移除Selenium中window.navigator.webdriver值
有不少朋友在开发爬虫的过程中喜欢使用Selenium + Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。
先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器。
我们来看一个例子。
使用下面这一段代码启动Chrome窗口:
现在,在这个窗口中打开开发者工具,并定位到Console选项卡,如下图所示。
from selenium.webdriver import Chrome driver = Chrome()
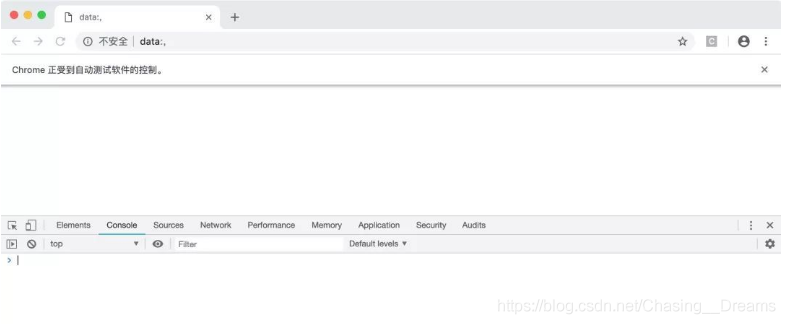
现在,在这个窗口输入如下的js代码并按下回车键:
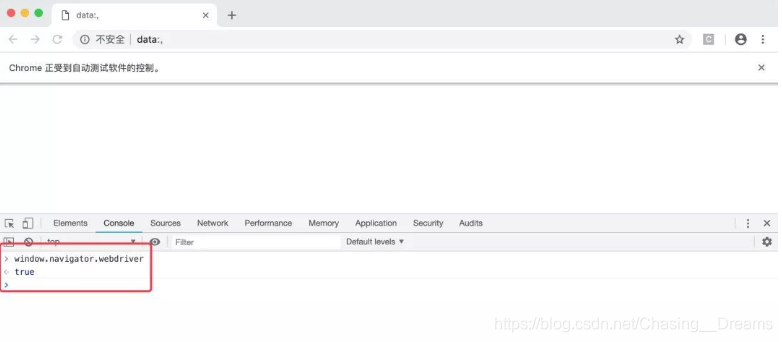
window.navigator.webdriver
可以看到,开发者工具返回了 true。如下图所示。
但是,如果你打开一个普通的Chrome窗口,执行相同的命令,可以发现这行代码的返回值为 undefined,如下图所示:
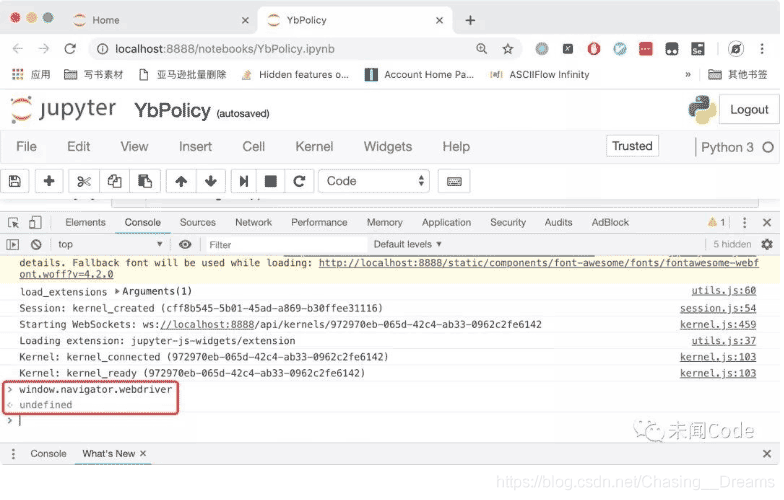
所以,如果网站通过js代码获取这个参数,返回值为 undefined说明是正常的浏览器,返回 true说明用的是Selenium模拟浏览器。一抓一个准。这里给出一个检测Selenium的js代码例子:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你这个小可爱你以为使用Selenium模拟浏览器就可以了?')
} else {
console.log('正常浏览器')
}
网站只要在页面加载的时候运行这个js代码,就可以识别访问者是不是用的Selenium模拟浏览器。如果是,就禁止访问或者触发其他反爬虫的机制。
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?
