Python采集电视剧《开端》弹幕做成词云图
目录
- 知识点介绍
- 环境介绍
- 网站分析
- 完整爬虫代码实现
- 结果展示
- 总结

知识点介绍
爬虫基本思路流程
requests模块的使用
pandas保存表格数据
pyecharts做词云图可视化
环境介绍
python 3.8
pycharm
requests >>> pip install requests
pyecharts >>> pip install pyecharts
网站分析
打开X讯视频的网页,点开《开端》,播放视频,弹幕随之出现再屏幕之上。
首先我们需要找到相应的弹幕出自于哪里,打开网页开发者工具,Ctrl+F输入:“那么多座位你俩非要挤一起吗”,找到弹幕所在的页面
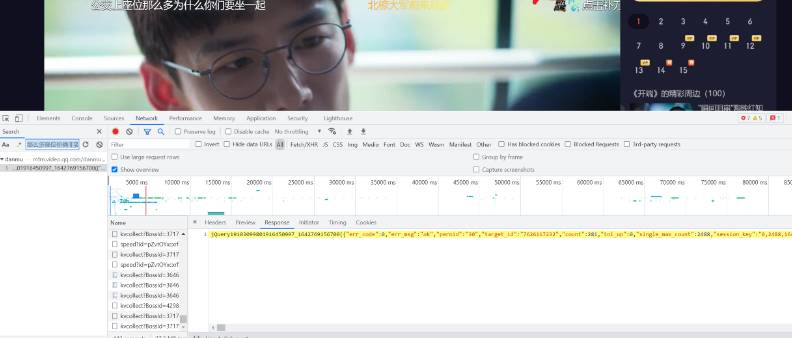
观察发现这是一个json,其弹幕内容包含在该json中的comments之中

找到页面之后观察该页面的请求头,请求方式为get,target_id为该电视剧的网页ID,得到该电视剧的链接地址主要由target_id和timestamp时间戳构成,形如 http://mfm.video.qq.com/danmu?timestamp=0&target_id=xxxxx 且该json表明时间戳每30会更新一次弹幕信息,单位为秒,对网站进行分析之后,我们直接看到代码。
完整爬虫代码实现
timestamp每增加30就会更改整个弹幕页面,在循环中每次增加30,并更改target_id即电视剧的每一集来获取每一集的弹幕信息,下面便是编写的获取弹幕的函数。这里以第一集为例子。
import requests
import pandas as pd
# 构建一个列表存储数据
data_set = []
for page in range(15, 600, 30):
try:
# 1. 发送请求
url = f'https://mfm.video.qq.com/danmu?otype=json&target_id=7626117232%26vid%3Dn0041aa087e&session_key=0%2C0%2C0×tamp={page}&_=1641804763748'
response = requests.get(url=url)
# 2. 获取数据
json_data = response.json()
# 3. 解析数据
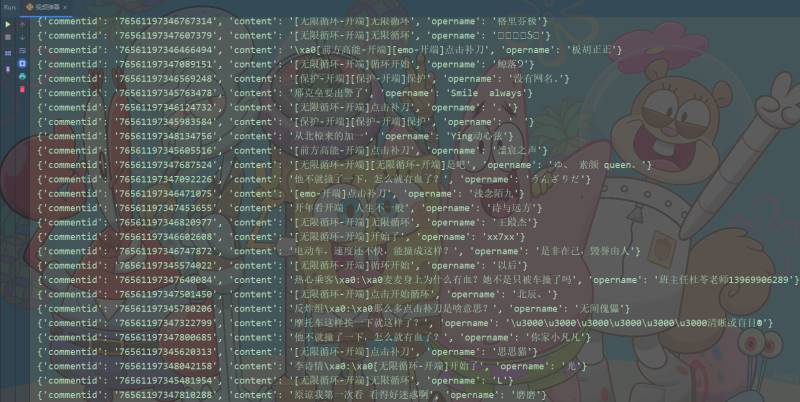
comments = json_data['comments']
for comment in comments:
data_dict = {}
data_dict['commentid'] = comment['commentid']
data_dict['content'] = comment['content']
data_dict['opername'] = comment['opername']
print(data_dict)
data_set.append(data_dict)
except:
pass
# 4. 保存数据
df = pd.DataFrame(data_set)
df.to_csv('data.csv', index=False)
结果展示
word = dfword3['word'].tolist()
count = dfword3['count'].tolist()
a = [list(z) for z in zip(word, count)]
c = (
WordCloud()
.add('', a, word_size_range=[10, 50], shape='circle')
.set_global_opts(title_opts=opts.TitleOpts(title="词云图"))
)
c.render_notebook()

