Python机器学习应用之基于天气数据集的XGBoost分类篇解读
目录
- 一、XGBoost
- 1 XGBoost的优点
- 2 XGBoost的缺点
- 二、实现过程
- 1 数据集
- 2 实现
- 三、Keys
- XGBoost的重要参数
一、XGBoost
XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。
1 XGBoost的优点
- 简单易用。相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。
- 高效可扩展。在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。
- 鲁棒性强。相对于深度学习模型不需要精细调参便能取得接近的效果。
- XGBoost内部实现提升树模型,可以自动处理缺失值。
2 XGBoost的缺点
- 相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
- 在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。
二、实现过程
1 数据集
2 实现
#%%导入基本库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
#读取数据
data=pd.read_csv('D:\Python\ML\data\XGBtrain.csv')
通过variable explorer查看样本数据

也可以使用head()或tail()函数,查看样本前几行和后几行。不难看出,数据集中含有NAN,代表数据中存在缺失值,可能是在数据采集或者处理过程中产生的一种错误,此处采用-1将缺失值进行填充,还有其他的填充方法:
- 中位数填补
- 平均数填补
注:在数据的前期处理中,一定要注意对缺失值的处理。前期数据处理的结果将会严重影响后面是否可能得到合理的结果
data=data.fillna(-1) #利用value_counts()函数查看训练集标签的数量(Raintomorrow=no) print(pd.Series(data['RainTomorrow']).value_counts()) data_des=data.describe()
填充后:

#%%#可视化数据(特征值包括数字特征和非数字特征) numerical_features = [x for x in data.columns if data[x].dtype == np.float] category_features = [x for x in data.columns if data[x].dtype != np.float and x != 'RainTomorrow'] #%% 选取三个特征与标签组合的散点可视化 sns.pairplot(data=data[['Rainfall','Evaporation','Sunshine'] + ['RainTomorrow']], diag_kind='hist', hue= 'RainTomorrow') plt.show()

#%%每个特征的箱图
i=0
for col in data[numerical_features].columns:
if col != 'RainTomorrow':
plt.subplot(2,8,i+1)
sns.boxplot(x='RainTomorrow', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
i=i+1
plt.show()

#%%非数字特征
tlog = {}
for i in category_features:
tlog[i] = data[data['RainTomorrow'] == 'Yes'][i].value_counts()
flog = {}
for i in category_features:
flog[i] = data[data['RainTomorrow'] == 'No'][i].value_counts()
#%%不同地区下雨情况
plt.figure(figsize=(20,10))
plt.subplot(1,2,1)
plt.title('RainTomorrow')
sns.barplot(x = pd.DataFrame(tlog['Location']).sort_index()['Location'], y = pd.DataFrame(tlog['Location']).sort_index().index, color = "red")
plt.subplot(1,2,2)
plt.title('Not RainTomorrow')
sns.barplot(x = pd.DataFrame(flog['Location']).sort_index()['Location'], y = pd.DataFrame(flog['Location']).sort_index().index, color = "blue")
plt.show()

#%%
plt.figure(figsize=(20,5))
plt.subplot(1,2,1)
plt.title('RainTomorrow')
sns.barplot(x = pd.DataFrame(tlog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(tlog['RainToday'][:2]).sort_index().index, color = "red")
plt.subplot(1,2,2)
plt.title('Not RainTomorrow')
sns.barplot(x = pd.DataFrame(flog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(flog['RainToday'][:2]).sort_index().index, color = "blue")
plt.show()

