python使用nb_log模块捕获日志的方法
目录
- 一、调研日志模块
- 二、nb_log模块的使用
- 1、安装方式
- 2、自动跳转功能
- 3、屏幕流日志效果
- 4、将日志写入文件
- 5、总结
一、调研日志模块
我想写一个日志模块,首选是python内置的logging模块,接着查找外部的第三方模块,一眼看到我们中国人写的模块nb_log。估计是”牛逼的日志“,这不得不说相当”严谨“。倒也符合我的口味,pypi的地址如下:
nb-log · PyPIvery sharp color display,monkey patch bulitin print and high-performance multiprocess safe roating file handler,other handlers includeing dintalk ,email,kafka,elastic and so on
https://pypi.org/project/nb-log/
怎么说呢?模块介绍的全文相当口水话,看起来相当业余,吹牛成分极大,但非常符合我的口味!物以类聚大概说的就是这事,不信你看该官方描述(只是冰山一角):

文章中还有许多对比,比如将其他模块或者一些博客文章直接拉出来枪毙,看起来极其嚣张,哪个中枪就不说了,反正很符合我的口味!现在就按照”官方文档“去使用吧!
二、nb_log模块的使用
1、安装方式
pip install nb_log
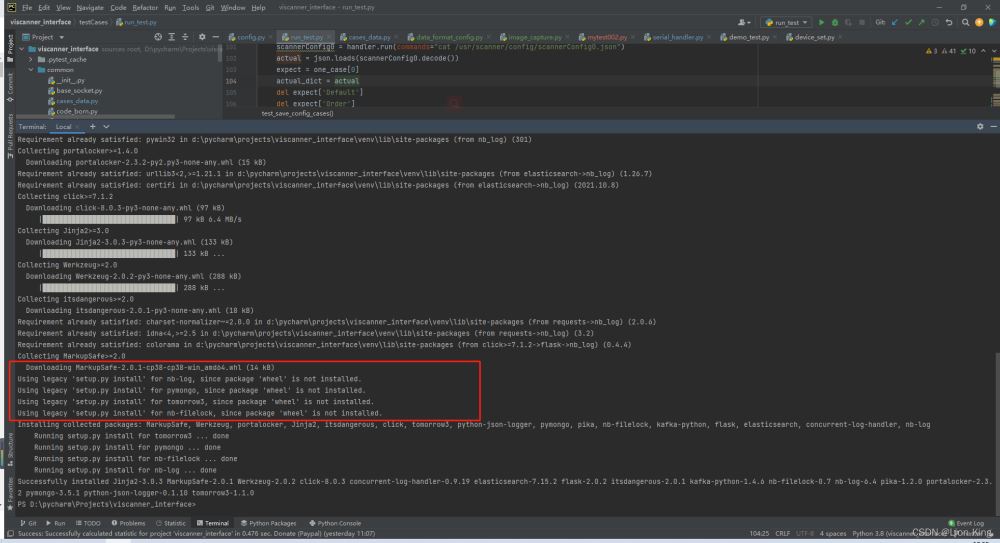
如下图,安装过程中还有些安装不成功的提示,不过最后万事大吉:
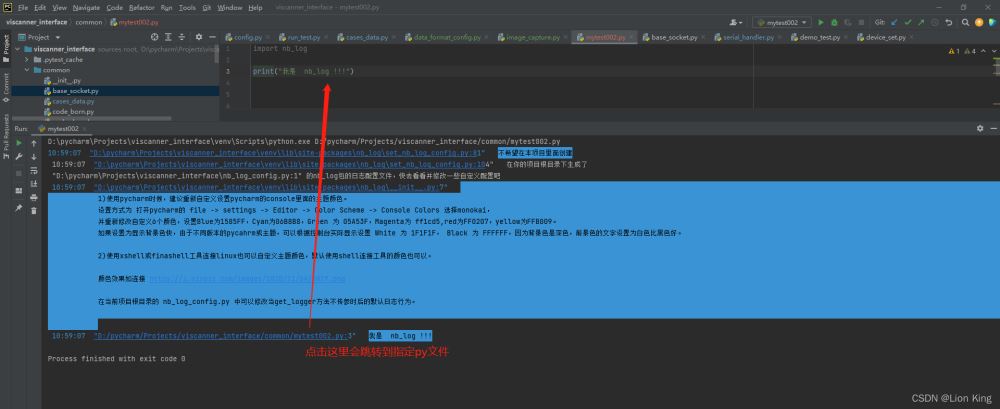
2、自动跳转功能
如图所示,对print()也会进行跳转,因为作者喜欢日志,不喜欢print()。
import nb_log
print("我是 nb_log !!!")
