Python matplotlib绘制散点图配置(万能模板案例)
目录
- 散点图
- 散点图一行代码显示
- 加颜色的散点图
- 颜色深浅表示数值大小
- 散点图显示颜色和大小
- 自定义图表散点图
- 散点图万能模板
- 其他模板
散点图
散点图是指在 回归分析中,数据点在直角坐标系平面上的 分布图,散点图表示因变量随 自变量而 变化的大致趋势,据此可以选择合适的函数 对数据点进行 拟合。
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。散点图将序列显示为一组点。值由点在 图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
下面给出一个散点图的具体代码案例
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.figure(figsize=(9,5), # (宽度 , 高度) 单位inch
dpi=120, # 清晰度 dot-per-inch
# facecolor='#CCCCCC', # 画布底色
# edgecolor='black',linewidth=0.2,frameon=True, # 画布边框
#frameon=False # 不要画布边框
)
# 设置全局中文字体
plt.rcParams['font.sans-serif'] = 'KaiTi' # 设置全局字体为中文 楷体
plt.rcParams['axes.unicode_minus'] = False # 不使用中文减号
#读取数据
crime=pd.read_csv("crimeRatesByState2005.csv")
print (list(crime.murder))#转化成列表
#删除state为United States的数据
crime2 = crime[crime.state != "United States"]
#删除state为District of Columbia的数据
crime2 = crime2[crime2.state != "District of Columbia" ]
z = list(crime2.population/10000)#取人口数据
#colors = np.random.rand(len(list(crime2.murder)))#根据谋杀率随机去颜色
cm = plt.cm.get_cmap('RdYlBu')#使用色谱RdYlBu
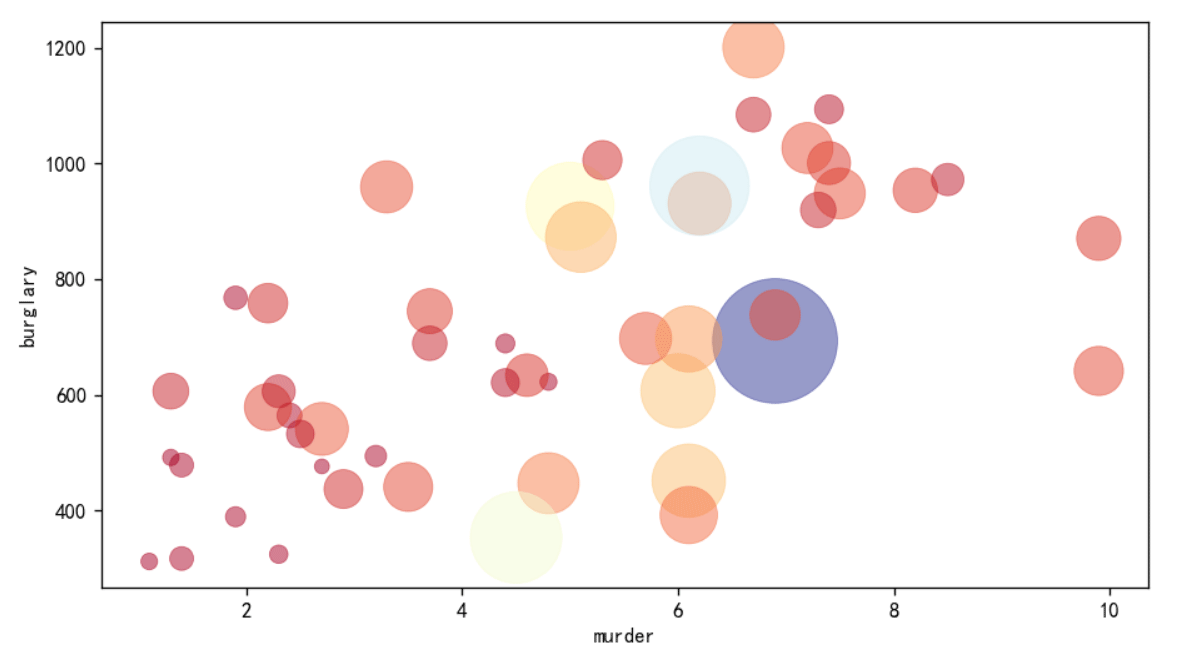
plt.scatter(list(crime2.murder), list(crime2.burglary), s=z,c=z,cmap = cm, linewidth = 0.5, alpha = 0.5)#绘制散点图
plt.xlabel("murder")
plt.ylabel("burglary")
