C++或Go求矩阵里的岛屿的数量详解
目录
- 1、C++实现
- 2、go语言实现
- 参考文献
- 总结
给你一个由 ‘1'(陆地)和 ‘0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:
grid = [
[“1”,“1”,“1”,“1”,“0”],
[“1”,“1”,“0”,“1”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“0”,“0”,“0”]
]
输出:
1
示例 2:
输入:
grid = [
[“1”,“1”,“0”,“0”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“1”,“0”,“0”],
[“0”,“0”,“0”,“1”,“1”]
]
输出:
3
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 300
grid[i][j] 的值为 ‘0' 或 ‘1'
此孤岛问题,可以通过DFS算法解决,具体如下:
1、C++实现
//island.cpp
#include <iostream>
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
//判断坐标(r,c)是否存在网络中
bool inArea(vector<vector<char>>& grid, int r, int c) {
bool bRow = (r >= 0) && (r < (int)grid.size());
bool bCol = (c >= 0) && (c < (int)grid[0].size());
return bRow && bCol;
}
//void dfs(int[][] grid, int r, int c) {
void dfs(vector<vector<char>>& grid, int r,int c){
//判断base case
//如果坐标(r,c)超出了网格范围,则直接返回
if (!inArea(grid,r,c)) {
return;
}
//如果不是岛屿,则直接返回
if (grid[r][c] != '1') {
return;
}
//将原来的"1"改成"0"
grid[r][c] = '2';
//访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r , c-1);
dfs(grid, r , c+1);
}
//求岛屿的个数
//时间复杂度:O(MN)O(MN),其中 MM 和 NN 分别为行数和列数。
//空间复杂度:O(MN)O(MN),在最坏情况下,整个网格均为陆地,深度优先搜索的深度达到MN。
//
int numIslands(vector<vector<char>>& grid){
int r = grid.size();
if (!r)
return 0;
int c = grid[0].size();
int num = 0;
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
if (grid[i][j] == '1') {
++num;
dfs(grid, i, j);
}
}
}
return num;
}
int main(){
//岛屿
// 1 1 1
// 0 1 0
// 1 0 0
// 1 0 1
vector<char> row1;
row1.push_back('1');
row1.push_back('1');
row1.push_back('1');
vector<char> row2;
row2.push_back('0');
row2.push_back('1');
row2.push_back('0');
vector<char> row3;
row3.push_back('1');
row3.push_back('0');
row3.push_back('0');
vector<char> row4;
row4.push_back('1');
row4.push_back('0');
row4.push_back('1');
vector<vector<char>> grid;
grid.push_back(row1);
grid.push_back(row2);
grid.push_back(row3);
grid.push_back(row4);
int numLands = numIslands(grid);
cout << "numLands= " << numLands << endl;
system("pause");
return 0;
}
效果如下:
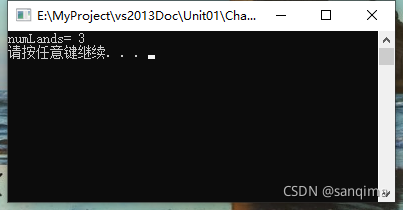
图(1) 孤岛的个数
2、go语言实现
//island.go
package main
import "fmt"
func numIslands(grid [][]byte) int {
nums := 0
for i:=0; i<len(grid); i++ {
for j:=0; j<len(grid[0]); j++ {
if grid[i][j] == '1' {
DFS(&grid,i,j)
nums++
}
}
}
return nums
}
func DFS(grid *[][]byte, i int, j int) {
var (
row = len(*grid)
col = len((*grid)[0])
)
if i<0 || i>=row || j<0 || j>= col {
return
}
if (*grid)[i][j] == '1' {
(*grid)[i][j] = '2'
DFS(grid,i-1,j)
DFS(grid,i+1,j)
DFS(grid,i,j-1)
DFS(grid,i,j+1)
}
}
func main() {
var grid = make([][]byte, 4)
grid[0] = []byte{'1','1','1'}
grid[1] = []byte{'0','1','0'}
grid[2] = []byte{'1','0','0'}
grid[3] = []byte{'1','0','1'}
res := numIslands(grid)
fmt.Println("numlands=",res)
}
效果如下:
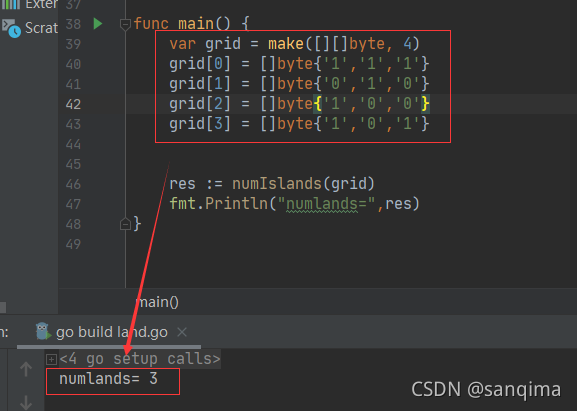
图(2) go语言实现,求岛屿的个数
参考文献
来源:力扣(LeetCode)
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
c++如何控制对象的创建方式(禁止创建栈对象or堆对象)和创建的数量
我们知道,C++将内存划分为三个逻辑区域:堆.栈和静态存储区.既然如此,我称位于它们之中的对象分别为堆对象,栈对象以及静态对象.通常情况下,对象创建在堆上还是在栈上,创建多少个,这都是没有限制的.但是有时会遇到一些特殊需求. 1.禁止创建栈对象 禁止创建栈对象,意味着只能在堆上创建对象.创建栈对象时会移动栈顶指针以"挪出"适当大小的空间,然后在这个空间上直接调用类的构造函数以形成一个栈对象.而当栈对象生命周期结束,如栈对象所在函数返回时,会调用其析构函数释放这个对象,然后再调整栈顶指针
-
C++实现LeetCode(200.岛屿的数量)
[LeetCode] 200. Number of Islands 岛屿的数量 Given a 2d grid map of '1's (land) and '0's (water), count the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four
-
C++ 数据结构之水洼的数量算法
C++ 数据结构之水洼的数量算法 题目: 有一个大小为N*M的园子, 雨后起了积水. 八连通的积水被认为是连接在一起的. 请求出园子里总共有多少水洼. 使用深度优先搜索(DFS), 在某一处水洼, 从8个方向查找, 直到找到所有连通的积水. 再次指定下一个水洼, 直到没有水洼为止. 则所有的深度优先搜索的次数, 就是水洼数. 时间复杂度O(8*M*N)=O(M*N). 代码: /* * main.cpp * * Created on: 2014.7.12 *本栏目更多精彩内容:http://ww
-

C++或Go求矩阵里的岛屿的数量详解
目录 1.C++实现 2.go语言实现 参考文献 总结 给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量. 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成.此外,你可以假设该网格的四条边均被水包围. 示例 1: 输入: grid = [ ["1","1","1","1","0"], ["1","1",
-
Python计算矩阵的和积的实例详解
python的numpy库提供矩阵运算的功能,因此我们在需要矩阵运算的时候,需要导入numpy的包. 一.numpy的导入和使用 from numpy import *;#导入numpy的库函数 import numpy as np; #这个方式使用numpy的函数时,需要以np.开头. 二.矩阵的创建 由一维或二维数据创建矩阵 from numpy import *; a1=array([1,2,3]); a1=mat(a1); 创建常见的矩阵 data1=mat(zeros((3,3)));
-
微信小程序引用公共js里的方法的实例详解
微信小程序引用公共js里的方法的实例详解 一个小程序页面由四个文件组成,一个小程序页面的四个文件具有相同路径与文件名,由此我们可知一个小程序页面对应着一个跟页面同名的js文件.可是当有些公共方法,我们想抽离出来成为一个独立公共的js文件.我们该如何实现呢. 在根目录下有一个app.js文件.这个根目录的js 文件我们可以通过getApp()轻松调用. //app.js App({ globaData:'huangenai' }) //test.js var app = getApp(); Pag
-
对python中矩阵相加函数sum()的使用详解
假如矩阵A是n*n的矩阵 A.sum()是计算矩阵A的每一个元素之和. A.sum(axis=0)是计算矩阵每一列元素相加之和. A.Sum(axis=1)是计算矩阵的每一行元素相加之和. 以上这篇对python中矩阵相加函数sum()的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Django对models里的objects的使用详解
首先我们先熟悉下objects的大致概念. object是模型属性---用于模型对象和数据库交互 . objects = Manager() 是管理器类型的对象 ,是Model和数据库进行查询的接口. objects : 管理器对象 是Manager类型的对象,定义在from django.db import models中 用于模型对象和数据库交互 是默认自动生成的属性,但是可以自定义管理器对象 实例: class Students(models.Model): # stuobj = mode
-
对numpy.append()里的axis的用法详解
如下所示: def append(arr, values, axis=None): """ Append values to the end of an array. Parameters ---------- arr : array_like Values are appended to a copy of this array. values : array_like These values are appended to a copy of `arr`. It mus
-
对python读取zip压缩文件里面的csv数据实例详解
利用zipfile模块和pandas获取数据,代码比较简单,做个记录吧: # -*- coding: utf-8 -*- """ Created on Tue Aug 21 22:35:59 2018 @author: FanXiaoLei """ from zipfile import ZipFile import pandas as pd myzip=ZipFile('2.zip') f=myzip.open('2.csv') df=pd.r
-
PyTorch里面的torch.nn.Parameter()详解
在看过很多博客的时候发现了一个用法self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)),首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动
-
shell 里 awk print 的用法详解
首先, 你需要先了解awk 的工作原理: 1.AWK读取输入文件一次一行. 2.对于每一行,它匹配在给定的顺序模式,如果匹配,执行相应的动作. 3.如果没有模式匹配,将执行任何行动. 4.在上面的语法,无论是搜索模式,或行动是可选的,但不能同时. 5.如果没有给出搜索模式,然后awk要执行每一行输入给定的行动. 6.如果没有给出动作,打印,这是默认的操作与模式相匹配的所有行. 7.空出的任何行动括号什么都不做.它不会执行默认的打印操作. 8.中的每个行动的声明应该用分号分隔.让我们创建emplo
-
利用Pandas求两个dataframe差集的过程详解
目录 1.交集 2.差集(df1-df2为例) 总结 1.交集 intersected=pd.merge(df1,df2,how='inner') 延伸(针对列求交集)intersected=pd.merge(df1,df2,on['name'],how='inner') 2.差集(df1-df2为例) diff=pd.concat([df1,df2,df2]).drop_duplicates(keep=False) 差集函数的详解: 1.Pandas 通过 concat() 函数能够轻松地将