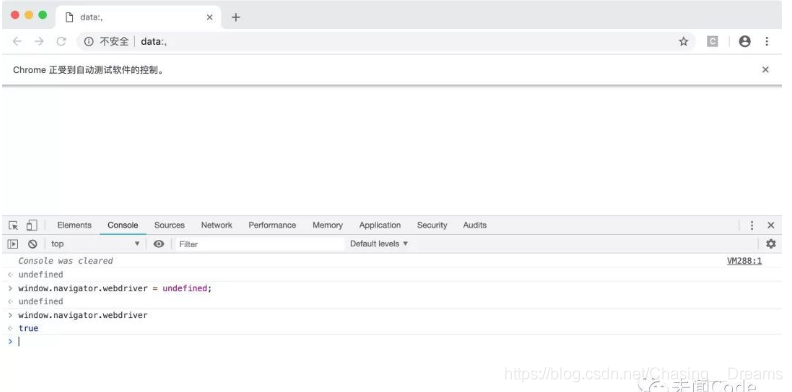
可能有一些会js的朋友觉得可以通过覆盖这个参数从而隐藏自己,但实际上这个值是不能被覆盖的:
对js更精通的朋友,可能会使用下面这一段代码来实现:
Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});
运行效果如下图所示:
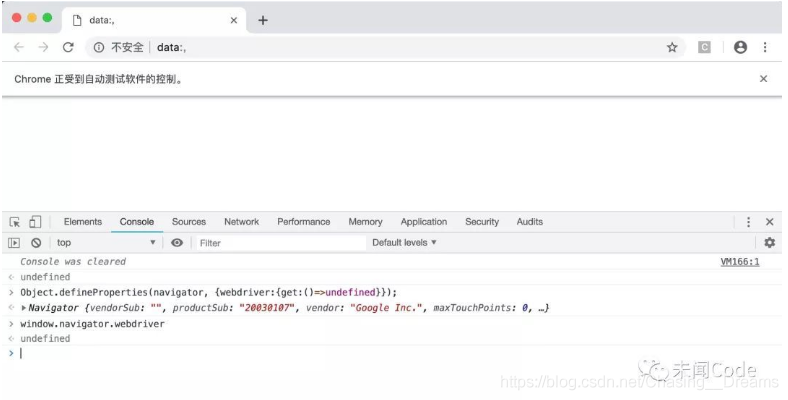
确实修改成功了。这种写法就万无一失了吗?并不是这样的,如果此时你在模拟浏览器中通过点击链接、输入网址进入另一个页面,或者开启新的窗口,你会发现, window.navigator.webdriver又变成了 true。
如下图所示。
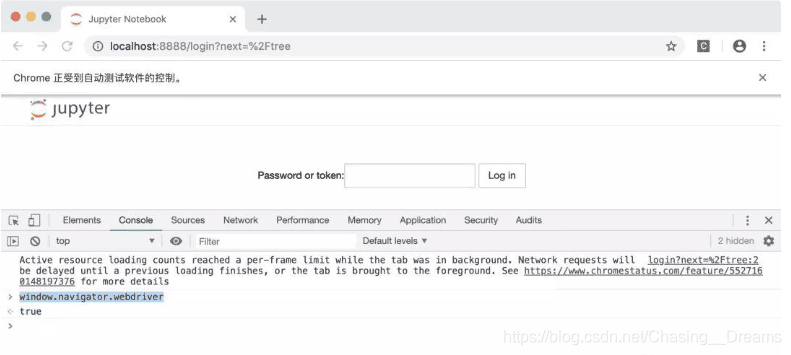
那么是不是可以在每一个页面都打开以后,再次通过webdriver执行上面的js代码,从而实现在每个页面都把 window.navigator.webdriver设置为 undefined呢?也不行。
因为当你执行: driver.get(网址)的时候,浏览器会打开网站,加载页面并运行网站自带的js代码。
所以在你重设 window.navigator.webdriver之前,实际上网站早就已经知道你是模拟浏览器了。
接下来,又有朋友提出,可以通过编写Chrome插件来解决这个问题,让插件里面的js代码在网站自带的所有js代码之前执行。
这样做当然可以,不过有更简单的办法,只需要设置Chromedriver的启动参数即可解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数 excludeSwitches,它的值为 [‘enable-automation’],
完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
此时启动的Chrome窗口,在右上角会弹出一个提示,不用管它,不要点击 停用按钮。
再次在开发者工具的Console选项卡中查询 window.navigator.webdriver,可以发现这个值已经自动变成 undefined了。并且无论你打开新的网页,开启新的窗口还是点击链接进入其他页面,都不会让它变成 true。运行效果如下图所示。
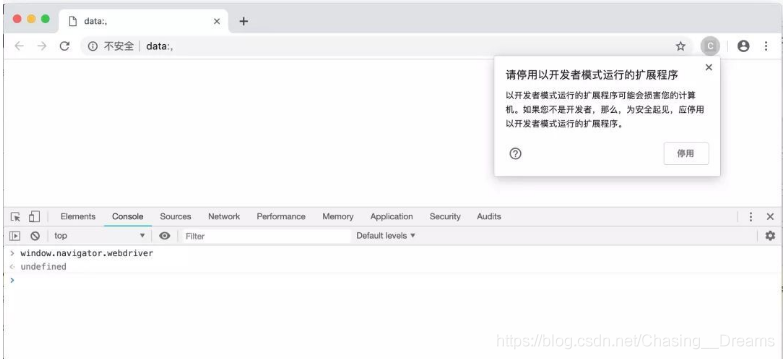
以上就是移除Selenium中window.navigator.webdriver值的详细内容,更多关于window.navigator.webdriver值移除的资料请关注我们其它相关文章!