XGBoost无法处理字符串类型的数据,需要将字符串数据转化成数值
#%%对离散变量进行编码
## 把所有的相同类别的特征编码为同一个值
def get_mapfunction(x):
mapp = dict(zip(x.unique().tolist(),
range(len(x.unique().tolist()))))
def mapfunction(y):
if y in mapp:
return mapp[y]
else:
return -1
return mapfunction
#将非数字特征离散化
for i in category_features:
data[i] = data[i].apply(get_mapfunction(data[i]))
#%%利用XGBoost进行训练与预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)
data_target_part = data['RainTomorrow']
data_features_part = data[[x for x in data.columns if x != 'RainTomorrow']]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
#%%导入XGBoost模型
from xgboost.sklearn import XGBClassifier
## 定义 XGBoost模型
clf = XGBClassifier()
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)
#%% 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the XGBoost is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the XGBoost is:',metrics.accuracy_score(y_test,test_predict))
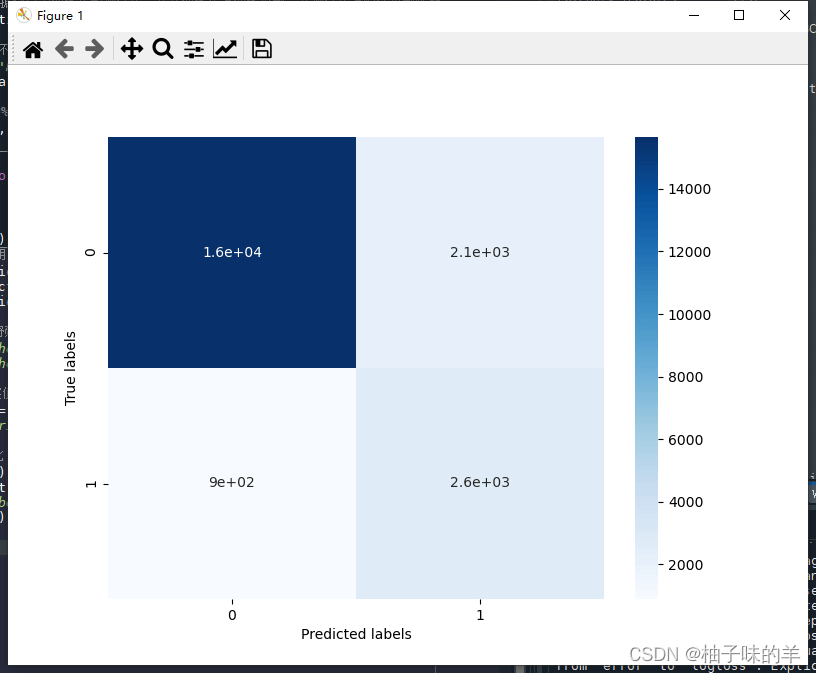
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
#%%利用XGBoost进行特征选择: #XGboost中可以用属性feature_importances_去查看特征的重要度。 sns.barplot(y=data_features_part.columns,x=clf.feature_importances_)

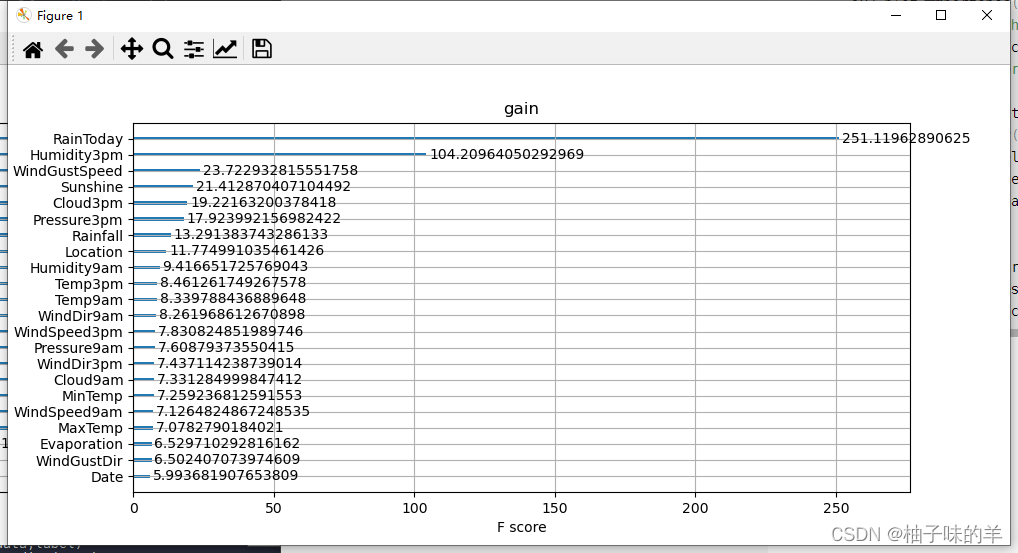
初次之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性:
- weight:是以特征用到的次数来评价
- gain:当利用特征做划分的时候的评价基尼指数
- cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。
- total_gain:总基尼指数
- total_cover:总覆盖
#利用XGBoost的其他重要参数评估特征的重要性
from sklearn.metrics import accuracy_score
from xgboost import plot_importance
def estimate(model,data):
#sns.barplot(data.columns,model.feature_importances_)
ax1=plot_importance(model,importance_type="gain")
ax1.set_title('gain')
ax2=plot_importance(model, importance_type="weight")
ax2.set_title('weight')
ax3 = plot_importance(model, importance_type="cover")
ax3.set_title('cover')
plt.show()
def classes(data,label,test):
model=XGBClassifier()
model.fit(data,label)
ans=model.predict(test)
estimate(model, data)
return ans
ans=classes(x_train,y_train,x_test)
pre=accuracy_score(y_test, ans)
print('acc=',accuracy_score(y_test,ans))