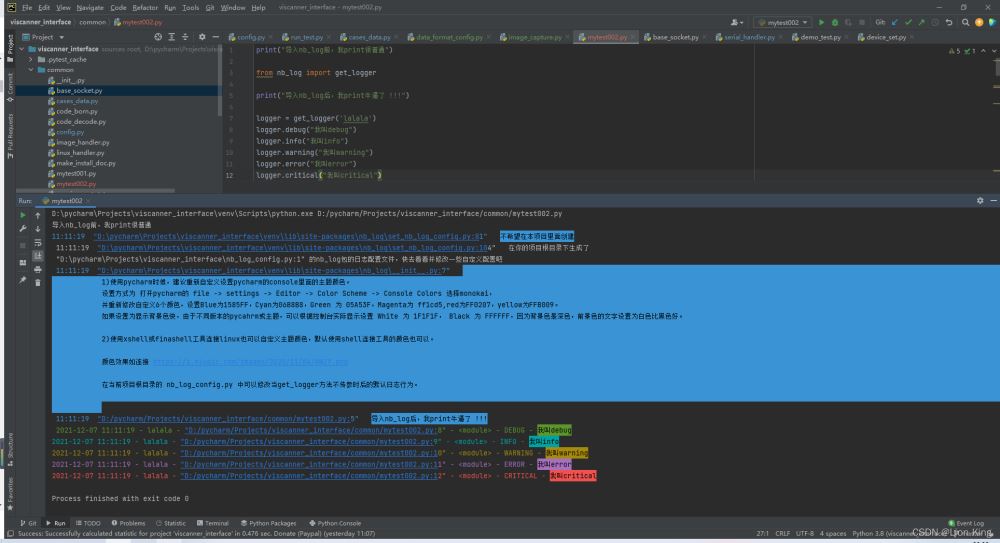
3、屏幕流日志效果
print("导入nb_log前,我print很普通")
from nb_log import get_logger
print("导入nb_log后,我print牛逼了 !!!")
logger = get_logger('lalala')
logger.debug("我叫debug")
logger.info("我叫info")
logger.warning("我叫warning")
logger.error("我叫error")
logger.critical("我叫critical")
4、将日志写入文件
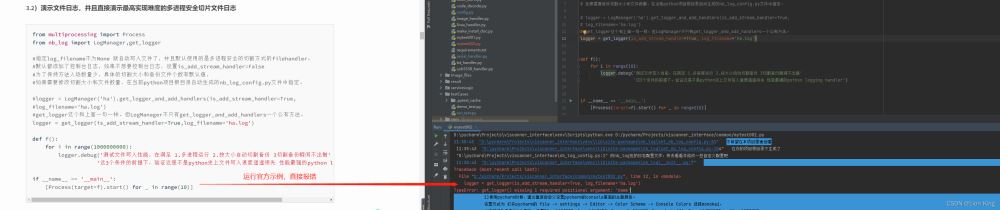
未避免错误,修改如下:
from multiprocessing import Process
from nb_log import LogManager, get_logger
# 指定log_filename不为None 就自动写入文件了,并且默认使用的是多进程安全的切割方式的filehandler。
# 默认都添加了控制台日志,如果不想要控制台日志,设置is_add_stream_handler=False
# 为了保持方法入场数量少,具体的切割大小和备份文件个数有默认值,
# 如果需要修改切割大小和文件数量,在当前python项目根目录自动生成的nb_log_config.py文件中指定。
# logger = LogManager('ha').get_logger_and_add_handlers(is_add_stream_handler=True,
# log_filename='ha.log')
# get_logger这个和上面一句一样。但LogManager不只有get_logger_and_add_handlers一个公有方法。
logger = get_logger(name="all_log", is_add_stream_handler=True, log_filename='ha.log')
def f():
for i in range(10):
logger.debug('测试文件写入性能,在满足 1.多进程运行 2.按大小自动切割备份 3切割备份瞬间不出错'
'这3个条件的前提下,验证这是不是python史上文件写入速度遥遥领先 性能最强的python logging handler')
if __name__ == '__main__':
[Process(target=f).start() for _ in range(10)]
运行之后,不太清楚文件去了哪里,尝试通过文件系统查找当前工程,也没有找到。从整个模块的使用来看,认为可能很牛逼,但无论是文档还是程序本身非常不规范!