plt.show()
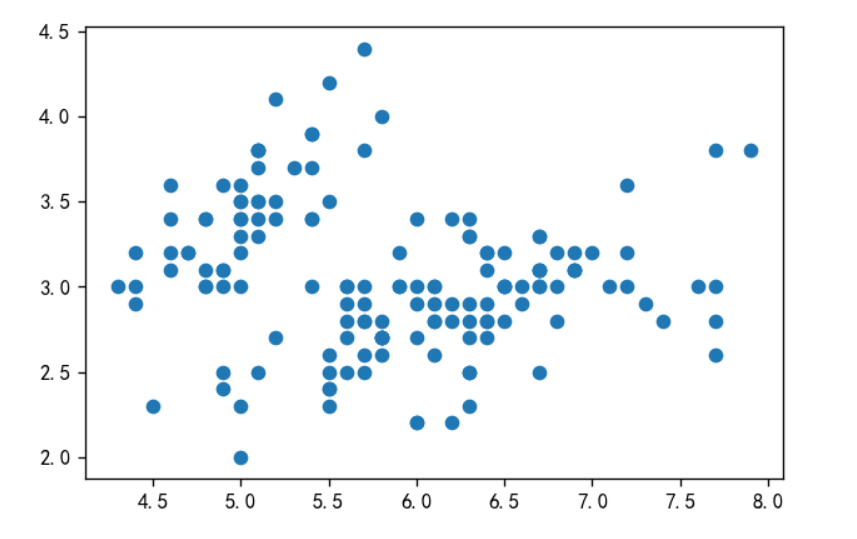
散点图一行代码显示
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
# 根据X,Y值画散点图
plt.scatter(x,y)
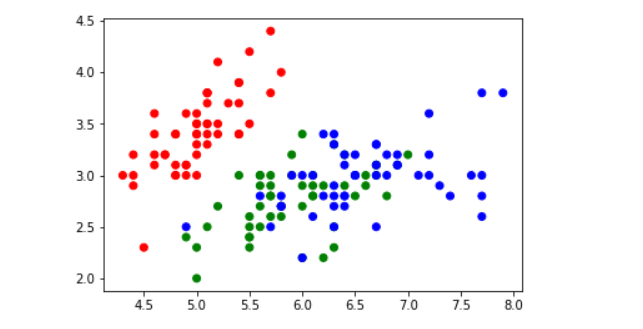
加颜色的散点图
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
c = df['species'].map({'setosa':'r','versicolor':'g','virginica':'b'})
# 根据X,Y值画散点图, 用不同的颜色标识不同的分类
plt.scatter(x,y, c=c)
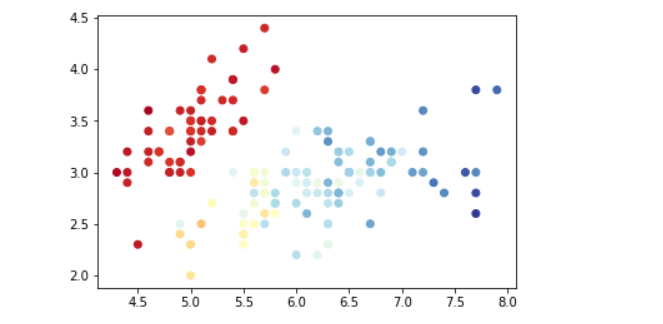
颜色深浅表示数值大小
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
c = df['petal_length']
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度
plt.scatter(x,y, c=c, cmap=plt.cm.RdYlBu)
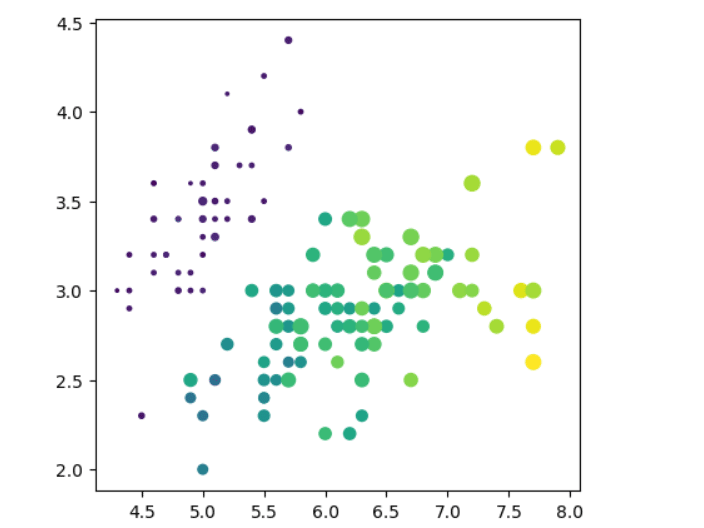
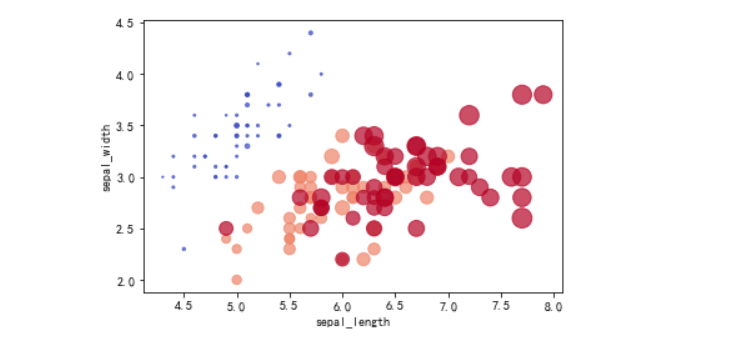
散点图显示颜色和大小
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
plt.scatter(x,y, c=c, s=s*30)
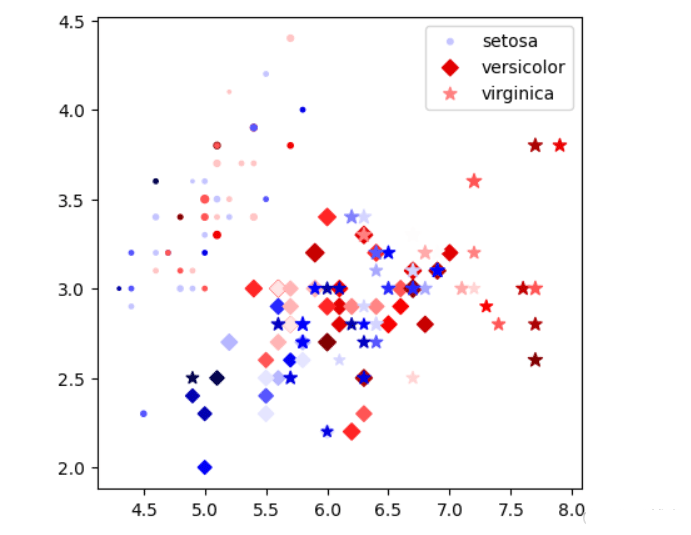
自定义图表散点图
# 读取数据
df = pd.read_csv('iris.csv')
def get_xycs(df):
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
return x,y,c,s
markers = {'setosa':'o', 'versicolor':'D', 'virginica':'*'}
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度, 每组数据只能是一种点样式
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
for sp in df['species'].unique():
x,y,c,s = get_xycs(df[df['species']==sp])
plt.scatter(x,y, c=c, s=s*30, cmap=plt.cm.seismic, marker=markers[sp],label=sp)
