Python修改列表值问题解决方案
由于惯性思维,导致使用for循环修改列表中的值出现问题
首次尝试:
def make_great(original):
for magician in original:
magician = "the Great " + magician
magicians = ["david", "tom", "jimmy"]
make_great(magicians)
show_magicians(magicians)
运行结果
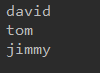
显然列表中的值并没有改变。
思考:for语句定义一个变量进行遍历,但只是访问当前值。操作列表中的值正确方法是使用下标。
修改后:
def make_great(original):
j = len(original)
for i in range(0, j):
original[i] = "the Great " + original[i]
运行结果

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python中利用numpy.array()实现俩个数值列表的对应相加方法
小编想把用python将列表[1,1,1,1,1,1,1,1,1,1] 和 列表 [2,2,2,2,2,2,2,2,2,2]对应相加成[3,3,3,3,3,3,3,3,3,3]. 代码如下: import numpy a = numpy.array([1,1,1,1,1,1,1,1,1,1]) b = numpy.array([2,2,2,2,2,2,2,2,2,2]) c = a + b print(type(c)) print(list(c)) 输出结果为: <class 'numpy.nd
-
python实现字典嵌套列表取值
如下所示: dict={'log_id': 5891599090191187877, 'result_num': 1, 'result': [{'probability': 0.9882395267486572, 'top': 205, 'height': 216, 'classname': 'Face', 'width': 191, 'left': 210}]} 访问dict的值: print(dict['log_id']) 访问dict下的result列表的值: print(dict['re
-
python列表切片和嵌套列表取值操作详解
给出列表切片的格式: [开头元素::步长] # 输出直到最后一个元素,(最后一个冒号和步长可以省略,下同) [开头元素:结尾元素(不含):步长] # 其中,-1表示list最后一个元素 首先来看最简单的单一列表: a = [1,2,3,4] a[:] a[::] a[:3] a[1:3:2] a[3] 输出依次为: [1,2,3,4] [1,2,3,4] [1,2,3] [2] 4 注意,这里只有最后一个输出是不带[]的,表明只有最后一个输出是元素,其他在切片中只用了:符号的输出均为list,不
-
Python递归求出列表(包括列表中的子列表)的最大值实例
要求:求出列表中的所有值的最大数,包括列表中带有子列表的. 按照Python给出的内置函数(max)只能求出列表中的最大值,无法求出包括列表中的子列表的最大值 Python3代码如下: #!/usr/bin/env python3 # _*_ coding:UTF-8 _*_ list_tmp = [1,3,5,7,9,11] print(max(list_tmp)) 返回的结果为:11 按照Python3给出内置函数(max)的方法想要违和他的要求求出列表包括子列表的数,他就会给你进行报错.
-
在Python中使用filter去除列表中值为假及空字符串的例子
在 Python中,认为以下值为假: None # None值 False # False值 0 # 数值零不管它是int,float还是complex类型 '',(),[] # 任何一个空的序列 {} # 空的集合 如果一个列表中含上面值为假的元素,要去除的话,可以使用内置函数的filter默认的参数None. 可以先看下filter内置函数的帮助文档 >>> help(filter) Help on built-in function filter in module __built
-
python找出列表中大于某个阈值的数据段示例
该算法实现对列表中大于某个阈值(比如level=5)的连续数据段的提取,具体效果如下: 找出list里面大于5的连续数据段: list = [1,2,3,4,2,3,4,5,6,7,4,6,7,8,5,6,7,3,2,4,4,4,5,3,6,7,8,9,8,6,1] 输出: [[6, 7], [6, 7, 8], [6, 7], [6, 7, 8, 9, 8, 6]] 算法实现: # -*- coding: utf-8 -*- """ --------------------
-
Python字典中的值为列表或字典的构造实例
1.值为列表的构造实例 dic = {} dic.setdefault(key,[]).append(value) *********示例如下****** >>dic.setdefault('a',[]).append(1) >>dic.setdefault('a',[]).append(2) >>dic >>{'a': [1, 2]} 2.值为字典的构造实例 dic = {} dic.setdefault(key,{})[value] =1 *******
-
Python修改列表值问题解决方案
