Python爬虫之爬取二手房信息
前言
说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城。哎呦,我这暴脾气,想到就赶紧去干。
但很显然,我失败了。说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了。下面来看看 58 同城的反爬手段了。这是我爬取下来的网页源码。

我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况。
爬取二手房信息
我打开 58 同城的 robots 协议。

好家伙,不愧是大公司,所有的动态网址都不让爬取,打扰了。我只好转头离开,去寻找可以让我这种小白爬取的二手房网站。于是我找到了c21网站,不知道是我的原因,还是别的原因,反正我是没有找到这个网站的 robots 协议。不管了,既然没找到,就默认没有吧,直接开始爬取。
我本来打算通过二手房的目录跳到一个具体信息,然后爬取二手房的一些基本信息和属性。


像我红笔圈起来的部分。但很可惜我失败了,后来我看了看红笔圈起来的部分的爬取到的源码。

好家伙,还可以这样。不过这怎么可以难倒机智的我?(其实我真不知道怎么解决它)。没关系,之前的源码里不是有类似的信息吗?我只好将就一下了。

然后是翻页。翻页问题很好解决,我们很快就发现网页都是 https://bj.c21.com.cn/ershoufang/pg2/。其中的页数和 pg 后面的数字有关。
然后就是分析这些数据源码的位置了。
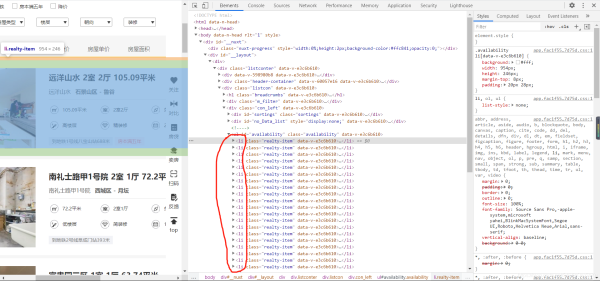
首先,我们发现我们要爬取的数据全在 li 标签里,所以我们可以先获得 li 标签的列表。伪代码就像这样。
form lxml import etree …… …… tree = etree.HTML(源码) li_list = tree.xpath( li 标签的路径)
这时候我们获得的就是 li 标签的 etree 的类,可以继续使用 etree 类里的函数。然后我们就可以利用 for 循环提出不同房源的 li 标签,根据自己的需要获取文本信息。
欧克,了解了这些(感觉源码前前后后就是四个字 ”我是菜鸡“ )我们就可以开始写代码了。
import requests
from lxml import etree
import re
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for pg in range(1, 3): # 翻两页
# 指定 url
url = "https://bj.c21.com.cn/ershoufang/pg%s/" % str(pg)
# 获取网页源码
page = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(page)
li_list = tree.xpath('//ul[@id="availability"]/li')
for li in li_list:
title = li.xpath('div[2]/div/a/text()')[0] # 房子的名称
# print(title[0]) # 测试
add = li.xpath('div[2]/div/p//a/text()') # 地址
add = add[-2: ] + add[0:1] # 地址范围由大到小
# print(add) # 测试
div_list = li.xpath('div[2]/div[2]/div')
# 具体信息
message_list = ["建筑面积", "房屋户型", "房屋朝向", "所在楼层", "装修情况", "建成时间"]
for i in range(6):
div = div_list[i]
message = div.xpath('span/text()')[0]
message = re.sub("\s", "", str(message)) # 因为发现获取的文本有很多换行符和空格,所以需要去掉
message = re.sub("\\n", "", str(message))
message_list[i] = message_list[i] + ":" + message
# print(message_list) # 测试
# 交通情况
traffic = li.xpath('div[2]/div[4]//text()')
# print(traffic) # 测试
# 价格情况
price = li.xpath('div[2]/div[3]//text()')
price = price[0] + price[1]
# print(price) # 测试
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\二手房\\" + "二手房.txt", "a", encoding = "utf-8") as fp:
fp.write(title + "\n")
for message in message_list:
fp.write(message + "\n")
if traffic == []:
fp.write("交通情况:无介绍" + "\n")
else:
fp.write("交通情况:" + traffic[0] + "\n")
fp.write("价格:" + price + "\n\n")
print(title, "下载完成!!!")
print("over!!!")
爬取结果
最后的运行结果就像这样

