf/hive-site.xml 复制到 spark/conf 下
spark = SparkSession.builder.appName('test').master('yarn').enableHiveSupport().getOrCreate()
hive_data = spark.sql('select * from hive1101.person limit 2')
print(hive_data) # DataFrame[name: string, idcard: string]
SparkSession vs SparkContext
SparkSession 是 spark2.x 引入的新概念,SparkSession 为用户提供统一的切入点,字面理解是创建会话,或者连接 spark
在 spark1.x 中,SparkContext 是 spark 的主要切入点,由于 RDD 作为主要的 API,我们通过 SparkContext 来创建和操作 RDD,
SparkContext 的问题在于:
1. 不同的应用中,需要使用不同的 context,在 Streaming 中需要使用 StreamingContext,在 sql 中需要使用 sqlContext,在 hive 中需要使用 hiveContext,比较麻烦
2. 随着 DataSet 和 DataFrame API 逐渐成为标准 API,需要为他们创建接入点,即 SparkSession
SparkSession 实际上封装了 SparkContext,另外也封装了 SparkConf、sqlContext,随着版本增加,可能更多,
所以我们尽量使用 SparkSession ,如果发现有些 API 不在 SparkSession 中,也可以通过 SparkSession 拿到 SparkContext 和其他 Context 等
在 shell 操作中,原生创建了 SparkSession,故无需再创建,创建了也不会起作用
在 shell 中,SparkContext 叫 sc,SparkSession 叫 spark。
到此这篇关于SparkSession和sparkSQL的文章就介绍到这了,更多相关SparkSession和sparkSQL内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈DataFrame和SparkSql取值误区
1.DataFrame返回的不是对象. 2.DataFrame查出来的数据返回的是一个dataframe数据集. 3.DataFrame只有遇见Action的算子才能执行 4.SparkSql查出来的数据返回的是一个dataframe数据集. 原始数据 scala> val parquetDF = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet/part-r-00004.gz.parquet") df: or
-

SparkSQl简介及运行原理
目录 一:什么是SparkSQL? (一)SparkSQL简介 (二)SparkSQL运行原理 (三)SparkSQL特点 二:DataFrame (一)什么是DataFrame? 补充:Spark中的RDD.DataFrame和DataSet讲解 (一)Spark中的模块 (二)RDD和DataFrame的区别 三:SparkSession (一)SparkSession简介 (二)SparkSession实质 (三)SparkSession特点 四:通过RDD创建DataFrame (一)通
-
SparkSQL使用快速入门
目录 一.SparkSQL的进化之路 二.认识SparkSQL 2.1 什么是SparkSQL? 2.2 SparkSQL的作用 2.3 运行原理 2.4 特点 2.5 SparkSession 2.6 DataFrames 三.RDD转换成为DataFrame 3.1通过case class创建DataFrames(反射) 3.2通过structType创建DataFrames(编程接口) 3.3通过 json 文件创建DataFrames 四.DataFrame的read和save和save
-
SparkSQL读取hive数据本地idea运行的方法详解
环境准备: hadoop版本:2.6.5 spark版本:2.3.0 hive版本:1.2.2 master主机:192.168.100.201 slave1主机:192.168.100.201 pom.xml依赖如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="
-
DataFrame:通过SparkSql将scala类转为DataFrame的方法
如下所示: import java.text.DecimalFormat import com.alibaba.fastjson.JSON import com.donews.data.AppConfig import com.typesafe.config.ConfigFactory import org.apache.spark.sql.types.{StructField, StructType} import org.apache.spark.sql.{Row, SaveMode, Da
-
IDEA 开发配置SparkSQL及简单使用案例代码
1.添加依赖 在idea项目的pom.xml中添加依赖. <!--spark sql依赖,注意版本号--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> 2.案例代码 package com.
