pyspark自定义UDAF函数调用报错问题解决
目录
- 问题场景:
- 问题描述
- 原因分析及解决方案:
问题场景:
在SparkSQL中,因为需要用到自定义的UDAF函数,所以用pyspark自定义了一个,但是遇到了一个问题,就是自定义的UDAF函数一直报
AttributeError: 'NoneType' object has no attribute '_jvm'
在此将解决过程记录下来
问题描述
在新建的py文件中,先自定义了一个UDAF函数,然后在 if __name__ == '__main__': 中调用,死活跑不起来,一遍又一遍的对源码,看起来自定义的函数也没错:过程如下:
import decimal
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
@F.pandas_udf('decimal(17,12)')
def udaf_lx(qx: pd.Series, lx: pd.Series) -> decimal:
# 初始值 也一定是decimal类型
tmp_qx = decimal.Decimal(0)
tmp_lx = decimal.Decimal(0)
for index in range(0, qx.size):
if index == 0:
tmp_qx = decimal.Decimal(qx[index])
tmp_lx = decimal.Decimal(lx[index])
else:
# 计算lx: 计算后,保证数据小数位为12位,与返回类型的设置小数位保持一致
tmp_lx = (tmp_lx * (1 - tmp_qx)).quantize(decimal.Decimal('0.000000000000'))
tmp_qx = decimal.Decimal(qx[index])
return tmp_lx
if __name__ == '__main__':
# 1) 创建 SparkSession 对象,此对象连接 hive
spark = SparkSession.builder.master('local[*]') \
.appName('insurance_main') \
.config('spark.sql.shuffle.partitions', 4) \
.config('spark.sql.warehouse.dir', 'hdfs://node1:8020/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://node1:9083') \
.enableHiveSupport() \
.getOrCreate()
# 注册UDAF 支持在SQL中使用
spark.udf.register('udaf_lx', udaf_lx)
# 2) 编写SQL 执行
excuteSQLFile(spark, '_04_insurance_dw_prem_std.sql')
然后跑起来就报了以下错误:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 835, in _parse_datatype_string
return from_ddl_datatype(s)
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 827, in from_ddl_datatype
sc._jvm.org.apache.spark.sql.api.python.PythonSQLUtils.parseDataType(type_str).json())
AttributeError: 'NoneType' object has no attribute '_jvm'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 839, in _parse_datatype_string
return from_ddl_datatype("struct<%s>" % s.strip())
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 827, in from_ddl_datatype
sc._jvm.org.apache.spark.sql.api.python.PythonSQLUtils.parseDataType(type_str).json())
AttributeError: 'NoneType' object has no attribute '_jvm'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 841, in _parse_datatype_string
raise e
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 831, in _parse_datatype_string
return from_ddl_schema(s)
File "/root/anaconda3/lib/python3.8/site-packages/pyspark/sql/types.py", line 823, in from_ddl_schema
sc._jvm.org.apache.spark.sql.types.StructType.fromDDL(type_str).json())
AttributeError: 'NoneType' object has no attribute '_jvm'
我左思右想,百思不得骑姐,嗐,跑去看 types.py里面的type类型,以为我的 udaf_lx 函数的装饰器里面的 ‘decimal(17,12)’ 类型错了,但是一看,好家伙,types.py 里面的774行
_FIXED_DECIMAL = re.compile(r"decimal\(\s*(\d+)\s*,\s*(-?\d+)\s*\)")
这是能匹配上的,没道理啊!
原因分析及解决方案:
然后再往回看报错的信息的最后一行:
AttributeError: 'NoneType' object has no attribute '_jvm'
竟然是空对象没有_jvm这个属性!