到此这篇关于Python爬虫之爬取二手房信息的文章就介绍到这了,更多相关Python爬取二手房信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
基于python爬取链家二手房信息代码示例
基本环境配置 python 3.6 pycharm requests parsel time 相关模块pip安装即可 确定目标网页数据 哦豁,这个价格..................看到都觉得脑阔疼 通过开发者工具,可以直接找到网页返回的数据~ 每一个二手房的数据,都在网页的 li 标签里面,咱们可以获取网页返回的数据,然后通过解析,就可以获取到自己想要的数据了~ 获取网页数据 import requests headers = { 'User-Agent': 'Mozilla/5.0 (W
-

python爬虫之爬取笔趣阁小说
前言 为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 一.首先导入相关的模块 import os import requests from bs4 import BeautifulSoup 二.向网站发送请求并获取网站数据 网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例. 进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取 # 声明请求头 headers = { 'Use
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
Python爬取OPGG上英雄联盟英雄胜率及选取率信息的操作
本次爬取网站为opgg,网址为:" http://www.op.gg/champion/statistics" 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单 现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码).通过查找"53.84%"快速定位Garen所在位置 由代码可看出,英雄名.胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tb
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
python爬虫之爬取谷歌趋势数据
一.前言 爬取谷歌趋势数据需要科学上网~ 二.思路 谷歌数据的爬取很简单,就是代码有点长.主要分下面几个就行了 爬取的三个界面返回的都是json数据.主要获取对应的token值和req,然后构造url请求数据就行 token值和req值都在这个链接的返回数据里.解析后得到token和req就行 socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了.全部代码如下 import socket import socks import requests import json im
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
Python爬虫之爬取二手房信息
前言 说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城.哎呦,我这暴脾气,想到就赶紧去干. 但很显然,我失败了.说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了.下面来看看 58 同城的反爬手段了.这是我爬取下来的网页源码. 我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况. 爬取二手房信息 我打开
-
Python爬虫之爬取我爱我家二手房数据
一.问题说明 首先,运行下述代码,复现问题: # -*-coding:utf-8-*- import re import requests from bs4 import BeautifulSoup cookie = 'PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj; HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207; _ga=GA1.2.556271139.1620784
-
python 爬虫一键爬取 淘宝天猫宝贝页面主图颜色图和详情图的教程
实例如下所示: import requests import re,sys,os import json import threading import pprint class spider: def __init__(self,sid,name): self.id = sid self.headers = { "Accept":"text/html,application/xhtml+xml,application/xml;", "Accept-Enc
-
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成 1)搜索要点 美团美食,地址:北京,搜索关键词:火锅 2)爬取的url https://bj.meituan.com/s/%E7%81%AB%E9%94%85/ 3)说明 url会有自动编码中文功能.所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85. 通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词. 这样我们就可以了解到当前url的构造. 2.分析页面数据来源(F12开发者工具) 开启F12开发
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
Python爬虫之爬取哔哩哔哩热门视频排行榜
一.bs4解析 import requests from bs4 import BeautifulSoup import datetime if __name__=='__main__': url = 'https://www.bilibili.com/v/popular/rank/all' headers = { //设置自己浏览器的请求头 } page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(pag
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
python爬虫之爬取笔趣阁小说升级版
python爬虫高效爬取某趣阁小说 这次的代码是根据我之前的 笔趣阁爬取 的基础上修改的,因为使用的是自己的ip,所以在请求每个章节的时候需要设置sleep(4~5)才不会被封ip,那么在计算保存的时间,每个章节会花费6-7秒,如果爬取一部较长的小说时,时间会特别的长,所以这次我使用了代理ip.这样就可以不需要设置睡眠时间,直接大量访问. 一,获取免费ip 关于免费ip,我选择的是站大爷.因为免费ip的寿命很短,所以尽量要使用实时的ip,这里我专门使用getip.py来获取免费ip,代码会爬取最
-
Python爬虫实例爬取网站搞笑段子
众所周知,python是写爬虫的利器,今天作者用python写一个小爬虫爬下一个段子网站的众多段子. 目标段子网站为"http://ishuo.cn/",我们先分析其下段子的所在子页的url特点,可以轻易发现发现为"http://ishuo.cn/subject/"+数字, 经过测试发现,该网站的反扒机制薄弱,可以轻易地爬遍其所有站点. 现在利用python的re及urllib库将其所有段子扒下 import sys import re import urllib