plt.legend()
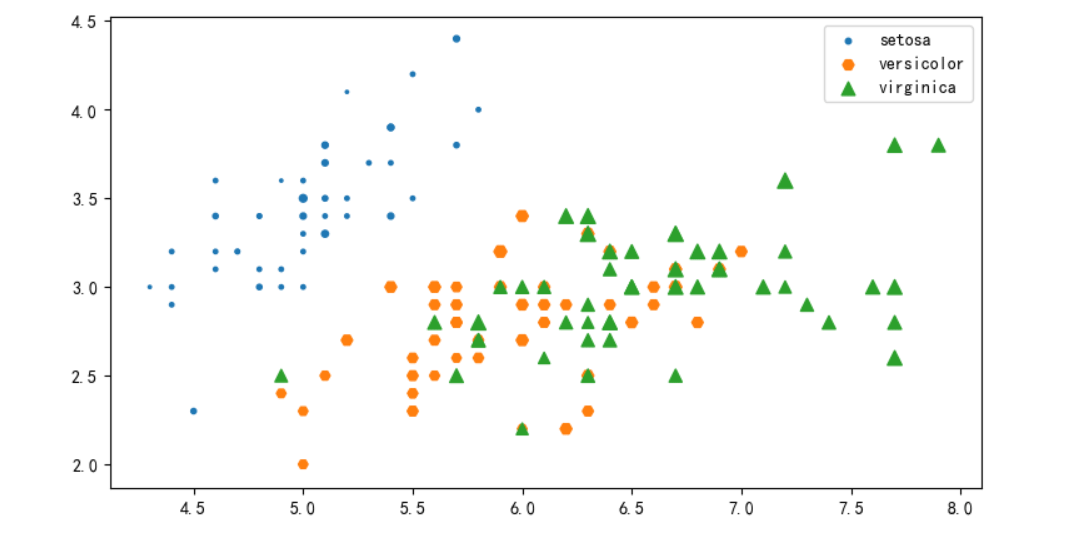
散点图万能模板
# 读取数据
df = pd.read_csv('iris.csv')
def get_xycs(df):
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
return x,y,c,s
markers = {'setosa':'o', 'versicolor':'D', 'virginica':'*'}
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度, 每组数据只能是一种点样式
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
for sp in df['species'].unique():
x,y,c,s = get_xycs(df[df['species']==sp])
plt.scatter(x,y, s=s*30, cmap=plt.cm.seismic, marker=markers[sp],label=sp)
plt.legend()
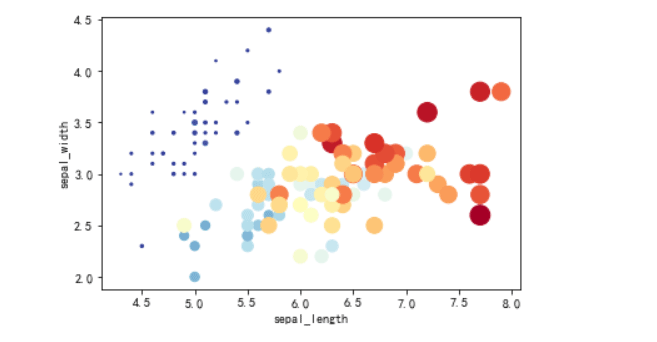
其他模板
### 在二维坐标系上,位置表示(x,y)二维数据
x = df.sepal_length # x 表示花瓣长
y = df.sepal_width # y 表示花瓣宽
s = (df.petal_length * df.petal_width)*np.pi # s(size) 表示花萼面积
c = (df.petal_length * df.petal_width)*np.pi
plt.scatter(x,y,s=s*5, c=c,cmap=plt.cm.RdYlBu_r)
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')
# 在二维坐标系上,位置表示(x,y)二维数据
x = df.sepal_length # x 表示花瓣长
y = df.sepal_width # y 表示花瓣宽
s = (df.petal_length * df.petal_width)*np.pi # s(size) 表示花萼面积
#print(df.species)
#colormap = {"setosa":"#FF0000", "versicolor":"green", "virginica":"b"} # 定义一个字典将species字符串映射到颜色字符串上
colormap = {"setosa":1, "versicolor":5, "virginica":6} # 定义一个字典将species字符串映射到颜色字符串上
c = df.species.map(colormap)
#print(c)
