R语言之xlsx包读写Excel数据的操作
感谢Adrian A. Drǎgulescu发布的xlsx包
xlsx包提供了必要的工具来与Excel 2007进行交互。用户可以阅读和编写xlsx,并可以通过设置数据格式、字体、颜色和边框来控制电子表格的外观。设置打印区域,缩放控制,创建分割和冻结面板,添加页眉和页脚。包使用Apache POI项目中的java库。本篇主要分享利用xlsx工具包在读写xlsx过程中所碰到的问题及解决办法。
工具准备
强烈建议大家使用RStudio这个IDE,它是以今为止对R语言最友好的一个IDE之一,而且使用很方便。特别是在新包下载安装的时候,只需请求要安装的包名,RStudio会自动将关联的其他包也一并下载并安装。
安装R、安装RStudio;
一个简单的示例数据(本次以iris鸢尾花数据为例);
下载安装xlsx(Rstudio会同步下载并安装rJava, xlsxjars两个包);
> # 下载并安装xlsx包
> install.packages("xlsx")
> library(xlsx)
【基础】简单读取excel文件数据
假如是csv或txt等文本类的数据文件,利用R内置函数read.csv()与read.table()就可读取(注意编码格式的参数设置)。Excel由于使用范围最广,很多问题不可避免,因此,xlsx包提供了专门读取xlsx的函数read.xlsx和read.xlsx2,为什么有两个呢?请看以下区别:
| 函数 | 参数 |
|---|---|
| xlsx::read.xlsx() | file, sheetIndex, sheetName=NULL, rowIndex=NULL,startRow=NULL,endRow=NULL, colIndex=NULL,as.data.frame=TRUE, header=TRUE, colClasses=NA,keepFormulas=FALSE, encoding=“unknown”, password=NULL, … |
| xlsx::read.xlsx2() | file, sheetIndex, sheetName=NULL, startRow=1,colIndex=NULL, endRow=NULL, as.data.frame=TRUE, header=TRUE,colClasses=“character”, password=NULL, … |
其实只是细微的差别,大家自己体会即可。下面给个参考案例:
> # 指定file和sheetIndex(或sheetName),即可定位到相应的工作表
> data1 <- read.xlsx("iris.xlsx",sheetIndex = 1)
> head(data1)
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
【基础】简单写入数据到excel文件
切莫用R内置函数read.csv()与read.table()去生成xlsx文件,会有你意想不到的麻烦,还是采用专业的包来解决问题吧。 xlsx包同样提供了两个写入数据的函数write.xlsx()和write.xlsx2(),其中细微区别自行参透(注意参数 ...)。
| 函数 | 参数 |
|---|---|
| xlsx::write.xlsx() | x, file, sheetName=“Sheet1”, col.names=TRUE, row.names=TRUE, append=FALSE, showNA=TRUE, password=NULL |
| xlsx::write.xlsx2() | x, file, sheetName=“Sheet1”,col.names=TRUE, row.names=TRUE, append=FALSE, password=NULL, ... |
下面是参考案例:
># 指定x待写入数据,file生成的文件名,row.names为false则不生成行名,指定sheet工作表名为Sheet1 >write.xlsx(iris, file = "iris.xlsx", row.names = FALSE, sheetName = "Sheet1")
想必会有人在这里踩坑,大家应该注意到有一个append的参数,是否认为将其值设置为TRUE的话,就可以多次向表中写入数据?那就真踩坑了。查看xlsx包中的注释也很模糊:
> # a logical value indicating if x should be appended to an existing file. > # 翻译:一个逻辑值,指示是否应该将x附加到现有文件中
附加到现有文件中,实际上是增加新的sheet,而非在原有sheet工作表中继续增加数据。如需在同一个sheet工作表中多次增加数据,请继续往下看。
【进阶】随心所欲读取excel中的各种信息
说随心所欲 一点不夸张,不仅可以取出excel中的数据,还能识别excel单元格的样式(包括颜色、字体、大小、标注、数据类型等等)。其原理与数据库有点相似,先是定义一个工作簿的对象,再基于工作簿定义里面的工作表,进而逐级查询。下面进行详细介绍:
【样例数据】文件名:iris10.xlsx。
声明一个工作簿对象
> # loadWorkbook(file, password=NULL) #用于声明一个工作簿对象
> # 提醒:如果excel文件不在工作空间内,file最好指定为绝对路径
> wb <- createWorkbook("iris10.xlsx")
检索工作簿中的sheet