一拍脑瓜子,得了,pyspark的SQL 在执行的时候,需要用到 JVM ,而运行pyspark的时候,需要先要为spark提供环境,也就说,内存中要有SparkSession对象,而python在执行的时候,是从上往下,将方法加载到内存中,在加载自定义的UDAF函数时,由于有装饰器@F.pandas_udf的存在 , F 则是pyspark.sql.functions, 此时加载自定义的UDAF到内存中,需要有SparkSession的环境提供JVM,而此时的内存中尚未有SparkSession环境!因此,将自定义的UDAF 函数挪到 if __name__ == '__main__': 创建完SparkSession的后面,如下:
import decimal
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
if __name__ == '__main__':
# 1) 创建 SparkSession 对象,此对象连接 hive
spark = SparkSession.builder.master('local[*]') \
.appName('insurance_main') \
.config('spark.sql.shuffle.partitions', 4) \
.config('spark.sql.warehouse.dir', 'hdfs://node1:8020/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://node1:9083') \
.enableHiveSupport() \
.getOrCreate()
@F.pandas_udf('decimal(17,12)')
def udaf_lx(qx: pd.Series, lx: pd.Series) -> decimal:
# 初始值 也一定是decimal类型
tmp_qx = decimal.Decimal(0)
tmp_lx = decimal.Decimal(0)
for index in range(0, qx.size):
if index == 0:
tmp_qx = decimal.Decimal(qx[index])
tmp_lx = decimal.Decimal(lx[index])
else:
# 计算lx: 计算后,保证数据小数位为12位,与返回类型的设置小数位保持一致
tmp_lx = (tmp_lx * (1 - tmp_qx)).quantize(decimal.Decimal('0.000000000000'))
tmp_qx = decimal.Decimal(qx[index])
return tmp_lx
# 注册UDAF 支持在SQL中使用
spark.udf.register('udaf_lx', udaf_lx)
# 2) 编写SQL 执行
excuteSQLFile(spark, '_04_insurance_dw_prem_std.sql')
运行结果如图:
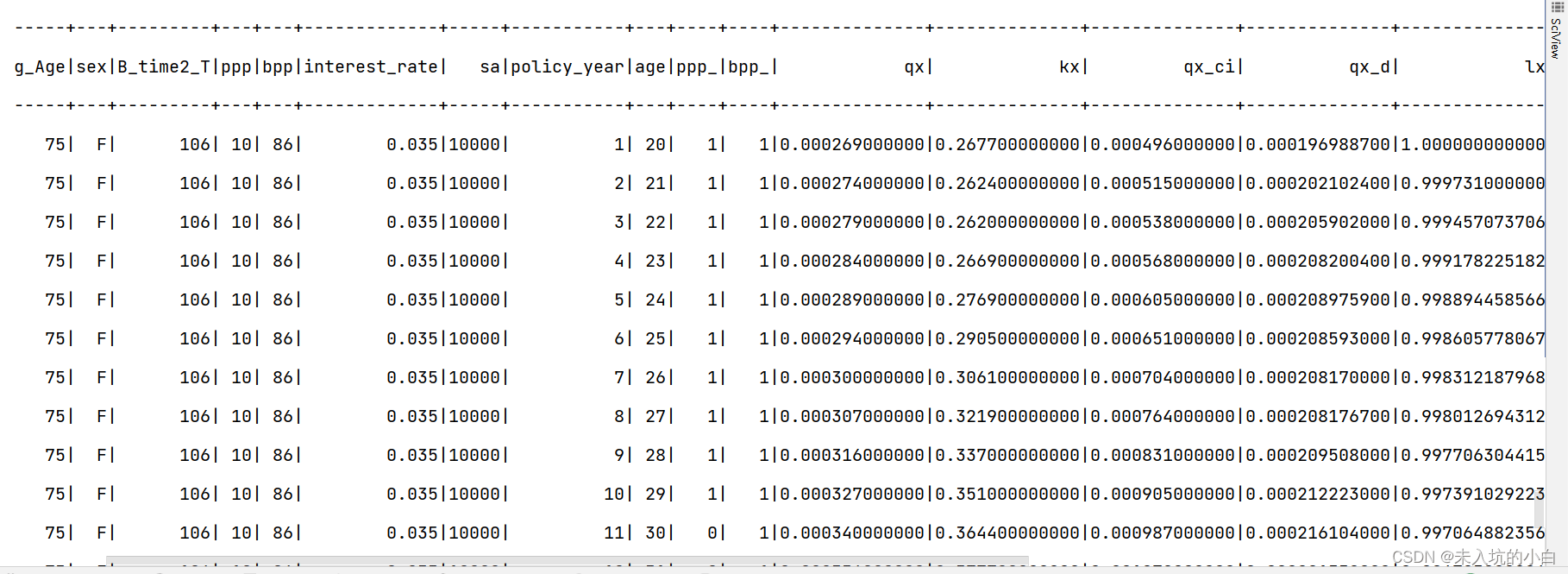
至此,完美解决!更多关于pyspark自定义UDAF函数报错的资料请关注我们其它相关文章!