由于惯性思维,导致使用for循环修改列表中的值出现问题 首次尝试: def make_great(original): for magician in original: magician = "the Great " + magician magicians = ["david", "tom", "jimmy"] make_great(magicians) show_magicians(magicians) 运行结果 显然列
-
Python实现对excel文件列表值进行统计的方法
本文实例讲述了Python实现对excel文件列表值进行统计的方法.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding=gbk #此PY用来统计一个execl文件中的特定一列的值的分类 import win32com.client filename=raw_input("请输入要统计文件的详细地址:") flag=0 #用于判断文件 名如果不带'日'就为 0 if '\xc8\xd5' in filename:flag=1 print 50*'
-
python DataFrame 修改列的顺序实例
假设我有一个DataFrame(df)如下: name age id mike 10 1 tony 14 2 lee 20 3 现在我想把id 放到最前面,变成: id name age df_id = df.id df = df.drop('id',axis=1) df.insert(0,'id',df_id) 以上这篇python DataFrame 修改列的顺序实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python中datet
-
python pandas修改列属性的方法详解
使用astype如下: df[[column]] = df[[column]].astype(type) type即int.float等类型. 示例: import pandas as pd data = pd.DataFrame([[1, "2"], [2, "2"]]) data.columns = ["one", "two"] print(data) # 当前类型 print("----\n修改前类型:&quo
-
Python修改DBF文件指定列
一.需求: 某公司每日收到一批DBF文件,A系统实时处理后将其中dealstat字段置为1(已处理).现在每日晚间B系统也需要处理该文件,因此需将文件中dealstat字段修改为空(未处理). 二.分析: 1.应创建副本进行修改 解答:使用shutil.copy 2.修改DBF 解答:使用dbf模块.此模块能找到的文档比较旧,需要结合代码进行理解. 三.代码实现: #!/usr/bin/env python # _*_ coding:utf-8 _*_ """ @Time :
-

用python修改excel表某一列内容的操作方法
想想你在一家公司里做表格,现在有一个下面这样的excel表摆在你面前,这是一个员工每个月工资的表, 现在假设,你要做的事情,是填充好后面几个月每个员工的编号,并且给员工随机生成一个2000到50000之间的随机数作为该月的工资,能拿多少全靠天意,你为了锻炼自己的python能力决定写一个相关的代码: 1 库引入 首先要引入库函数,要修改excel内容首先需要有openpyxl这个库,要生成随机数就要有random这个库 import openpyxl import random 2 提取cell
-
超全面python常见报错以及解决方案梳理必收藏
AttribteError: 'module' object has no attribute xxx' 描述:模块没有相关属性.可能出现的原因: 1.命名.py文件时,使用了Python保留字或者与模块名等相同. 解决:修改文件名 2.pyc文件中缓存了没有更新的代码. 解决:删除该库的.pyc 文件 AttributeError: 'Obj' object has no attribute 'attr' 描述:对象没有相关属性.可能出现的原因: 1.Python内置对象没有属性. 解决:去除
-
Python修改Excel数据的实例代码
在前面的文章中介绍了如何用Python读写Excel数据,今天再介绍一下如何用Python修改Excel数据.需要用到xlutils模块.下载地址为https://pypi.python.org/pypi/xlutils.下载后执行python setup.py install命令进行安装即可.具体使用代码如下: 复制代码 代码如下: #-*-coding:utf-8-*-from xlutils.copy import copy # http://pypi.python.org/pypi
-
python查看列的唯一值方法
查看某一列中有多少中取值: 数据集名.drop_duplicates(['列名']) #实际为删除重复项,删除后对原数据集不修改 输入:data.drop_duplicates(['name']) 输出: 1 zhangsan 2 lisi 3 wangwu 以上这篇python查看列的唯一值方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python修改linux中文件(文件夹)的权限属性操作
今天生成的对流云团路径图片放在linux下,文件的权限都是rw,没有x,后续的别人的程序调用不了,这里附上对三个属性的简单解释,有不够的欢迎大家补充 Linux的权限不是很细致,只有RWX三种 r(Read,读取):对文件而言,具有读取文件内容的权限:对目录来说,具有浏览目录的权限. w(Write,写入):对文件而言,具有新增,修改,删除文件内容的权限:对目录来说,具有新建,删除,修改,移动目录内文件的权限. x(eXecute,执行):对文件而言,具有执行文件的权限:对目录了来说该用户具有进