查找全局才发现原来日志写到了这里:
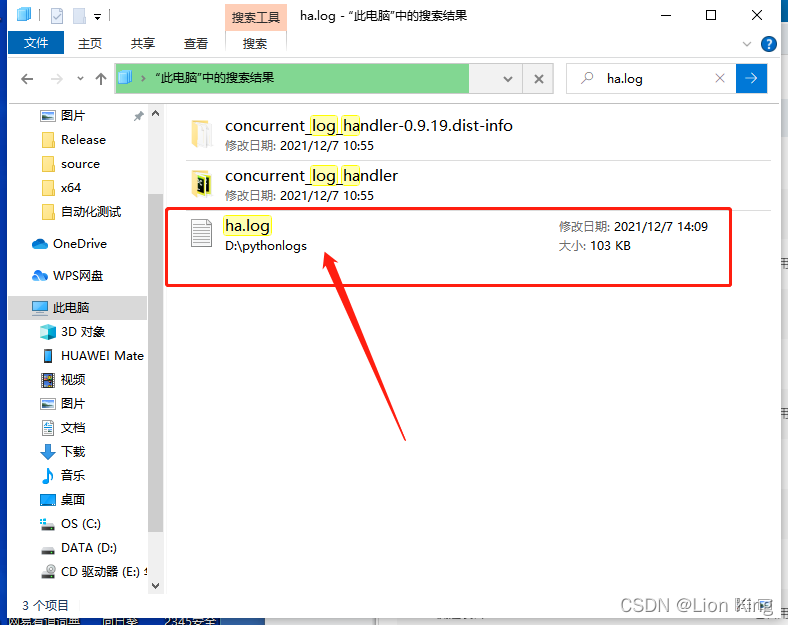
我猜测这个函数应该有路径输入,于是打了path,便可定义了,如下:
logger = get_logger(name="all_log", is_add_stream_handler=True, log_path="./", log_filename='ha.log')
5、总结
(1)模块能用,可能也好用,但建议先了解logging再使用
(2)个人维护,是否靠谱另说,但文档还不足够,也不规范,目前的版本是:nb-log 6.4
到此这篇关于python使用nb_log模块捕获日志的方法的文章就介绍到这了,更多相关python nb_log模块内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python logging模块的使用详解
logging日志模块:是用来记录日志的模块,一般记录用户在软件中的操作 使用方法:模板直接拿来用,手动修改 # logging的配置信息(模板) import os import logging.config # 定义三种日志输出格式 开始(模板,不用配置,直接拿来用) standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(lev
-

python使用nb_log模块捕获日志的方法
目录 一.调研日志模块 二.nb_log模块的使用 1.安装方式 2.自动跳转功能 3.屏幕流日志效果 4.将日志写入文件 5.总结 一.调研日志模块 我想写一个日志模块,首选是python内置的logging模块,接着查找外部的第三方模块,一眼看到我们中国人写的模块nb_log.估计是"牛逼的日志",这不得不说相当"严谨".倒也符合我的口味,pypi的地址如下: nb-log · PyPIvery sharp color display,monke
-
Python使用pymongo模块操作MongoDB的方法示例
本文实例讲述了Python使用pymongo模块操作MongoDB的方法.分享给大家供大家参考,具体如下: 通过pymongo实现python对Mongodb的操作. 具体看python代码 #!/usr/bin/python # coding=utf-8 #python实现对MongoDB的操作 #需要安装python2.pymongo.安装pymongo可能需要pip,logging打印日志 #改脚本主要功能就是每5秒改一次mongodb中存储的ip,5秒后再改回来 import pymon
-
Python记录详细调用堆栈日志的方法
本文实例讲述了Python记录详细调用堆栈日志的方法.分享给大家供大家参考.具体实现方法如下: import sys import os def detailtrace(info): retStr = "" curindex=0 f = sys._getframe() f = f.f_back # first frame is detailtrace, ignore it while hasattr(f, "f_code"): co = f.f_code retSt
-
python安装cx_Oracle模块常见问题与解决方法
本文实例讲述了python安装cx_Oracle模块常见问题与解决方法.分享给大家供大家参考,具体如下: 安装或使用cx_Oracle时,需要用到Oracel的链接库,如libclntsh.so.10.1,否则会有各种各样的错误信息. 安装Oracle Instant Client就可得到这个链接库,避免安装几百兆之巨的Oracle Client. 软件下载地址: cx_Oracle的主页:http://cx-oracle.sourceforge.net/ 必需的Oracle链接库的下载地址:h
