pandas使用之宽表变窄表的实现
我就废话不多说了,还是直接看代码吧!
import pandas as pd
# 伪造一些数据
fake_data = {'subject':['math', 'english'],
'A': [88, 90],
'B': [70, 80],
'C': [60, 78]}
# 宽表
test = pd.DataFrame(fake_data, columns=['subject', 'A', 'B', 'C'])
test
subject A B C
0 math 88 70 60
1 english 90 80 78
# 转换为窄表
pd.melt(test, id_vars=['subject'])
subject variable value
0 math A 88
1 english A 90
2 math B 70
3 english B 80
4 math C 60
5 english C 78
补充知识:pandas从单条目数据集生成宽表
需求
场景
从医院数据库中导出了大量的体检数据,但体检数据表中,每一行代表某人某次体检的某一项体检的结果。目的想将每一个人的每一次体检结果作为一行存储,每一列为体检项。
示例
| StuID | Type | Num | |
|---|---|---|---|
| 0 | 111021 | Math | 89 |
| 1 | 111021 | English | 93 |
| 2 | 312983 | English | 91 |
| 3 | 314621 | English | 82 |
| 4 | 314621 | Math | 92 |
| 5 | 112341 | Math | 82 |
目的:转换成如下表格
| StuID | English | Math | |
|---|---|---|---|
| 0 | 111021 | 93 | 89 |
| 1 | 312983 | 91 | NaN |
| 2 | 314621 | 82 | 92 |
| 3 | 112341 | NaN | 82 |
方案一
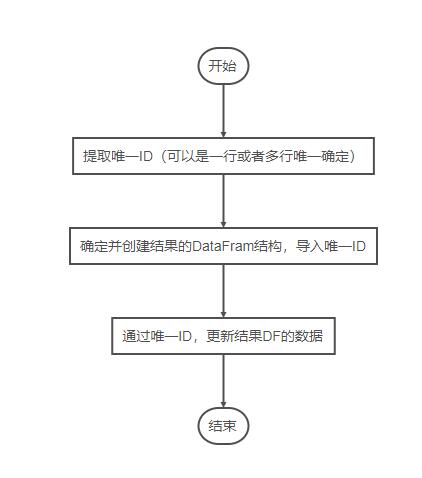
具体代码如下
#将'B'列的类别调整为行。
#1
num = df[~df.duplicated(subset=['StuID'])].loc[:,'StuID'].to_list()
#2
result_df = pd.DataFrame({'StuID': np.array(num)},columns=['StuID','English','Math'])
#3
for i in df.index:
t = df.loc[i,'Type']
num = df.loc[i,'StuID']
result_df.loc[result_df['StuID'] == num,[t]] = df.loc[i,'Num']
print(result_df)
结果

以上这篇pandas使用之宽表变窄表的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
从列表或字典创建Pandas的DataFrame对象的方法
介绍 每当我使用pandas进行分析时,我的第一个目标是使用众多可用选项中的一个将数据导入Pandas的DataFrame . 对于绝大多数情况下,我使用的 read_excel , read_csv 或 read_sql . 但是,有些情况下我只需要几行数据或包含这些数据里的一些计算. 在这些情况下,了解如何从标准python列表或字典创建DataFrames会很有帮助. 基本过程并不困难,但因为有几种不同的选择,所以有助于理解每种方法的工作原理. 我永远记不住我是否应该使用 from_dic
-

Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容,经常需要记住它的使用语法.所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析. 如果你对这个概念不熟悉,wikipedia上对它做了详细的解释.顺便说一下,你知道微软为PivotTable(透视表)注册了商标吗?其实以前我也不知道.不用说,下面我将讨论
-
Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
pandas使用之宽表变窄表的实现
我就废话不多说了,还是直接看代码吧! import pandas as pd # 伪造一些数据 fake_data = {'subject':['math', 'english'], 'A': [88, 90], 'B': [70, 80], 'C': [60, 78]} # 宽表 test = pd.DataFrame(fake_data, columns=['subject', 'A', 'B', 'C']) test subject A B C 0 math 88 70 60 1 engl
-
利用Python的pandas数据处理包将宽表变成窄表
目录 前言 1.引入包 3.关键操作,将宽表转换为窄表 4.对空值进行处理 5.导出存储到Excel中 前言 工作中经常会使用到将宽表变成窄表,例如这样的形式 编号 编码 单位1 单位2 单位3 单位4 ... ... ... ... ... ... 1 编码1... 数量... 数量... 数量... 数量... ... ... ... ... ... ... 2 编码2... 数量... 数量... 数量... 数量... ... ... ... ... ... ..
