python读取npy文件数据实例
目录
- 1. 读取与保存
- 2. 实战案例
- 附:python中 .npy文件的读写操作实例
- 总结
Numpy binary files (NPY, NPZ)
注:.npy文件是numpy专用的二进制文件。
1. 读取与保存
import numpy as np
arr = np.array([[1, 2, 3],
[4, 5, 6]])
np.save('weight.npy', arr)
loadData = np.load('weight.npy')
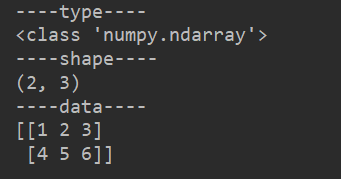
print("----type----")
print(type(loadData))
print("----shape----")
print(loadData.shape)
print("----data----")
print(loadData)
至于具体API参见:https://docs.scipy.org/doc/numpy/index.html
2. 实战案例
在深度神经网络训练过程中通常需要读取预训练权重,预训练权重通常是 .npy文件,比如vgg16.npy(https://pan.baidu.com/s/1Ru5FJVSPjYTHZwlmzRwRvQ 提取码:ygxw)。本次就以分析vgg16.npy为例进行说明。
import numpy as np
# 注意编码方式
pre_train = np.load("vgg16.npy", allow_pickle=True, encoding="latin1")
print("------type-------")
print(type(pre_train))
print("------shape-------")
print(pre_train.shape)
print("------data-------")
print(pre_train)
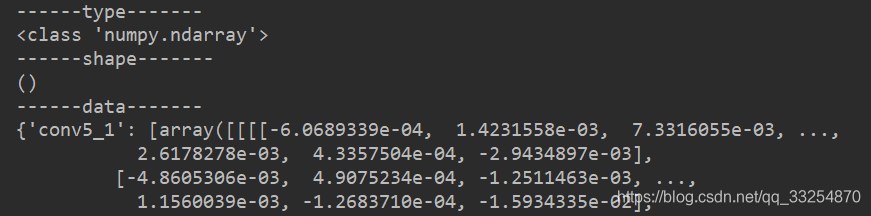
这是个啥?为啥shape没有? 但是可以看出来 pre_train 里元素应该是一个字典,我们尝试取出来。
注:ndarray.item()是复制数组中的一个元素,并将其返回。具体语法参见:https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.item.html?highlight=item#numpy.ndarray.item
import numpy as np
pre_train = np.load("vgg16.npy", allow_pickle=True, encoding="latin1")
data_dic = pre_train.item()
print("------type-------")
print(type(data_dic))
print("------conv1_1 data-------")
print(data_dic['conv1_1']) # 返回一个列表,该列表有两个array,表示conv1_1的权重w与偏置b
print("------conv1_1 shape-------")
print((data_dic['conv1_1'][0]).shape)
看看结果:


可以发现,这是第一个卷积层的权重参数,输入channel是3,输出channel是64。
附:python中 .npy文件的读写操作实例
numpy中的二进制文件的读写:
save
np.save ("./文件名", 数组名):以二进制的格式保存数据
load
np.load("./文件名.npy"): 函数是从二进制的文件中读取数据
savez
np.savez(’./文件名’,数组名1,数组名2,…):savez 函数可以将多个数组保存到一个文件中
(1)save操作
import numpy as np
a=np.arange(5)
np.save('get.npy',a)
(2)load操作
import numpy as np
a=np.load('load.npy')
print(a)
(3)savez操作
import numpy as np
a=np.arange(3)
b=np.arange(4)
c=np.arange(5)
np.savez('array_save.npz',a,b,c) 多个ndarray类型的数组
总结
到此这篇关于python读取npy文件数据的文章就介绍到这了,更多相关python读取npy文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python3 如何读取python2的npy文件
python3读取python2打包的npy文件会报错,原因是编码方式不同,所以只要在读取的时候加上编码方式即可. 解决方法 docs_train = np.load('./data/20news_clean/train.txt.npy', allow_pickle=True, encoding='bytes') docs_test = np.load('./data/20news_clean/test.txt.npy', allow_pickle=True, encoding='bytes')
-

解决python 读取npy文件太大不能完全显示的问题
python读取npy文件时,太大不能完全显示,其解决方法 当用python读取npy文件时,会遇到npy文件太大,用print函数打印时不能完全显示,如以下情况: 解决办法 添加一行代码:np.set_printoptions(threshold = 1e6),其中threshold表示输出数组的元素数目 其结果如下: 补充:PyCharm打开大文件时提示文件过大,只显示前一小部分 使用pycharm打开一些大文件时,会出现上述提示,表明文件过大,只能以只读的方式显示前一小部分内容,这种情况显
-
python读取npy文件数据实例
目录 1. 读取与保存 2. 实战案例 附:python中 .npy文件的读写操作实例 总结 Numpy binary files (NPY, NPZ) 注:.npy文件是numpy专用的二进制文件. 1. 读取与保存 import numpy as np arr = np.array([[1, 2, 3], [4, 5, 6]]) np.save('weight.npy', arr) loadData = np.load('weight.npy') print("----type----&qu
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec
-
Python 存取npy格式数据实例
数据处理的时候主要通过两个函数 (1):np.save("test.npy",数据结构) ----存数据 (2):data =np.load('test.npy") ----取数据 给2个例子如下(存列表) 1. z = [[[1, 2, 3], ['w']], [[1, 2, 3], ['w']]] np.save('test.npy', z) x = np.load('test.npy') x: ->array([[list([1, 2, 3]), list(['w
-
Python读取txt文件数据的方法(用于接口自动化参数化数据)
小试牛刀: 1.需要python如何读取文件 2.需要python操作list 3.需要使用split()对字符串进行分割 代码运行截图 : 代码(copy) #encoding=utf-8 #1.range中填写的数据 跟txt中行数保持一致 默认按照空格分隔 f_space = open(r"C:\Users\Administrator\Desktop\Space.txt","r") line_space = f_space.readlines() for i
-
简单了解Python读取大文件代码实例
这篇文章主要介绍了简单了解Python读取大文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 通常对于大文件读取及处理,不可能直接加载到内存中,因此进行分批次小量读取及处理 I.第一种读取方式 一行一行的读取,速度较慢 def read_line(path): with open(path, 'r', encoding='utf-8') as fout: line = fout.readline() while line: line
-
python读取各种文件数据方法解析
python读取.txt(.log)文件 ..xml 文件 .excel文件数据,并将数据类型转换为需要的类型,添加到list中详解 1.读取文本文件数据(.txt结尾的文件)或日志文件(.log结尾的文件) 以下是文件中的内容,文件名为data.txt(与data.log内容相同),且处理方式相同,调用时改个名称就可以了: 以下是python实现代码: # -*- coding:gb2312 -*- import json def read_txt_high(filename): with o
-
python读取查看npz/npy文件数据以及数据完全显示方法实例
目录 python读取npz/npy文件 python查看npz/npy文件 附:python-读取和保存npy文件示例代码 总结 python读取npz/npy文件 npz和npy文件都可以直接使用numpy读写. import numpy as np ac = np.load('mydata.npz') ac.files python查看npz/npy文件 要查看其中某一项的数据: M = ac['M'] M 显示的值带省略号,要完全显示,执行: np.set_printoptions(th
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd