聊聊Python pandas 中loc函数的使用,及跟iloc的区别说明
loc和iloc的意思
首先,loc是location的意思,和iloc中i的意思是指integer,所以它只接受整数作为参数,详情见下面。
loc和iloc的区别及用法展示
1.区别
loc works on labels in the index. iloc works on the positions in the index (so it only takes integers).
2.用法展示
首先创建一个dataframe:

1)loc为Selection by Label函数,即为按标签取数据,标签是什么,就是上面的'0'~‘4', ‘A'~‘B'。
例如第一个参数选择index,第二个参数选择column,如下图:

建议写df.loc[0, :],这样可以清楚的看出为第0行的所有记录,同样如果取第'A'列的所有记录,可以写df.loc[:, ‘A'],如下图:

:表示所有,[]里边为先行后列。
2)iloc函数为Selection by Position,即按位置选择数据,即第n行,第n列数据,只接受整型参数
记住,0:2为左闭右开区间,即取0,1,如下图:
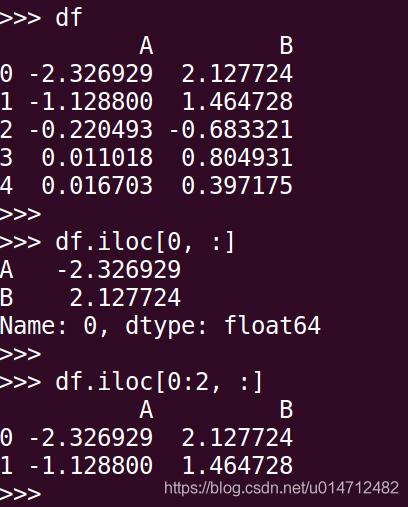
若要取第一列的所有数据,则为df.iloc[:, 0],记住不接受'A'作为参数,如下图:

补充:只需一个例子帮你搞清并记住python loc和iloc
帮你区分python loc和iloc
最基本的概念loc通常用于行标签和列标签,iloc通常直接用于行序号和列序号,具体举个例子帮助大家理解。
创建一个以abcd为索引,四行三列的Dataframe。
df = pd.DataFrame({'number':[10,20,30,20],
'科目':['语文','数学','英语','化学'],
'名称':['小米','华为','苹果','联想']},index=['a','b','c','d'])
print(df)
结果如图所示 :

先来看loc:
print(df.loc['a':'c']) print(df.loc[['a','c']]) print(df.loc[:'c'])
分别输出a行到c行;a行和c行;a行到c行。
如图所示:

还可以设置取出某几行某几列:
print(df.loc[:'c',['number','科目']])
结果如下图所示:取出a到c行的number和科目列。
如下图所示:

loc基本用法就这些。实际上iloc用法和loc差不多,但iloc不是直接取已有索引。而是默认索引就是1,2,3,4~~~
同样的我们用iloc做下上述操作。
print(df.iloc[0:3]) print(df.iloc[[0,2]]) print(df.iloc[:3])
结果同样如上图所示:

用iloc取出a到c行的number和科目列:
print(df.iloc[0:3,[0,1]])
结果如下图所示:

我相信读到这里大家应该就理解了它们的用法。最后再提醒大家一下,loc不管行还是列调用的都是Dataframe自身的行标签和列标签。
而iloc调用的是行[1,2,3,4~],列[1,2,3,4]。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
python pandas.DataFrame选取、修改数据最好用.loc,.iloc,.ix实现
相信很多人像我一样在学习python,pandas过程中对数据的选取和修改有很大的困惑(也许是深受Matlab)的影响... 到今天终于完全搞清楚了!!! 先手工生出一个数据框吧 import numpy as np import pandas as pd df = pd.DataFrame(np.arange(0,60,2).reshape(10,3),columns=list('abc')) df 是这样子滴 那么这三种选取数据的方式该怎么选择呢? 一.当每列已有column name时,用
-
python选取特定列 pandas iloc,loc,icol的使用详解(列切片及行切片)
df是一个dataframe,列名为A B C D 具体值如下: A B C D 0 ss 小红 8 1 aa 小明 d 4 f f 6 ak 小紫 7 dataframe里的属性是不定的,空值默认为NA. 一.选取标签为A和C的列,并且选完类型还是dataframe df = df.loc[:, ['A', 'C']] df = df.iloc[:, [0, 2]] 二.选取标签为C并且只取前两行,选完类型还是dataframe df = df.loc[0:2, ['A', 'C']] df
-