XGBoost中包括但不限于下列对模型影响较大的参数:
- learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。
- subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合, 取值范围零到一。
- colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。
- max_depth越大,模型学习的更加具体。
调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果
#%%通过调参获得更好的效果
## 从sklearn库中导入网格调参函数
from sklearn.model_selection import GridSearchCV
## 定义参数取值范围
learning_rate = [0.1, 0.3, 0.6]
subsample = [0.8, 0.9]
colsample_bytree = [0.6, 0.8]
max_depth = [3,5,8]
parameters = { 'learning_rate': learning_rate,
'subsample': subsample,
'colsample_bytree':colsample_bytree,
'max_depth': max_depth}
model = XGBClassifier(n_estimators = 50)
## 进行网格搜索
clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=1,n_jobs=-1)
clf = clf.fit(x_train, y_train)
#%%网格搜索后的参数
print(clf.best_params_)

#%% 在训练集和测试集上分别利用最好的模型参数进行预测
## 定义带参数的 XGBoost模型
clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9)
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()


三、Keys
XGBoost的重要参数
- eta【默认0.3】:通过为每一颗树增加权重,提高模型的鲁棒性。典型值为0.01-0.2。
- min_child_weight【默认1】:决定最小叶子节点样本权重和。这个参数可以避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,则会导致模型拟合不充分。
- max_depth【默认6】:这个值也是用来避免过拟合的,max_depth越大,模型会学到更具体更局部的样本。典型值:3-10
- max_leaf_nodes:树上最大的节点或叶子的数量。可以替代max_depth的作用。这个参数的定义会导致忽略max_depth参数。
- gamma【默认0】:在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。
- max_delta_step【默认0】:这个参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。但是当各类别的样本十分不平衡时,它对分类问题是很有帮助的。
- subsample【默认1】:这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。典型值:0.5-1
- colsample_bytree【默认1】:用来控制每棵随机采样的列数的占比(每一列是一个特征)。典型值:0.5-1
- colsample_bylevel【默认1】:用来控制树的每一级的每一次分裂,对列数的采样的占比。subsample参数和colsample_bytree参数可以起到相同的作用,一般用不到。
- lambda【默认1】:权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
- alpha【默认1】:权重的L1正则化项。(和Lasso regression类似)。可以应用在很高维度的情况下,使得算法的速度更快。
- scale_pos_weight【默认1】:在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
886~~
到此这篇关于Python机器学习应用之基于天气数据集的XGBoost分类篇解读的文章就介绍到这了,更多相关Python XGBoost内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输
-
python机器学习之神经网络(二)