-
sqlserver中查询横表变竖表的sql语句简析
首先是三张表, CNo对应的是课程,在这里我就粘贴了. 主表 人名表 按照常规查询 SELECT s.SName, c.CName,s2.SCgrade FROM S s INNER JOIN SC s2 ON s2.SNo = s.SNo INNER JOIN C c ON c.CNo = s2.CNo 那么结果是这样的 但是这是横表 不是我想看到的结果. 我们要看到这样的结果: 那么怎么办呢?第一种写法: 复制代码 代码如下: SELECT w.SName, sum(
-
Pandas数据分析之pandas数据透视表和交叉表
目录 前言 整理透视 pivot 聚合透视 Pivot Table 聚合透视高级操作 交叉表crosstab() 数据融合melt() 数据堆叠 stack 前言 pandas对数据框也可以像excel一样进行数据透视表整合之类的操作.主要是针对分类数据进行操作,还可以计算数值型数据,去满足复杂的分类数据整理的逻辑. 首先还是导入包: import numpy as np import pandas as pd 整理透视 pivot 首先介绍的是最简单的整理透视函数pivot,其原理如图: pi
-
pandas实现excel中的数据透视表和Vlookup函数功能代码
在孩子王实习中做的一个小工作,方便整理数据. 目前这几行代码是实现了一个数据透视表和匹配的功能,但是将做好的结果写入了不同的excel中, 如何实现将结果连续保存到同一个Excel的同一个工作表中? 还需要探索. import pandas as pd import numpy as np a = [1601,1602,1603,1604,1605,1606,1607,1608,1609,1610,1611,1612,1701,1702,1703,1704] for i in a: b = st
-
Win2000注册表应用—注册表使用全攻略之九
Win2000注册表应用-注册表使用全攻略之九 一.修改开始菜单和任务栏 此次更改的注册表项目是在HKEY_CURRENT_USER下的,如果只想针对某一用户则只需要修改HKEY_USERS\用户代码(比如S-1-5-21-448539723-113007714-842925246-1000) 下的相应键值就可以了. 1.禁止开始菜单上的上下拖动 HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Policies\Explor
-
Oracle 数据显示 横表转纵表
1.建表 复制代码 代码如下: -- Create table create table test ( dm1 char(3), dm2 char(3), mc1 nvarchar2(20), val nvarchar2(20) ) 2.填入数据如下: DM1 DM2 MC1 VAL 101 1 c1 100 101 1 c2 80 101 1 c3 40 101 2 c1 30 101 2 c2 80 102 4 c1 9 102 6 c2 50 转换后数据显示如下: DM1 DM2 c1 c
-
MySql创建带解释的表及给表和字段加注释的实现代码
1 创建带解释的表 CREATE TABLE groups( gid INT PRIMARY KEY AUTO_INCREMENT COMMENT '设置主键自增', gname VARCHAR(200) COMMENT '列注释' ) COMMENT='表注释'; 2 修改现有列,加上解释 alter table test_data modify column test_desc int comment 'xxxx'; 3 修改现有表,加上解释 ALTER TABLE test_data
-
MySQL查看表和清空表的常用命令总结
查看MySQL数据库表 进入MySQL Command line client下 查看当前使用的数据库: mysql>select database(); mysql>status; mysql>show tables; mysql>show databases;//可以查看有哪些数据库,返回数据库名(databaseName) mysql>use databaseName; //更换当前使用的数据库 mysql>show tables; //返回当前数据库下的所有表的
-
Oracle删除表及查看表空间的实例详解
Oracle常用的基本命令 --1.用户下表中注释模糊查询: 例如查询与优惠券关联的表 SELECT * FROM user_tab_comments t WHERE t.comments LIKE '%优惠券%'; ![这里写图片描述](http://img.blog.csdn.net/20170321112728053?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMDQyNzkzNQ==/font/5a6L5L2T/fontsize/40