相关推荐
-

pycharm利用pyspark远程连接spark集群的实现
0 背景 由于工作需要,利用spark完成机器学习.因此需要对spark集群进行操作.所以利用pycharm和pyspark远程连接spark集群.这里记录下遇到的问题及方法. 主要是参照下面的文献完成相应的内容,但是具体问题要具体分析. 1 方法 1.1 软件配置 spark2.3.3, hadoop2.6, python3 1.2 spark配置 Spark集群的每个节点的Python版本必须保持一致.在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你
-
pyspark创建DataFrame的几种方法
pyspark创建DataFrame 为了便于操作,使用pyspark时我们通常将数据转为DataFrame的形式来完成清洗和分析动作. RDD和DataFrame 在上一篇pyspark基本操作有提到RDD也是spark中的操作的分布式数据对象. 这里简单看一下RDD和DataFrame的类型. print(type(rdd)) # <class 'pyspark.rdd.RDD'> print(type(df)) # <class 'pyspark.sql.dataframe.Dat
-
pyspark操作hive分区表及.gz.parquet和part-00000文件压缩问题
目录 pyspark 操作hive表 pyspark 操作hive表 pyspark 操作hive表,hive分区表动态写入:最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约 4:1.针对该问题整理了 spark 操作hive表的几种方式. 1> saveAsTable写入 saveAsTable(self, name, format=None, mode=None, partitionBy=None, **options) 示例: df.write.
-
运行独立 pyspark 时出现 Windows 错误解决办法
我正在尝试在 Anaconda 中导入 pyspark 并运行示例代码.但是,每当我尝试在 Anaconda 中运行代码时,都会收到以下错误消息. 尝试连接到 Java 服务器时发生 ERROR:py4j.java_gateway:An 错误(127.0.0.1:53294)追溯(最近一次调用最近):文件" C:\ spark\python\lib\py4j-0.10.3-src.zip\py4j\java_gateway.py",行 send_command self.socket.
-
MAC下Anaconda+Pyspark安装配置详细步骤
在MAC的Anaconda上使用pyspark,主要包括以下步骤: 在MAC下安装Spark,并配置环境变量. 在Anaconda中安装引用pyspark. 1. MAC下安装Spark 到Apark Spark官网上下载Spark文件,无论是windows系统,还是MAC系统,亦或者Linux系统,都可以下载这个文件(独立于系统). 将下载的文件进行解压(可以使用命令行进行解压,也可以使用解压软件).解压之后的文件如下: 配置环境变量.打开MAC命令行窗口,输入如下命令: sudo vi
-
pyspark自定义UDAF函数调用报错问题解决
目录 问题场景: 问题描述 原因分析及解决方案: 问题场景: 在SparkSQL中,因为需要用到自定义的UDAF函数,所以用pyspark自定义了一个,但是遇到了一个问题,就是自定义的UDAF函数一直报 AttributeError: 'NoneType' object has no attribute '_jvm' 在此将解决过程记录下来 问题描述 在新建的py文件中,先自定义了一个UDAF函数,然后在 if __name__ == '__main__': 中调用,死活跑不起来,一遍又一遍的对
-
Spring Cloud Feign报错问题解决
这篇文章主要介绍了Spring Cloud Feign报错问题解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 如果我们使用Spring Cloud的Feign实现熔断,首先需要自定义一个熔断类,实现你的feign接口,然后实现方法,这些方法就是熔断方法,最后需要在你的feign接口中指定fallback为自定义类 但是启动过程中却出现了 org.springframework.beans.factory.BeanCreationExcept
-
Android扫描二维码时出现用户禁止权限报错问题解决办法
