Python使用多进程运行含有任意个参数的函数
1. 问题引出
许多时候,我们对程序的速度都是有要求的,速度自然是越快越好。对于Python的话,一般都是使用multiprocessing这个库来实现程序的多进程化,例如:
我们有一个函数my_print,它的作用是打印我们的输入:
def my_print(x):
print(x)
但是我们嫌它的速度太慢了,因此我们要将这个程序多进程化:
from multiprocessing import Pool def my_print(x): print(x) if __name__ == "__main__": x = [1, 2, 3, 4, 5] pool = Pool() pool.map(my_print, x) pool.close() pool.join()
很好,现在速度与之前的单进程相比提升非常的快,但是问题来了,如果我们的参数不只有一个x,而是有多个,这样能行吗?比如现在my_print新增一个参数y:
def my_print(x, y):
print(x + y)
查看pool.map的函数说明:
def map(self, func, iterable, chunksize=None): ''' Apply `func` to each element in `iterable`, collecting the results in a list that is returned. ''' return self._map_async(func, iterable, mapstar, chunksize).get()
发现函数的参数是作为iter传进去的,但是我们现在有两个参数,自然想到使用zip将参数进行打包:
if __name__ == "__main__": x = [1, 2, 3, 4, 5] y = [1, 1, 1, 1, 1] zip_args = list(zip(x, y)) pool = Pool() pool.map(my_print, zip_args) pool.close() pool.join()
可是执行后却发现,y参数并没有被传进去:
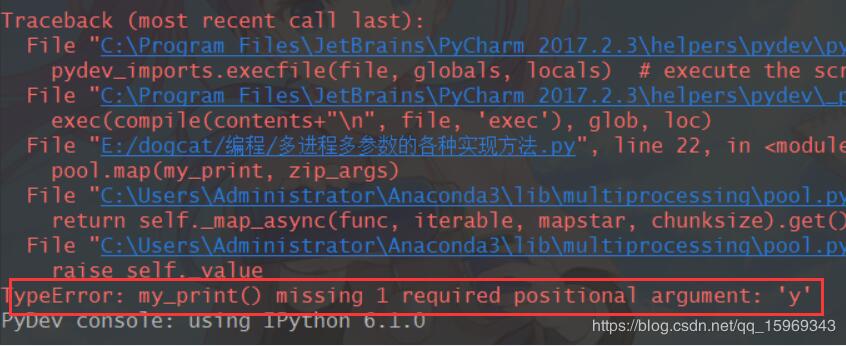
那么如何传入多个参数呢?这也就是本文的重点,接着往下看吧。
2. 解决方案
2.1 使用偏函数(partial)
偏函数有点像数学中的偏导数,可以让我们只关注其中的某一个变量而不考虑其他变量的影响。上面的例子中,Y始终等于1,那么我们在传入参数的时候,只需要考虑X的变化即可。
例如你有一个函数,该函数有两个参数a,b,a是不同路径的下的图片的路径,b是输出的路径。很明显,a是一直在变化的,但是因为我们要将所有图片保存在同一个文件夹下,那么b很可能一直都没变。
具体如下:
if __name__ == '__main__':# 多线程,多参数,partial版本 x = [1, 2, 3, 4, 5] y = 1 partial_func = partial(my_print, y=y) pool = Pool() pool.map(partial_func, x) pool.close() pool.join()
2.2 使用可变参数
在Python函数中,函数可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,这就直接给我们提供了一种思路。具体如下:
def multi_wrapper(args): return my_print(*args) def my_print(x, y): print(x + y) if __name__ == "__main__": # 多线程,多参数,可变参数版本 x = [1, 2, 3, 4, 5] y = [1, 1, 1, 1, 1] zip_args = list(zip(x, y)) pool = Pool() pool.map(multi_wrapper, zip_args) pool.close() pool.join()
2.3 使用pathos提供的多进程库
from pathos.multiprocessing import ProcessingPool as newPool if __name__ == '__main__':# 多线程,多参数,pathos版本 x = [1, 2, 3, 4, 5] y = [1, 1, 1, 1, 1] pool = newPool() pool.map(my_print, x, y) pool.close() pool.join()
在该库的map函数下,可以看到,它允许多参数输入,其实也就是使用了可变参数:
def map(self, f, *args, **kwds): AbstractWorkerPool._AbstractWorkerPool__map(self, f, *args, **kwds) _pool = self._serve() return _pool.map(star(f), zip(*args)) # chunksize
2.4 使用starmap函数
if __name__ == '__main__': # 多线程,多参数,starmap版本 x = [1, 2, 3, 4, 5] y = [1, 1, 1, 1, 1] zip_args = list(zip(x, y)) pool = Pool() pool.starmap(my_print, zip_args) pool.close() pool.join()
3. 总结
其实在以上4种实现方法中 ,第1种方法的限制较多,如果该函数的其它参数都在变化的话,那么它就不能很好地工作,而剩下的方法从体验上来讲是依次递增的,它们都可以接受任意多参数的输入,但是第2种需要额外写一个函数,扣分;第3种方法需要额外安装pathos包,扣分;而最后一种方法不需要任何额外不择就可以完成,所以,推荐大家选择第4种方法!