> # sheets <- getSheets(wb) #用于生成一个list对象,其中包含所有工作表的信息,数据类型为rJava::jobjRef,在此不深入讲解 > sheets <- getSheets(wb)
定位目标sheet
> # 本例只有一个sheet,名称为“Sheet1” > sheet <- sheets[["Sheet1"]] # sheet的数据类型为rJava::jobjRef
读取数据【方法一】
上面read.xlsx()方法能够将整个sheet工作表的数据读取出来,在这里提供另一种方法,不过相对麻烦一点,使用的是xlsx::readColumns()函数
| 函数 | 参数 |
|---|---|
| xlsx::readColumns() | sheet,startColumn,endColumn,startRow,endRow=NULL,as.data.frame=TRUE,header=TRUE, colClasses=NA, … |
| xlsx::readRows() | sheet, startRow, endRow, startColumn, endColumn=NULL |
xlsx::readRows()使用起来比较麻烦,不如xlsx::readColumns()好用,有兴趣的可自行研究一下。另外还有两个函数,用于定位表内数据第一行和最后一行的索引(这里与Java的性质一致,从0开始算起)
| 函数 | 参数 |
|---|---|
| getFirstRowNum() | 无参。该函数必须基于sheet对象 |
| getLastRowNum() | 无参。该函数必须基于sheet对象 |
xlsx::readRows()使用起来比较麻烦,不如xlsx::readColumns()好用,有兴趣的可自行研究一下。另外还有两个函数,用于定位表内数据第一行和最后一行的索引(这里与Java的性质一致,从0开始算起)
| 函数 | 参数 |
|---|---|
| getFirstRowNum() | 无参。该函数必须基于sheet对象 |
| getLastRowNum() | 无参。该函数必须基于sheet对象 |
下面以xlsx::readColumns()为例获取数据:
> # 该函数必须提供数据的起始列索引值、终止列索引值、起始行索引值、终止行索引值;
> dataTmp <- readColumns(sheet, startColumn = 1, endColumn = 10,
startRow = sheet$getFirstRowNum()+1, endRow = sheet$getLastRowNum()+1,
header = T, as.data.frame=TRUE)
as.data.frame=TRUE决定了输出结果为一个数据框。
缺点:在不清楚数据结构的情况下,首行和末行索引值可以求得,但列数一般难以确定,可能导致列缺失或生成多余的列
读取数据【方法二】
另一种方法相对【方法一】要好一点,先是将所有单元格的值获取出来,再生成数据框。(稍微复杂一点)
| 函数 | 参数 | 注释 |
|---|---|---|
| xlsx::getRows() | sheet, rowIndex=NULL | 用于获取sheet的每一行数据,返回值list,数据类型为rJava::jobjRef |
| xlsx::getCells() | row, colIndex=NULL, simplify=TRUE | 用于获取行内每个单元格的数据,返回值list,数据类型为rJava::jobjRef |
| xlsx::getCellValue() | cell, keepFormulas=FALSE, encoding=“unknown” | 用于获取所有单元格的值,返回值list,数据类型为character,长度为数据表m*n |
注意:这里连同标题行也作为单元格数据一并获取,并且如果有null值的单元格,会跳过该单元格
> # 获取cells进而获取values > cells <- sheet %>% getRows() %>% getCells() > values <- lapply(cells,getCellValue)
values获取出来就如下面这个样子,你会发现value的名称向量,每个值都包含了所在单元格的x、y坐标值。
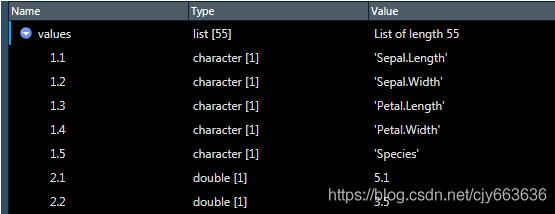
> names(values) #查看values的名称向量 [1] "1.1" "1.2" "1.3" "1.4" "1.5" "2.1" "2.2" "2.3" "2.4" "2.5" "3.1" "3.2" "3.3" "3.4" "3.5" "4.1" [17] "4.2" "4.3" "4.4" "4.5" "5.1" "5.2" "5.3" "5.4" "5.5" "6.1" "6.2" "6.3" "6.4" "6.5" "7.1" "7.2" [33] "7.3" "7.4" "7.5" "8.1" "8.2" "8.3" "8.4" "8.5" "9.1" "9.2" "9.3" "9.4" "9.5" "10.1" "10.2" "10.3" [49] "10.4" "10.5" "11.1" "11.2" "11.3" "11.4" "11.5"
将这些坐标值拆分出来,作为等会重排数据的索引
> addresses <- sapply(names(values),FUN = function(x) str_split(string = x,pattern = "[.]"))