总结
到此这篇关于Python采集电视剧《开端》弹幕做成词云图的文章就介绍到这了,更多相关Python词云图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现爬取某站视频弹幕并绘制词云图
目录 前言 爬取弹幕 爬虫基本思路流程 导入模块 代码 制作词云图 导入模块 读取弹幕数据 前言 [课 题]: Python爬取某站视频弹幕或者腾讯视频弹幕,绘制词云图 [知识点]: 1. 爬虫基本流程 2. 正则 3. requests >>> pip install requests 4. jieba >>> pip install jieba 5. imageio >>> pip install imageio 6. wordcloud >
-
python如何用pyecharts制作词云图
需要安装pyecharts pip install pyecharts -U 创建[demo6.py]并输入以下编码: from pyecharts import options as opts from pyecharts.charts import Page, WordCloud words = [ ("神医", 10000), ("马良", 6181), ("玛丽", 4386), ("终结者", 4055), (&qu
-
Python控制浏览器自动下载歌词评论并生成词云图
目录 一.前言 二.准备工作 1.需要用的模块 2.驱动安装 三.下载歌词 四.词云图 一.前言 一首歌热门了,参与评论的人也很多,那我们有时候想看看评论,也只能看看热门的评论,大部分人都说的什么,咱也不知道呀~ 那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析… 二.准备工作 1.需要用的模块 本次用到的模块和包: re # 正则表达式 内置模块 selenium # 实现浏览器自动操作的 jieba # 中文分词库 wordcloud # 词云图库 imageio
-
Python pyecharts绘制词云图代码
目录 一.pyecharts绘制词云图WordCloud.add()方法简介 二.绘制词云图对应轮廓按diamond显示 三.对应完整代码如下所示 一.pyecharts绘制词云图WordCloud.add()方法简介 WordCloud.add()方法简介: add(name,attr,value, shape="circle", word_gap=20, word_size_range=None, rotate_step=45) name str 图例名称 attr list 属性
-
Python selenium把歌词评论做成词云图
目录 前言 本次目的 本次用到的模块和包: 驱动安装 一.下载歌曲评论 1.代码实现 2.爬取评论运行效果 二.制作词云图 总结 前言 一首歌热门了,参与评论的人也很多,这时无论好坏评论都来了,没有人控评得话,指不定乱七八糟 但是自己有喜欢看评论,不想影响好心情,想看看精彩评论,看看歌词立意,那怎么办呢? 那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析… 本次目的 用selenium自动把歌词评论下载下来,做成好看的词云图 本次用到的模块和包: re # 正则表达式 内置模块
-
Python采集电视剧《开端》弹幕做成词云图
目录 知识点介绍 环境介绍 网站分析 完整爬虫代码实现 结果展示 总结 知识点介绍 爬虫基本思路流程 requests模块的使用 pandas保存表格数据 pyecharts做词云图可视化 环境介绍 python 3.8 pycharm requests >>> pip install requests pyecharts >>> pip install pyecharts 网站分析 打开X讯视频的网页,点开<开端>,播放视频,弹幕随之出现再屏幕之上. 首先
-
用Python采集《雪中悍刀行》弹幕做成词云实例
目录 前言 知识点介绍 环境介绍 代码实现 1. 导入模块 2. 发送网络请求 3. 获取数据 弹幕内容 4. 解析数据(筛选数据) 提取想要的一些内容 不想要的忽略掉 5. 保存数据 6. 词云图可视化 总结 前言 最近已经播完第一季的电视剧<雪中悍刀行>,从播放量就可以看出观众对于这部剧的期待,总播放量达到50亿,可让人遗憾的是,豆瓣评分只有5.7,甚至都没有破6. 很多人会把这个剧和<庆余年>做对比,因为主创班底相同 400余万字的同名小说曾被捧为网文界里的“名著”,不少粉丝
-
利用Python爬取微博数据生成词云图片实例代码
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意.有一个创意是把她过往发的微博整理后用词云展示出来.本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来.下面话不多说了,来一起看看详细的介绍吧. 准备工作
-
Python通过文本和图片生成词云图
使用现有的txt文本和图片,就可以用wordcloud包生成词云图.大致步骤是: 1.读取txt文本并简单处理: 2.读取图片,以用作背景: 3.生成词云对象,保存为文件. 需要用到3个库:jieba(用于分割文本为词语).imageio(用于读取图片).wordcloud(功能核心,用于生成词云). 我用简历和我的照片,生成了一个词云图: 代码如下: import jieba import imageio import wordcloud # 读取txt文本 with open('resume
-
Python爬取哆啦A梦-伴我同行2豆瓣影评并生成词云图
一.前言 通过这篇文章,你将会收货: ① 豆瓣电影数据的爬取: ② 手把手教你学会词云图的绘制: 二.豆瓣爬虫步骤 当然,豆瓣上面有很多其他的数据,值得我们爬取后做分析.但是本文我们仅仅爬取评论信息. 待爬取网址: https://movie.douban.com/subject/34913671/comments?status=P 由于只有一个字段,我们直接使用re正则表达式,解决该问题. 那些爬虫小白看过来,这又是一个你们练手的好机会. 下面直接为大家讲述爬虫步骤: # 1. 导入相关库,用
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5