聊聊Python pandas 中loc函数的使用,及跟iloc的区别说明
loc和iloc的意思 首先,loc是location的意思,和iloc中i的意思是指integer,所以它只接受整数作为参数,详情见下面. loc和iloc的区别及用法展示 1.区别 loc works on labels in the index. iloc works on the positions in the index (so it only takes integers). 2.用法展示 首先创建一个dataframe: 1)loc为Selection by Label函数,即为
-
python pandas中索引函数loc和iloc的区别分析
目录 前言 1.直接使用行或者列标签 2.loc函数 3.iloc函数 总结 前言 使用pandas进行数据分析的时候,我们经常需要对DataFrame的行或者列进行索引.使用pandas进行索引的方法主要有三种:直接使用行或者列标签.loc函数和iloc函数. 举个简单的例子: import numpy as np import pandas as pd df = pd.DataFrame({"Fruits":["apple","pear",&
-
Python Pandas中loc和iloc函数的基本用法示例
目录 1 loc和iloc的含义 2 用法 2.1 loc函数的用法 2.2 iloc函数的用法 补充:Pandas中loc和iloc函数实例 总结 1 loc和iloc的含义 loc表示location的意思:iloc中的loc意思相同,前面的i表示integer,所以它只接受整数作为参数. 2 用法 import pandas as pd import numpy as np # np.random.randn(5, 2)表示返回5x2的矩阵,index表示行的编号,columns表示列的编
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python Pandas中合并数据的5个函数使用详解
目录 join 索引一致 索引不一致 merge concat 纵向拼接 横向拼接 append combine 前几天在一个群里面,看到一位朋友,说到自己的阿里面试,被问了一些关于pandas的使用.其中一个问题是:pandas中合并数据的5中方法. 今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数.但是对于每个函数,我这里不打算详细说明,具体用法大家可以参考pandas官当文档. join主要用于基于索引的横向合并拼接: merge主要用于基于指定列的横向合并拼接: con
-
详谈pandas中agg函数和apply函数的区别
在利用python进行数据分析 这本书中其实没有明确表明这两个函数的却别,而是说apply更一般化. 其实在这本书的第九章'数组及运算和转换'点到了两者的一点点区别:agg是用来聚合运算的,所谓的聚合当然是合成的成分比较大些,这一节开头就点到了:聚合只不过是分组运算的其中一种而已.它是数据转换的一个特例,也就是说,它接受能够将一维数组简化为标量值的函数. 当然这两个函数都是作用在groupby对象上的,也就是分完组的对象上的,分完组之后针对某一组,如果值是一维数组,在利用完特定的函数之后,能做到
-
Python Pandas中根据列的值选取多行数据
Pandas中根据列的值选取多行数据 # 选取等于某些值的行记录 用 == df.loc[df['column_name'] == some_value] # 选取某列是否是某一类型的数值 用 isin df.loc[df['column_name'].isin(some_values)] # 多种条件的选取 用 & df.loc[(df['column'] == some_value) & df['other_column'].isin(some_values)] # 选取不等于某些值的
-
对python pandas中 inplace 参数的理解
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改 inplace = True:不创建新的对象,直接对原始对象进行修改: inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果. 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似. 例: inplace=True情况: import pandas as pd import numpy as np df=pd.DataFrame(np.rand