接下来就只需要将其进行重排,形成数据框即可。
> datas.name <- vector(mode = "character") #声明一个空的向量,用来存放标题
> datas <- data.frame() # 声明一个空的数据框,用来存放目标数据
> # 用sapply代替for做循环,避免占用大量内存。同时注意sapply使用时的环境问题,用.GlobalEnv指向最外层环境的变量。
> # 这里只对数据进行重排,无需进行计算,所以invisible不显示计算结果
> invisible(sapply(addresses,FUN = function(x) {
+ if (x[1] == "1") {
+ .GlobalEnv$datas.name = c(.GlobalEnv$datas.name,.GlobalEnv$values[[1]])
+ .GlobalEnv$values[[1]] <- NULL
+ } else {
+ .GlobalEnv$datas[x[1],x[2]] <- .GlobalEnv$values[[1]]
+ .GlobalEnv$values[[1]] <- NULL
+ }
+ }))
> names(datas) <- datas.name #最后在添加标题
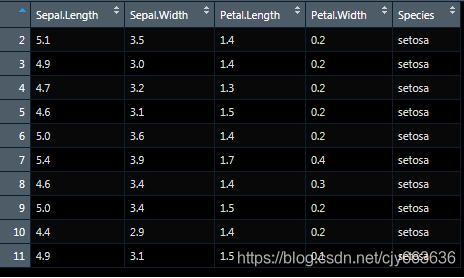
> View(datas)
得到结果与原excel数据一致
获取单元格样式与获取数据的方式一致,这里不再增加过多篇幅讲解,只做简单介绍。以下函数按函数名字面理解。
| 函数 | 参数 |
|---|---|
| xlsx::CellStyle() | wb, dataFormat=NULL, alignment=NULL,border=NULL, fill=NULL, font=NULL, cellProtection=NULL |
| xlsx::setCellStyle() | cell, cellStyle |
| xlsx::getCellStyle() | cell |
| xlsx::createCellComment() | cell, string="", author=NULL, visible=TRUE |
| getCellComment() | cell |
| removeCellComment() | cell |
其他函数后续如有机会,再做详细介绍吧。
【进阶】随心所欲将数据写入excel文件
我想大家更想看到的就是这部分内容了。确实在日常处理数据时,将数据存储到excel中进行传递是常有的事,谁叫excel是微软亲生的呢。闲话少说,直入正题。
前面基础篇通过write.xlsx()函数将数据写入excel文件中,同时指定sheet名称。但这种写入是一次性的,即一次写入多少就多少。在工作簿里面新增sheet工作表用append控制,但在同个sheet上继续写入数据,会报错:
> write.xlsx(datas,file = "iris10.xlsx",sheetName = "Sheet1",row.names = F,append = T) Error in .jcall(wb, "Lorg/apache/poi/ss/usermodel/Sheet;", "createSheet", : java.lang.IllegalArgumentException: The workbook already contains a sheet of this name
说是这个名称的sheet已经存在同名的了!