-
Python基于pygame模块播放MP3的方法示例
本文实例讲述了Python基于pygame模块播放MP3的方法.分享给大家供大家参考,具体如下: 安装pygame(可参考:安装Python和pygame及相应的环境变量配置) pip安装这个whl文件 装完就直接跑代码啦,很短的 import time import pygame file=r'C:\Users\chan\Desktop\Adele - All I Ask.mp3' pygame.mixer.init() print("播放音乐1") track = pygame.m
-
Python的SimpleHTTPServer模块用处及使用方法简介
搭建FTP,或者是搭建网络文件系统,这些方法都能够实现Linux的目录共享.但是FTP和网络文件系统的功能都过于强大,因此它们都有一些不够方便的地方.比如你想快速共享Linux系统的某个目录给整个项目团队,还想在一分钟内做到,怎么办? 很简单,使用SimpleHTTPServer. 各种Linux发行版通常都内置了Python,故使用此方法非常方便.在其它OS(比如Windows)此方法也有效,但是要麻烦一些,必须先搭建Python环境. SimpleHTTPServer是Python 2自带的
-
Python使用xlwt模块操作Excel的方法详解
本文实例讲述了Python使用xlwt模块操作Excel的方法.分享给大家供大家参考,具体如下: 部分摘自官网文档. 该模块安装很简单 $ pip install xlwt 先来个简单的例子: #!/usr/bin/python #coding=utf-8 # ============================================================================== # # Filename: demo.py # Description: exc
-
Python使用ConfigParser模块操作配置文件的方法
本文实例讲述了Python使用ConfigParser模块操作配置文件的方法.分享给大家供大家参考,具体如下: 一.简介 用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser. 二.配置文件格式 [DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecr
-
Python基于xlrd模块操作Excel的方法示例
本文实例讲述了Python基于xlrd模块操作Excel的方法.分享给大家供大家参考,具体如下: 一.使用xlrd读取excel 1.xlrd的安装: pip install xlrd==0.9.4 2.基本操作示例: #coding: utf-8 import xlrd #导入xlrd模块 xlsfile=r"D:\workspace\host.xls" #获得excel的book对象 book = xlrd.open_workbook(filename=None, file_con
-
Python 解析pymysql模块操作数据库的方法
pymysql 是 python 用来操作MySQL的第三方库,下面具体介绍和使用该库的基本方法. 1.建立数据库连接 通过 connect 函数中 parameter 参数 建立连接,连接成功返回Connection对象 import pymysql #建立数据库连接 connection = pymysql.connect(host = 'localhost', user = 'root', password = '123456', database = 'mydb', charset =