plt.scatter(x,y,s=s*5, c=c,cmap=plt.cm.coolwarm, alpha=0.7, edgecolors='face')
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')
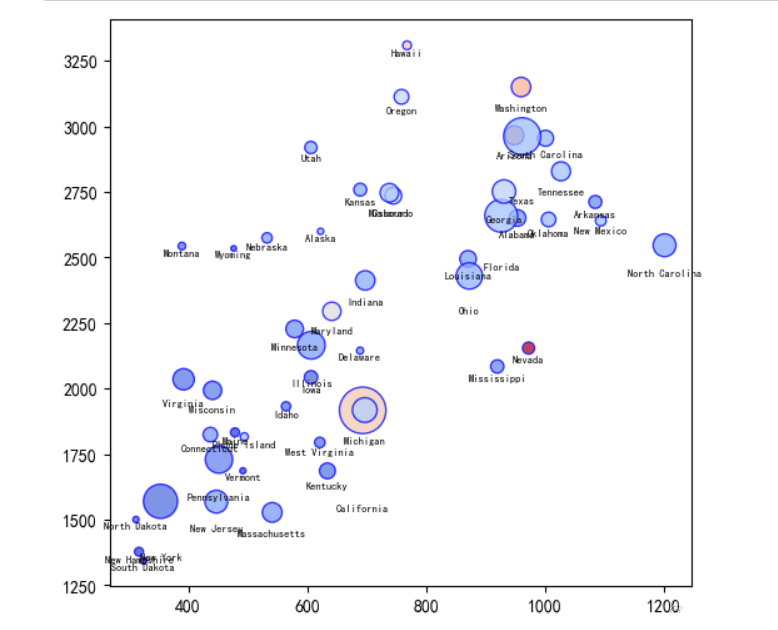
plt.scatter(df['burglary'], df['larceny_theft'], s=df['population']*2e-5, c=df['motor_vehicle_theft'], cmap=plt.cm.coolwarm, edgecolors='b', alpha=0.75) for idx,statename in df['state'].items(): plt.text(x=df['burglary'][idx],y=df['larceny_theft'][idx]-df['population'][idx]*2e-5*0.5,s=statename,fontsize=6,ha='center',va='top')
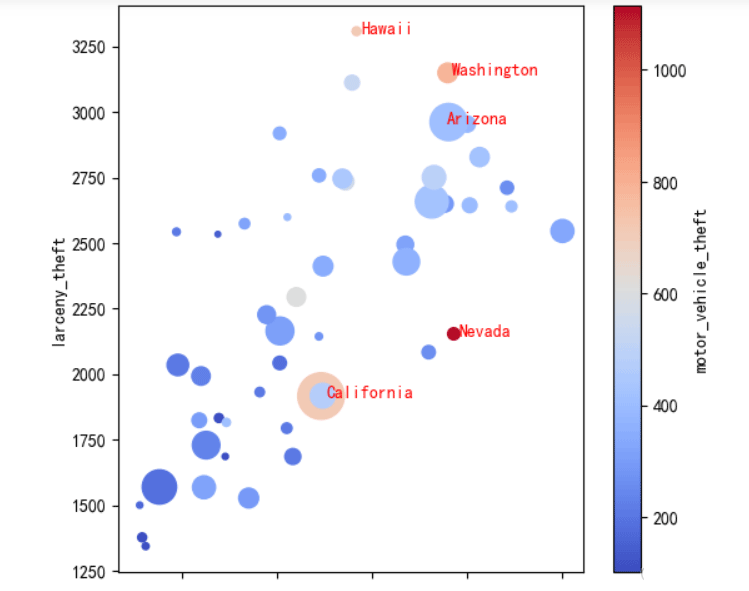
df.plot.scatter(x='burglary',y='larceny_theft',c='motor_vehicle_theft',cmap=plt.cm.coolwarm,s=df['population']*2e-5) for i in df.index: if i in top5_motor_theft_index: # 偷车贼最多的5个州 plt.text(df.loc[i,'burglary']+10, df.loc[i,'larceny_theft']-10, df.loc[i,'state'], color='red') # 一个文本框
到此这篇关于Python matplotlib绘制散点图配置(万能模板案例)的文章就介绍到这了,更多相关python matplotlib绘制散点图 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python matplotlib 绘制散点图详解建议收藏
目录 前言 1. 散点图概述 什么是散点图? 散点图使用场景 绘制散点图步骤 案例展示 2. 散点图属性 设置散点大小 设置散点颜色 设置散点样式 设置透明度 设置散点边框 3. 添加折线散点图 4. 多类型散点图 5. 颜色条散点图 6. 曲线散点图 总结 前言 我们在matplotlib模块学习中,发现有常用的反映数据变化的折线图,对比数据类型差异的柱状图和反应数据频率分布情况的直方图. 其实在数据统计图表中,有一种图表是散列点分布在坐标中,反应数据随着自变量变化的趋势. 本期,我们将详细
-
Python matplotlib实现散点图的绘制