相关推荐
-
selenium.webdriver中add_argument方法常用参数表
我们在使用selenium库调用Chromedriver.exe时需要很多的配置参数下面列出了常用参数 chrome_options.add_argument("xxx") 序号 参数 说明 1 --allow-outdated-plugins 不停用过期的插件. 2 --allow-running-insecure-content 默认情况下,https 页面不允许从 http 链接引用 javascript/css/plug-ins.添加这一参数会放行这
-

Selenium Webdriver元素定位的八种常用方式(小结)
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下. 1. By.name() 假设我们要测试的页面源码如下: <button id="gbqfba" aria-label="Google Search" name="btnK" class="gbqfba"><
-
浅谈Selenium+Webdriver 常用的元素定位方式
假设页面源代码如下: <input type="text"name="wd" id="kw1" class="input_wd" maxlength="100"style="width:474px;"autocomplete="off"> 通过id定位元素:find_element_by_id("id_vaule"): browser=
-
selenium WebDriverWait类等待机制的实现
在自动化测试脚本的运行过程中,可以通过设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败,常用的等待方式有三种: 一.固定等待(time) 固定待是利用python语言自带的time库中的sleep()方法,固定等待几秒.这种方式会导致这个脚本运行时间过长,不到万不得已尽可能少用.(注:脚本调试过程时,还是可以使用的,方便快捷) from selenium import webdriver import time #驱动浏览器 driver = webdriver.Chrome() #设
-
详解Selenium-webdriver绕开反爬虫机制的4种方法
之前爬美团外卖后台的时候出现的问题,各种方式拖动验证码都无法成功,包括直接控制拉动,模拟人工轨迹的随机拖动都失败了,最后发现只要用chrome driver打开页面,哪怕手动登录也不可以,猜测driver肯定是直接被识别出来了.一开始尝试了改user agent等方式,仍然不行,由于其他项目就搁置了.今天爬淘宝生意参谋又出现这个问题,经百度才知道原来chrome driver的变量有一个特征码,网站可以直接根据特征码判断,经百度发现有4种方法可以解决,记录一下自己做的尝试. 1.mitproxy
-
移除Selenium中window.navigator.webdriver值
有不少朋友在开发爬虫的过程中喜欢使用Selenium + Chromedriver,以为这样就能做到不被网站的反爬虫机制发现. 先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器. 我们来看一个例子. 使用下面这一段代码启动Chrome窗口: 现在,在这个窗口中打开开发者工具,并定位到Console选项卡,如下图所示. from selenium.webdriver
-
解析array splice的移除数组中指定键的值,返回一个新的数组
使用环境:人才网项目中有一个简历保密设置,其中有一个过滤关键词,只有某个企业的公司名中包含有其中的一个关键字,就不显示该份简历,当然,我还没有做到那里去,现在是要做关键词的增加删除.设想:不管一个人有多少份简历,所有简历都设置成一模一样的关键词过滤(主要是用的人也很少,所以这样存储无所谓,而且在搜索使用中很方便),然后将所有关键词组成一个用半角逗号分隔的字符串.难题:显示的时候我将字符串转化成数组然后再循环出来显示,但是我现在就是要删除指定的关键词.解决方案:既然转化成了数组,那么有值就有键,我
-
php数组函数序列之array_unique() - 去除数组中重复的元素值
array_unique() 定义和用法 array_unique() 函数移除数组中的重复的值,并返回结果数组. 当几个数组元素的值相等时,只保留第一个元素,其他的元素被删除. 返回的数组中键名不变. 语法 array_unique(array) 参数 描述 array 必需.规定输入的数组. 说明 array_unique() 先将值作为字符串排序,然后对每个值只保留第一个遇到的键名,接着忽略所有后面的键名.这并不意味着在未排序的 array 中同一个值的第一个出现的键名会被保留. 提示和注