以上这篇Python使用多进程运行含有任意个参数的函数就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现多进程的四种方式
方式一: os.fork() # -*- coding:utf-8 -*- """ pid=os.fork() 1.只用在Unix系统中有效,Windows系统中无效 2.fork函数调用一次,返回两次:在父进程中返回值为子进程id,在子进程中返回值为0 """ import os pid=os.fork() if pid==0: print("执行子进程,子进程pid={pid},父进程ppid={ppid}".format
-
python实现在每个独立进程中运行一个函数的方法
本文实例讲述了python实现在每个独立进程中运行一个函数的方法.分享给大家供大家参考.具体分析如下: 这个简单的函数可以同于在单独的进程中运行另外一个函数,这对于释放内存资源非常有用 #!/usr/bin/env python from __future__ import with_statement import os, cPickle def run_in_separate_process(func, *args, **kwds): pread, pwrite = os.pipe() pi
-
Python中使用多进程来实现并行处理的方法小结
进程和线程是计算机软件领域里很重要的概念,进程和线程有区别,也有着密切的联系,先来辨析一下这两个概念: 1.定义 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位. 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源. 2.关系 一个线程可以创建和撤
-
在Python函数中输入任意数量参数的实例
有时候,预先不知道函数需要接受多少个实参,好在Python允许函数从调用语句中调用语句中收集任意数量的实参.在参数前加上*号. 来看一个制作披萨的函数,它需要接受很多配料,但你无法预先确定顾客要多少种配料.下面的函数只有一个形参*toppings,但不管调用语句提供了多少实参,这个形参都将他们统统收入囊中: def make_pizza(*toppings): """打印顾客点的所有配料""" print(toppings) make_pizza
-
Python使用多进程运行含有任意个参数的函数
1. 问题引出 许多时候,我们对程序的速度都是有要求的,速度自然是越快越好.对于Python的话,一般都是使用multiprocessing这个库来实现程序的多进程化,例如: 我们有一个函数my_print,它的作用是打印我们的输入: def my_print(x): print(x) 但是我们嫌它的速度太慢了,因此我们要将这个程序多进程化: from multiprocessing import Pool def my_print(x): print(x) if __name__ == "__
-
Python实现接受任意个数参数的函数方法
这个功能倒也不是我多么急需的功能,只是恰好看到了,觉得或许以后会用的到.功能就是实现函数能够接受不同数目的参数. 其实,在C语言中这个功能是熟悉的,虽说实现的形式不太一样.C语言中的main函数是可以实现类似的功能的,可以通过这种方式实现一个支持命令行参数的程序. 先写一段python实现相应功能的示范代码: defFuncDemo(*par): print("number of pars: %d" %len(par)) print("type of par: %s"
-
keras tensorflow 实现在python下多进程运行
如下所示: from multiprocessing import Process import os def training_function(...): import keras # 此处需要在子进程中 ... if __name__ == '__main__': p = Process(target=training_function, args=(...,)) p.start() 原文地址:https://stackoverflow.com/questions/42504669/ker
-
浅谈python脚本设置运行参数的方法
正在学习Django框架,在运行manage.py的时候需要给它设置要监听的端口,就是给这个脚本一个运行参数.教学视频中,是在Eclipse中设置的运行参数,网上Django大部分都是在命令行中运行manage.py时添加参数,没有涉及到如何在pycharm中设置运行参数.以下是两种设置运行参数的方法(以manage.py为例),不设置运行参数时,运行结果为 D:\Python2.7\python.exe "D:/Django project/DjangoProject1/manage.py&q
-
解决python 执行sql语句时所传参数含有单引号的问题
在编写自己的程序时,需要实现将数据导入数据库,并且是带参数的传递. 执行语句如下: sql_str = "INSERT INTO teacher(t_name, t_info, t_phone, t_email) VALUES\ (\'%s\', \'%s\', \'%s\', \'%s\')" % (result, result2, phoneNumber, Email) cur.execute(sql_str) 执行程序后,产生错误: ProgrammingError: (1064
-
基于python的多进程共享变量正确打开方式
多进程共享变量和获得结果 由于工程需求,要使用多线程来跑一个程序.但是因为听说python的多线程是假的,于是使用多进程,反正任务需要共享的参数少. 查阅资料,发现实现多进程主要使用Multiprocessing,有两种方式,一种是Process,另一种是Pool. p = Process(target=fun,args=(args)) 再通过p.start()来启动一个子进程,通过p.join()方法来使得子进程运行结束后再执行父进程. 但是这样很烦,还要写个for 循环来开n个线程和join
-
Python multiprocessing多进程原理与应用示例
本文实例讲述了Python multiprocessing多进程原理与应用.分享给大家供大家参考,具体如下: multiprocessing包是Python中的多进程管理包,可以利用multiprocessing.Process对象来创建进程,Process对象拥有is_alive().join([timeout]).run().start().terminate()等方法. multprocessing模块的核心就是使管理进程像管理线程一样方便,每个进程有自己独立的GIL,所以不存在进程间争抢
-

Python Multiprocessing多进程 使用tqdm显示进度条的实现
1.背景 在python运行一些,计算复杂度比较高的函数时,服务器端单核CPU的情况比较耗时,因此需要多CPU使用多进程加快速度 2.函数要求 笔者使用的是:pathos.multiprocessing 库,进度条显示用tqdm库,安装方法: pip install pathos 安装完成后 from pathos.multiprocessing import ProcessingPool as Pool from tqdm import tqdm 这边使用pathos的原因是因为,multip
-
python使用多进程的实例详解
python多线程适合IO密集型场景,而在CPU密集型场景,并不能充分利用多核CPU,而协程本质基于线程,同样不能充分发挥多核的优势. 针对计算密集型场景需要使用多进程,python的multiprocessing与threading模块非常相似,支持用进程池的方式批量创建子进程. •创建单个Process进程(使用func) 只需要实例化Process类,传递函数给target参数,这点和threading模块非常的类似,args为函数的参数 import os from multiproce