目录 一.整理数据 二.修改点的样式 三.呈现半透明的状态 四.点呈现多彩的颜色 五.让点的大小不一 六.侧边呈现颜色卡 七.改变集中性 一.整理数据 import pandas as pd cnbodf=pd.read_excel('cnboo1.xlsx') cnbodfsort=cnbodf.sort_values(by=['BO'],ascending=False) def mkpoints(x,y): return len(str(x))*(y/25)-3 cnbodfsort['po
-
Python+matplotlib绘制不同大小和颜色散点图实例
具有不同标记颜色和大小的散点图演示. 演示结果: 实现代码: import numpy as np import matplotlib.pyplot as plt import matplotlib.cbook as cbook # Load a numpy record array from yahoo csv data with fields date, open, close, # volume, adj_close from the mpl-data/example directory
-
Python Matplotlib实现三维数据的散点图绘制
一.背景 近期项目即将开展,计划第一步就是实现数据的可视化,所以先学习一下数据展示相关Demo.选用Python2.7与Matplotlib来实现,平台采用Pycharm,值得一提的是,Matplotlib的安装前首先要安装Numpy包,但是在完成Numpy的安装之后,楼主不能在PyCharm平台下进行自动安装,或者CMD中使用类似pip install Matplotlib,参考网上解决方案后采用直接去官网下载相应的安装包直接运行安装到相关目录下.在此就不赘述了. 二. 参考 Python语言
-
Python matplotlib绘制散点图的实例代码
前言 前面说到的主要是matplotlib对于图像的基础操作,然后从这篇开始,主要说一下点图,分析点图在实际问题的数据处理中应用非常广泛,比如说逻辑回归是利用现有的数据点通过拟合得到一定的函数关系,甚至生活中,物体运动的轨迹,也可以看做是连续的点绘制而成,还有图像,也是很多个像素点堆砌而成的,在图像处理中经常会针对单个像素点进行处理. 现在的深度学习或者机器学习,模型都是固定的,大多 不需要怎么改动,而能提升训练效果的,最重要的就是能更好的处理数据,而很多数据本身就是点集,利用matplotli
-
Python利用matplotlib绘制散点图的新手教程
前言 上篇文章介绍了使用matplotlib绘制折线图,参考:https://www.jb51.net/article/198991.htm,本篇文章继续介绍使用matplotlib绘制散点图. 一.matplotlib绘制散点图 # coding=utf-8 import matplotlib.pyplot as plt years = [2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019] turnovers =