-
PHP实现移除数组中为空或为某值元素的方法
本文实例讲述了PHP实现移除数组中为空或为某值元素的方法.分享给大家供大家参考,具体如下: 在实现移除数组中项目为空的元素或为某值的元素时用到了两个函数 array_filter.create_function 先看一个实例: $array = Array ( [0] => 1 ,[1] => 2, [2] => 3, [3] => 4,[4] => '',[5] => '' ); $array = array_filter($array,create_function
-
selenium中常见的表单元素操作方法总结
目录 前言 操作表单元素 常见的表单元素 行为链 Cookie操作 页面等待 切换页面 设置代理ip WebElement元素 总结 前言 selenium是浏览器自动化测试框架,是一个用于Web应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击.下拉.填充数据.删除cookie等操作,还可以获取浏览器当前页面的源代码,就像用户在浏览器中操作一样.该工具所支持的浏览器有IE浏览器.Mozilla Firefox以及Google Chrome等.selenium有
-
浅谈DOCTYPE对$(window).height()取值的影响
前言:公司项目需要用到一个弹框垂直居中,网上类似的垂直居中弹出层大同小异,因为项目是基于Jquery 下的,所以用$(window).height()-layer.height())/2 +$(document).scrollTop()取得垂直的位移.测了各种浏览器没问题,后台人员移值到项目中后,出问题了,当页面超出一屏时,在 chrome和FF下,弹出框不是在当前屏的垂直居中,而是相对于整个网页的居中. 查阅各方资料,所有结论都指出: 1.窗口高度,$(window).height() 2.文
-
python 解决selenium 中的 .clear()方法失效问题
最近在使用selenium做一个数字货币的自动化脚本时,遇到一个问题就是okex网站的input使用clear()方法居然无法清空,但是后来试了好多次发现方法是可以使用的,而且这个网站修改input的value也没用,必须在文本框里修改才行,本次的目的就是要清除输入框的默认值,然而clear()没有反应,最后还是用了别的方法解决了问题,那就是使用鼠标双击事件,全选后输入内容. from selenium.webdriver.common.action_chains import ActionCh
-
详解Selenium 元素定位和WebDriver常用方法
一.定位元素的8种方式 1.方法介绍 定位一个元素 定位多个元素 含义 find_element_by_id() find_elements_by_id() 通过元素id定位 find_element_by_name() find_elements_by_name() 通过元素name定位 find_element_by_xpath() find_elements_by_xpath() 通过xpath表达式定位 find_element_by_link_text() find_elements_
-
python selenium中Excel数据维护指南
接着python里面的xlrd模块详解(一)中我们我们来举一个实例: 我们来举一个从Excel中读取账号和密码的例子并调用: ♦1.制作Excel我们要对以上输入的用户名和密码进行参数化,使得这些数据读取自Excel文件.我们将Excel文件命名为data.xlsx,其中有两列数据,第一列为username,第二列为password. ♦2.读取Excel代码如下 #-*- coding:utf-8 -*- import xlrd,time,sys,unittest #导入xlrd等相关模块 c
-
详解Selenium中元素定位方式
目录 八大元素定位方式 通过元素 id 定位 通过元素 name 定位 通过元素 class name 定位 通过 link text 与 partial link text 定位 通过 css selector 选择器定位 通过 Xpath 定位 通过 tag_name 定位 测试对象的定位和操作是我们利用 selenium 编写自动化脚本和 webdriver 的核心内容,其中 “操作” 这一部分又是建立在 “selenium” 元素定位的基础之上的.所以对元素对象的定位就显得越发的重要,接