这次我们采用高级一点的方法,跟前面进阶读取数据一样,先是定义一个工作簿的对象,再创建或加载sheet工作表。
| 函数 | 参数 | 注释 |
|---|---|---|
| xlsx::createWorkbook() | type=“xlsx” | 用于生成一个新的excel工作簿 |
| xlsx::loadWorkbook() | file, password=NULL | 用于加载当前已存在的excel工作簿 |
| xlsx::saveWorkbook() | wb, file, password=NULL | 使用完必须保存工作簿 |
| xlsx::createSheet() | wb, sheetName=“Sheet1” | 用于生成一个新的sheet工作表 |
| xlsx::removeSheet() | wb, sheetName=“Sheet1” | 用于删除工作表 |
| xlsx::getSheets() | wb | 用于获取当前工作簿里的工作表清单,返回值是list |
| xlsx::addDataFrame() | x, sheet, col.names=TRUE, row.names=TRUE,startRow=1, | 用于获取当前工作簿里的工作表清单,返回值是list |
| (续上) | startColumn=1,colStyle=NULL, colnamesStyle=NULL,rownamesStyle=NULL, showNA=FALSE, characterNA="", byrow=FALSE |
前面讲过如何加载已有工作簿,这里以生成新excel工作簿为例,将数据写入文件中
> wb <- xlsx::createWorkbook() > sheets <- getSheet() # 新生成的工作簿没有sheet,系统提示:Workbook has no sheets! > sheet <- createSheet(wb,sheetName = "newSheet1")
此时R内存中已经生成了一个工作簿,包含一个空的sheet工作表,通过addDataFrame()函数将数据写入sheet中.
> # 用上面生成的datas数据框对象,取前4行数据写入当前sheet对象中 > addDataFrame(data[1:4,],sheet,row.names = F) > saveWorkbook(wb,file = "iris_new.xlsx")
==记得保存工作簿、记得保存工作簿、记得保存工作簿==
如果是在已有excel工作簿上操作,这里最好做一个判断,避免覆盖现有数据,造成不必要的麻烦。如果当前sheet的最后一行索引不等于零(说明有数据),则将新数据写到最后一行数据的下一行,同时不加入列名行(col.names = FALSE);如果为零则将数据直接添加到sheet中。
> # 用上面生成的datas数据框对象,取前4行数据写入当前sheet对象中
> if (sheet$getLastRowNum() != 0) {
+ addDataFrame(data[1:4,],sheet,row.names = F,col.names = F,startRow = sheet$getLastRowNum() + 2)
+ } else {
+ addDataFrame(data[1:4,],sheet,row.names = F)
+ }
+ }
> saveWorkbook(wb,file = "iris_new.xlsx")
至此,你应该知道如何在原有工作表基础上新增数据行了吧?多么方便!!
如果要增加新的sheet工作表,只需将sheet重新定义一个新的sheetName即可。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言数据读取以及数据保存方式
一.R语言读取文本文件: 1.文件目录操作: getwd() : 返回当前工作目录 setwd("d:/data") 更改工作目录 2.常用的读取指令read read.table() : 读取文本文件 read.csv(): 读取csv文件 如果出现缺失值,read.table()会报错,read.csv()读取时会自动在缺失的位置填补NA 3.灵活的读取指令 scan() : 4.读取固定宽度格式的文件: read.fwf() 文本文档中最后一行的回车符很重要,这是一个类似于停止符
-
r语言-如何将数据标准化和中心化
中心化和标准化意义一样,都是消除量纲的影响 中心化:数据-均值 标准化:(数据-均值)/标准差 数据中心化: scale(data,center=T,scale=F) 数据标准化: scale(data,center=T,scale=T) 或默认参数scale(data) scale方法中的两个参数center和scale的解释: 1.center和scale默认为真,即T或者TRUE 2.center为真表示数据中心化 3.scale为真表示数据标准化 补充:R语言对数据进行标准化处理 有时候