Android扫描二维码时出现用户禁止权限报错问题解决办法 当我用ZBarDecoder.jar写了一个扫描二维码的程序,确实实现了扫描功能.组长说如果用户禁止调用摄像头,那程序也不能崩溃.结果我一运行就崩溃了.在网上自己找了找,可以这样解决. try { mCameraManager.openDriver(); } catch (Exception e) { //当用户手动禁止摄像头权限时,防止系统崩溃 AlertDialog.Builder builder=new AlertDialog.B
-
JS 调试中常见的报错问题解决方法
报错:Uncaught SyntaxError: Unexpected token o in JSON at position 1 at JSON.parse (<anonymous>) at Function.m.parseJSON (jquery.js:8515) at Object.success (crud.html:45) at j (jquery.js:3143) at Object.fireWith [as resolveWith] (jquery.js:3255) at x (
-
关于IDEA2020.1新建项目maven PKIX 报错问题解决方法
报错问题如图: 仔细看报错问题后发现,这个错误的主要原因是: ValidatorException:PKIX path building failed : sun.security.provider.certpath.SunCertPathBuilderException : unable to find valid certification path to requested target 造成这个错误的原因是因为有些依赖和插件下载的时候需要验证证书,网上找了好多资料最终解决的,我这里集合了
-
IDEA 2021.2 激活教程及启动报错问题解决方法
关于idea2021最新激活教程,请点击此处,获取最新激活教程 还有一种激活方法,点击此处获取吧 ! 下面看下IDEA 2021.2 启动报错问题解决方法,内容如下所示: 错误信息如下: Plugin 'some.awesome' failed to initialize and will be disabled. Please restart IntelliJ IDEA. java.lang.NullPointerException at NyanApplicationComponen
-
vue踩坑记之npm install报错问题解决总结
目录 前言 常见的有以下多种情况 总结 前言 很多时候安装npm install 的时候并不能直接将当前的node_modules直接一键安装到本地. 总是会出现各种各样的报错 常见的有以下多种情况 tip1:本地node 跟npm 版本不匹配,项目创建者当时的版本为14 ,而新开发者本地node默认为最新需要重新降低版本,使用cmd打开查看本地node和npm版本,询问一下同事的版本,直接去node官网重新 下载安装新的node安装包即可,或者如果本地有多个新老项目为了方便的管理各个node的
-
CentOS 6.5上的Tomcat启动报错问题解决方法
这里有两个错误: 1.第一个错误,APR的问题,错误详情: The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path 2.第二个错误,错误详情: Exception in thread "main" java.lang.InternalError
-
$.ajax传JSON数据到后台出现报错问题解决
复制代码 代码如下: $.ajax({ url: "../Services.ashx", type: "POST", //data: { 'data': { 'typename': JSON.stringify(typename) }, 'operationType': '2' }, data: { 'data': typename, 'operationType': '2','nowheight':nowheight,'nowarea':nowarea }, su
-
centOS7下mysql插入中文字符报错问题解决方法
在刚装完mysql,就建立了数据库abc,然后新建一个abc表,插入英文没有问题,但是插入中文就有问题,会报错: ERROR 1366 (HY000): Incorrect string value: '\xE4\xBD\x99\xE9\x93\xB6...' 应该是数据库编码问题,所以应该改数据库编码 这里有2中方法.一种是直接敲代码设置,一种是在CentOS7中修改文件/usr/my.cnf, 第一种方法: 列出数据库的编码表 mysql> show variables like '%cha