由于Rosenblatt感知器的局限性,对于非线性分类的效果不理想.为了对线性分类无法区分的数据进行分类,需要构建多层感知器结构对数据进行分类,多层感知器结构如下: 该网络由输入层,隐藏层,和输出层构成,能表示种类繁多的非线性曲面,每一个隐藏层都有一个激活函数,将该单元的输入数据与权值相乘后得到的值(即诱导局部域)经过激活函数,激活函数的输出值作为该单元的输出,激活函数类似与硬限幅函数,但硬限幅函数在阈值处是不可导的,而激活函数处处可导.本次程序中使用的激活函数是tanh函数,公式如下: tan
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
Python机器学习应用之基于LightGBM的分类预测篇解读
目录 一.Introduction 1 LightGBM的优点 2 LightGBM的缺点 二.实现过程 1 数据集介绍 2 Coding 三.Keys LightGBM的重要参数 基本参数调整 针对训练速度的参数调整 针对准确率的参数调整 针对过拟合的参数调整 一.Introduction LightGBM是扩展机器学习系统.是一款基于GBDT(梯度提升决策树)算法的分布梯度提升框架.其设计思路主要集中在减少数据对内存与计算性能的使用上,以及减少多机器并行计算时的通讯代价 1 LightGBM
-
python机器学习之神经网络
手写数字识别算法 import pandas as pd import numpy as np from sklearn.neural_network import MLPRegressor #从sklearn的神经网络中引入多层感知器 data_tr = pd.read_csv('BPdata_tr.txt') # 训练集样本 data_te = pd.read_csv('BPdata_te.txt') # 测试集样本 X=np.array([[0.568928884039633],[0.37
-
python机器学习之神经网络(三)
前面两篇文章都是参考书本神经网络的原理,一步步写的代码,这篇博文里主要学习了如何使用neurolab库中的函数来实现神经网络的算法. 首先介绍一下neurolab库的配置: 选择你所需要的版本进行下载,下载完成后解压. neurolab需要采用python安装第三方软件包的方式进行安装,这里介绍一种安装方式: (1)进入cmd窗口 (2)进入解压文件所在目录下 (3)输入 setup.py install 这样,在python安装目录的Python27\Lib\site-packages下,就可
-
python机器学习之神经网络实现
神经网络在机器学习中有很大的应用,甚至涉及到方方面面.本文主要是简单介绍一下神经网络的基本理论概念和推算.同时也会介绍一下神经网络在数据分类方面的应用. 首先,当我们建立一个回归和分类模型的时候,无论是用最小二乘法(OLS)还是最大似然值(MLE)都用来使得残差达到最小.因此我们在建立模型的时候,都会有一个loss function. 而在神经网络里也不例外,也有个类似的loss function. 对回归而言: 对分类而言: 然后同样方法,对于W开始求导,求导为零就可以求出极值来. 关于式子中
-
python机器学习实现神经网络示例解析
目录 单神经元引论 参考 多神经元 单神经元引论 对于如花,大美,小明三个因素是如何影响小强这个因素的. 这里用到的是多元的线性回归,比较基础 from numpy import array,exp,dot,random 其中dot是点乘 导入关系矩阵: X= array ( [ [0,0,1],[1,1,1],[1,0,1],[0,1,1]]) y = array( [ [0,1,1,0]]).T ## T means "transposition" 为了满足0到1的可能性,我们采用
-
python机器学习之神经网络(一)
python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干个突触的输入求和后进行调节.为了便于观察,这里的数据采用二维数据. 目标函数是训练结果的误差的平方和,由于目标函数是一个二次函数,只存在一个全局极小值,所以采用梯度下降法的策略寻找目标函数的最小值. 代码如下: import numpy
-
Python机器学习应用之基于天气数据集的XGBoost分类篇解读
目录 一.XGBoost 1 XGBoost的优点 2 XGBoost的缺点 二.实现过程 1 数据集 2 实现 三.Keys XGBoost的重要参数 一.XGBoost XGBoost并不是一种模型,而是一个可供用户轻松解决分类.回归或排序问题的软件包. 1 XGBoost的优点 简单易用.相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果. 高效可扩展.在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高. 鲁棒性强.相对于深度学习模型不需要精细调参便能取得接近的
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要