-
Python中Matplotlib的点、线形状、颜色以及绘制散点图
目录 常用颜色: 常用标记点形状: 常用线形: 绘制散点图 补充:Python散点图教程 总结 我们在Python中经常使用会用到matplotlib画图,有些曲线和点的形状.颜色信息长时间不用就忘了,整理一下便于查找. 安装matplotlib后可以查看官方说明(太长不贴出来了) from matplotlib import pyplot as plt help(plt.plot) 常用颜色: 'b' 蓝色'g' 绿色'r' 红色'c'
-
Python数据分析之 Matplotlib 散点图绘制
前言: 散点图,又称散点分布图,是使用多个坐标点的分布反映数据点分布规律.数据关联关系的图表,Matplotlib 中可以通过以下方式绘制散点图: 使用plt.plot方法: 在上篇文章Python数据分析之 Matplotlib 折线图绘制中,我们介绍了可以使用plt.plot()方法绘制折线图,该方法同样可以绘制散点图,如下: import random x = range(15) y = [i + random.randint(-2,2) for i in x] plt.plot(x, y
-
Python matplotlib绘制散点图配置(万能模板案例)
目录 散点图 散点图一行代码显示 加颜色的散点图 颜色深浅表示数值大小 散点图显示颜色和大小 自定义图表散点图 散点图万能模板 其他模板 散点图 散点图是指在 回归分析中,数据点在直角坐标系平面上的 分布图,散点图表示因变量随 自变量而 变化的大致趋势,据此可以选择合适的函数 对数据点进行 拟合. 用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式.散点图将序列显示为一组点.值由点在 图表中的位置表示.类别由图表中的不同标记表示.散点图通常用于比较跨
-
matplotlib绘制直方图的基本配置(万能模板案例)
目录 直方图介绍 绘制直方图的参数(plt.hist()) 连接数据库进行直方图绘制案例 使用dataframe里面的plot函数进行绘制(万能模板) 绘制多个子图(多子图直方图案例模板) 概率分布直方图(统计图形) 直方图内显示折线图分布 堆叠面积直方图 在不同的子图中绘制各种类犯罪数据的数值分布 其他案例 乘客年龄分布频数直方图 男女乘客直方图(二维数据) 电影时长分布直方图 直方图介绍 直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据
-
matplotlib绘制折线图的基本配置(万能模板案例)