-
R语言变量级别的数据处理操作
变量级别的数据处理无非是对变量的增删改查. 增 即增加新的变量 R语言中,增加一个新变量形式语句如下: 变量名 <- 表达式 表达式可以包含多种运算符和函数.常见运算符包括: 运算符 描述 + 加 - 减 * 乘 / 除 ^或** 求幂 x%%y 求余(x mod y).5%%2的结果为1. x%/%y 整数除法.5%/%2的结果为2. 示例: #创建一个数据框 mydata <- data.frame(x1 = c(2,2,6,4), + x2 = c(3,4,2,8)) mydata x1
-
R语言-如何定义数据框的列名
1.在定义数据框时,定义列名: 例如: a<-c(2,23,45,6,7,1,6,7) b<-c(4,6,1,2,5,66,10,2) df<-data.frame(a,b) 此时数据框df中的列名分别是a.b 也可以如下: df<-data.frame(a1=a,b1=b) 此时的列名是a1.b1 2.修改数据框中列的名字 如果希望修改数据框中的列名,可以使用name函数进行修改 例如: names(df)<-c("a2","b2")
-
R语言实现用cbind合并两列数据
我有两个数据文件,分别只有一列,这两列数据行数一行,我想把这两列合并到一个数据文件中,方便使用. 我的两个数据文件分别是1.txt,2.txt,保存后的文件名是3.txt. // 代码如下 gow1<-read.table("1.txt",header = FALSE) gow2<-read.table("2.txt",header = FALSE) View(gow1) View(gow2) gow<-cbind(gow1,gow2) View(
-
R语言-使用ifelse进行数据分组
数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来研究,以揭示内在的联系和规律性: 在R中,我们常用ifelse函数来进行数据的分组,跟excel中的if函数是同一种用法. ifelse(condition,TRUE,FALSE) > data <- read.table('1.csv', sep='|', header=TRUE); > > level <- ifelse( + data$cost<=20, "(0,2
-
R语言关于数据帧的知识点详解
数据帧是表或二维阵列状结构,其中每一列包含一个变量的值,并且每一行包含来自每一列的一组值. 以下是数据帧的特性. 列名称应为非空. 行名称应该是唯一的. 存储在数据帧中的数据可以是数字,因子或字符类型. 每个列应包含相同数量的数据项. 创建数据帧 # Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle&
-
R语言-进行数据的重新编码(recode)操作
在分析数据时我们经常会遇到将变量值转换成其他的值的情况(如:将连续变量转成分类变量)这时就需要我们对原有数据进行重新编码.本文将介绍R软件中常用的三种重编吗方法: 1.使用逻辑判断式编码. 2.使用cut函数编码. 3.使用car程序包的recode函数. (一)使用逻辑判断式 (1)现假设我们需要将下面的连续型变量x按照10与20分成三个组,新的分组名称为1.2.3: > x2=1*(x<=10)+2*(x>10&x<=20)+3*(x>20) > x2 [1
-
R语言之xlsx包读写Excel数据的操作
感谢Adrian A. Drǎgulescu发布的xlsx包 xlsx包提供了必要的工具来与Excel 2007进行交互.用户可以阅读和编写xlsx,并可以通过设置数据格式.字体.颜色和边框来控制电子表格的外观.设置打印区域,缩放控制,创建分割和冻结面板,添加页眉和页脚.包使用Apache POI项目中的java库.本篇主要分享利用xlsx工具包在读写xlsx过程中所碰到的问题及解决办法. 工具准备 强烈建议大家使用RStudio这个IDE,它是以今为止对R语言最友好的一个IDE之一,而且使用很
-
R语言使用cgdsr包获取TCGA数据示例详解
目录 TCGA数据源 TCGA数据库探索工具 查看任意数据集的样本列表方式 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据 选定样本列表获取临床信息 综合性获取 下载mRNA数据 获取病例列表的临床数据 从cBioPortal下载点突变信息 从cBioPortal下载拷贝数变异数据 把拷贝数及点突变信息结合画热图 TCGA数据源 众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有: DNA Sequencing miRNA Sequencing P
-