-
创建SparkSession和sparkSQL的详细过程
目录 一.概述 二.创建SparkSession 三. SQLContext 四. HiveContext 一.概述 spark 有三大引擎,spark core.sparkSQL.sparkStreaming, spark core 的关键抽象是 SparkContext.RDD: SparkSQL 的关键抽象是 SparkSession.DataFrame: sparkStreaming 的关键抽象是 StreamingContext.DStream SparkSession 是 spark
-
脚手架(vue-cli)创建Vue项目的超详细过程记录
目录 cli3.x/4.x创建Vue项目 1.创建项目 2.项目手动配置 3.选择vue版本 4.路由模式 5.配置文件的存放位置 6.配置保存 项目创建成功 总结 cli3.x/4.x创建Vue项目 1.创建项目 vue create vue_project(项目名) 敲击回车,出现以下页面 此处本人一般选择手动配置,因为eslint真的是个很可怕的东西,它对代码格式的严格要求,真的会把人逼疯的,代码有一点点不规范的地方程序都会报错 2.项目手动配置 按空格键选择或取消选择 3.选择vue版本
-
Docker 创建容器后再修改 hostname的详细过程
世上是有后悔药的,只要肯琢磨!再也不用重新创建容器了! 我有一个叫m2的容器,现在想要修改它的 hostname 1.查看容器配置文件在宿主机上的位置,这里看到是 /var/lib/docker/containers/67e012c02434168aff3762ab4edf7550f0bfe1db57b396ce78660f140dd3056e 2.关闭容器.关闭 docker 服务 前提条件,非常重要!!!前提条件,非常重要!!!前提条件,非常重要!!! 3.进入该容器所在配置文件所在宿主机文
-
详解mongoDB主从复制搭建详细过程
详解mongoDB主从复制搭建详细过程 实验目的搭建mongoDB主从复制 主 192.168.0.4 从 192.168.0.7 mongodb的安装 1: 下载mongodb www.mongodb.org 下载最新的stable版 查看自己服务器 适合哪个种方式下载(wget 不可以的 可以用下面方式下载) wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-3.0.5.tgz curl -O -L https
-
springboot+idea+maven 多模块项目搭建的详细过程(连接数据库进行测试)
创建之前项目之前 记得改一下 maven 提高下载Pom速度 记得 setting 中要改 maven 改成 阿里云的.具体方法 网上查第一步 搭建parents 项目,为maven项目 ,不为springboot 项目 记得修改groupId 第二步 搭建多个子模块, honor-dao honor-manager honor-common记得创建 honor-manager 的时候 要把他的gruopId 改成com.honor.manager 这里爆红的原因是 因为 我做到后面
-
IDEA创建Maven工程Servlet的详细教程
IDEA创建Maven工程servlet Servlet(Servlet Applet),全称Java Servlert,用于开发动态web资源的技术.是用Java编写的服务器端程序,主要功能在于处理服务器请求. Tomcat:由Apache组织提供的一种Web服务器,提供对jsp和Servlet的支持.它是一种轻量级的javaWeb容器(服务器),也是当前应用最广的JavaWeb服务器(免费). jsp:(java server page),java提供的一门开发web网页的技术. web应用
-
postgresql数据库安装部署搭建主从节点的详细过程(业务库)
操作系统 64位CentOS 7 数据库搭建 一 业务数据库搭建 1. 安装 yum源(服务器可访问互联网时用) yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm 2. 安装客户端 yum install postgresql11 –y 3. 安装服务端 yum install postgresql11-serve
-
使用IDEA搭建一个简单的SpringBoot项目超详细过程
一.创建项目 1.File->new->project: 2.选择"Spring Initializr",点击next:(jdk1.8默认即可) 3.完善项目信息,组名可不做修改,项目名可做修改:最终建的项目名为:test,src->main->java下包名会是:com->example->test:点击next: 4.Web下勾选Spring Web Start,(网上创建springboot项目多是勾选Web选项,而较高版本的Springboo
-
vscode 配置java环境并调试运行的详细过程
下载vscode以及安装jdk 度娘一大堆 这里不介绍 jdk最好安装jdk11及以上 vscode扩展插件有关 在vscode扩展插件中安装图示插件包,该包基本覆盖java所需的所有内容 新建一个vscode工程,并添加HelloJava.java文件 public class HelloJava{ public static void main(String[] args) { System.out.println("hello world"); } } PS:文件名要与类名一致
-
C++小游戏tankwar之界面绘制的详细过程
一.前言 闲来无趣,写个C++小游戏 二.新建项目 2.1创建MFC项目 2.2 新建路径 2.3 基于对话框 三.窗口界面绘制 3.1 设置框架 进入资源视图 双击打开IDD_TANKWAR_DIALOG 出现下列界面后删除多余控件 修改Caption为Tankwar 增加缩小最大化按钮 3.2 初始化GDI 进入"TankWar.h",加入以下代码 进入"TankWar.cpp",加入以下代码 GDI初始化完成 3.3 绘制背景 进入TankWarDlg.cpp