前面我们已经构造了一种图形可视化的模板了,下面我们直接使用这个模板进行增添和修改,进一步的改善图形的外观. import matplotlib.pyplot as plt # 画布 plt.figure(figsize=(9,3), # (宽度 , 高度) 单位inch dpi=100, # 清晰度 dot-per-inch facecolor='#CCCCCC', # 画布底色 edgecolor='black',linewidth=0.2,frameon=True, # 画布边框 #fram
-
matplotlib绘制饼图的基本配置(万能模板案例)
目录 饼图的概念 连接数据库绘制饼图案例(pandas画图) 显示百分比 饼图常见参数 扇区分离饼图 添加颜色 添加阴影 显示百分比 控制起始角度 将饼图放置在坐标轴 双饼图显示 饼图万能模板 饼图的概念 饼图英文学名为Sector Graph,又名Pie Graph.常用于统计学模块.2D饼图为圆形,手画时,常用圆规作图. 仅排列在工作表的一列或一行中的数据可以绘制到饼图中.饼图显示一个数据系列 (数据系列:在图表中绘制的相关数据点,这些数据源自数据表的行或列.图表中的每个数据系列具有唯一的颜
-
matplotlib绘制雷达图的基本配置(万能模板案例)
目录 介绍 应用场景 案例一(成绩雷达图重叠) 案例二(成绩雷达图左右图) 极坐标 介绍 雷达图是以从同一点开始的轴上表示的三个或更多个定量变量的二维图表的形式显示多变量数据的图形方法.轴的相对位置和角度通常是无信息的. 雷达图也称为网络图,蜘蛛图,星图,蜘蛛网图,不规则多边形,极坐标图或Kiviat图.它相当于平行坐标图,轴径向排列. 应用场景 用于成绩的透视,比如查看你是否偏科,知晓你的兴趣偏向于哪一方面 案例一(成绩雷达图重叠) # coding=utf-8 import numpy as
-
Python matplotlib 绘制散点图详解建议收藏
目录 前言 1. 散点图概述 什么是散点图? 散点图使用场景 绘制散点图步骤 案例展示 2. 散点图属性 设置散点大小 设置散点颜色 设置散点样式 设置透明度 设置散点边框 3. 添加折线散点图 4. 多类型散点图 5. 颜色条散点图 6. 曲线散点图 总结 前言 我们在matplotlib模块学习中,发现有常用的反映数据变化的折线图,对比数据类型差异的柱状图和反应数据频率分布情况的直方图. 往期内容速看 Python用 matplotlib 绘制柱状图 Python matplotlib底层
-
matplotlib绘制甘特图的万能模板案例
目录 定义一个绘制甘特图的类 调用及数据格式 类似于展示的图形 定义一个绘制甘特图的类 # -*- coding: utf-8 -*- from datetime import datetime import sys import numpy as np import matplotlib.pyplot as plt import matplotlib.font_manager as font_manager import matplotlib.dates as mdates import lo