R语言利用caret包比较ROC曲线的操作
说明 我们之前探讨了多种算法,每种算法都有优缺点,因而当我们针对具体问题去判断选择那种算法时,必须对不同的预测模型进行重做评估. 为了简化这个过程,我们使用caret包来生成并比较不同的模型与性能. 操作 加载对应的包与将训练控制算法设置为10折交叉验证,重复次数为3: library(ROCR) library(e1071) library("pROC") library(caret) library("pROC") control = trainControl(
-
python读写excel数据--pandas详解
目录 一.读写excel数据 1.1 读: 1.2写: 二.举例 2.1 要求 2.2 实现 总结 一.读写excel数据 利用pandas可以很方便的读写excel数据 1.1 读: data_in = pd.read_excel('M2FENZISHI.xlsx') 1.2写: 首先要创建数据框 # example df = pd.DataFrame({'A':[0,1,2]}) writer = pd.ExcelWriter('test.xlsx') #name of excel file
-
详解R语言图像处理EBImage包
目录 什么是EBImage 1. 图像读取与保存 2.色彩管理 3.图像处理 4.空间变换 5.形态运算 6.图像分割 本文摘自<Keras深度学习:入门.实战及进阶>第四章部分章节. 什么是EBImage EBImage是R的一个扩展包,提供了用于读取.写入.处理和分析图像的通用功能,非常容易上手.EBImage包在Bioconductor中,通过以下命令进行安装. install.packages("BiocManager") BiocManager::install(
-
R语言学习VennDiagram包绘制韦恩图示例
目录 引言 一 需要安装和导入的包 二 使用函数及参数 三 知道各个数据集的个数以及重叠(交叉)的个数 2.1 两个已知数据集的韦恩图 2.2 三个已知数据集的韦恩图 四 根据数据集合绘制韦恩图 4.1 四个数据集合 4.2 五个数据集合 引言 本版块会持续分享一些常用的结果展示的图形. 在得到数据之后,我们经常会用到维恩图来展示各个数据集之间的重叠关系.本文简单的介绍R语言中的VennDiagram包绘制数据集的维恩图. 一 需要安装和导入的包 install.packages("VennDi
-
R语言入门教程之删除指定数据的方法
引言 在R学习中经常用到的是按着某种逻辑值提取数据集.本文来讲一下利用索引的手法删除数据集合. 数据准备 > Data 英雄 职业 熟练等级 使用频次 胜率 1 后裔 射手 5 856 0.64 2 孙尚香 射手 5 211 0.10 3 狄仁杰 射手 5 324 0.20 4 李元芳 射手 4 75 0.30 5 安琪拉 法师 5 2324 0.40 6 张良 法师 4 755 0.50 7 不知火舞 法师 4 644 0.60 8 貂蝉 法师 3 982 0.70 9 <NA> &l
-
如何改变R语言默认存储包的路径
怎么更改R中包的存储路径呢? 方法一 可以在R里面用如下命令 .libPaths("C:/Program Files/R/R-3.3.1/library") 方法二 在安装某一个包得时候用如下命令 install.packages("thepackage",lib="/path/to/directory/with/libraries") 补充:如何永久改变R中 .libPaths()?R语言修改 libPath包的储存路径 写在前面 我们有时候新
-
R语言ggplot2拼图包patchwork安装使用
目录 引言 安装 例子 高级特性 引言 patchwork是基于ggplot2的拼图包,因为ggplot2本身没有强大的拼图语法,而一般使用的gridExtra与cowplot的拼ggplot2图形都存在不少问题. 我关注这个包蛮久了,现在Github上的Star数已经远超大部分的R包,但似乎还没有发布到CRAN.我的工作看似跟作图相关,写的博文大多数也如此,但实际对图形的掌控力并不咋的,所以还是要多多学习. 下面进入正题,掌握好ggplot2与patchwork的基本用法,一般的图形都可以搞定
-
R语言与格式,日期格式,格式转化的操作
R语言的基础包中提供了两种类型的时间数据,一类是Date日期数据,它不包括时间和时区信息,另一类是POSIXct/POSIXlt类型数据,其中包括了日期.时间和时区信息. 基本总结如下: 日期data,存储的是天: 时间POSIXct 存储的是秒,POSIXlt 打散,年月日不同: 日期-时间=不可运算. 一般来讲,R语言中建立时序数据是通过字符型转化而来,但由于时序数据形式多样,而且R中存贮格式也是五花八门,例如Date/ts/xts/zoo/tis/fts等等.lubridate包(后续有介